谷歌Bard被曝直接抄ChatGPT数据,BERT一作投诉CEO后投奔OpenAI
网友:得,彻底成配角了
明敏 鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
谷歌这回,可真是出大糗了。
Bard处处不及ChatGPT也就罢了,如今竟然被曝出,为了快速训练这个ChatGPT竞品,他们直接使用了ChatGPT生成的数据。。。
数据来自于一个收集ChatGPT对话的公开网站,上面的对话数量超过11万。

The Information爆料,这种操作在谷歌内部不是没人反对。BERT一作就直接向劈柴哥等高管发出警告,并且明确提示:
这种行为违反了OpenAI的服务条款,并且会让Bard的回答和ChatGPT非常相似。
此后,这位大佬迅速从谷歌离职,转投OpenAI。
ShareGPT网站的作者,也佐证了这个消息:“我知道这事儿有一阵子了。”
并且正因为此,ShareGPT上周关闭了浏览他人聊天记录的探索功能。

这一锤下来,吃瓜网友当场坐不住了,有人直言谷歌这是犯了大忌。

还有人嘲讽,这下谷歌完全成了OpenAI的陪衬。

而谷歌这边,也立马被炸了出来,紧急否认三连:
Bard没有用任何来自ShareGPT或者ChatGPT的数据训练。
Bard自己承认“浏览过”ShareGPT
但谷歌用ShareGPT数据训练Bard这事儿吧,多少是有迹可循。
比如在上周,ShareGPT突然关闭了浏览他人ChatGPT对话的功能。
ShareGPT本来是一个谷歌插件,能方便人们一键分享自己和ChatGPT的对话到各种平台。之后开发者又进一步推出了一个探索页面,可以方便大家互相浏览有趣的对话,因此也成为了一个海量ChatGPT数据的聚集地。
随着The Information的爆料不胫而走,ShareGPT的开发者也公开喊话:
秘密终究还是藏不住了吧!

再来看谷歌这边的回应,比较因吹斯听。
虽然他们否认使用过ShareGPT或ChatGPT的任何数据。但在The Verge追问之前是否使用过ChatGPT数据做训练时,发言人拒绝回答并表示:
很抱歉我能分享的只有我们昨天的声明。

有消息人士说,在BERT一作雅各布·德福林(Jacob Devlin)和谷歌高管发出警告后,谷歌确实停止使用ChatGPT数据训练了。
由此The Verge猜测,Bard里或许已经删掉了之前这部分训练数据。
而如果把这个问题直接抛给Bard本身,它的回答同样引人深思。
因为它否认使用过ChatGPT的数据。
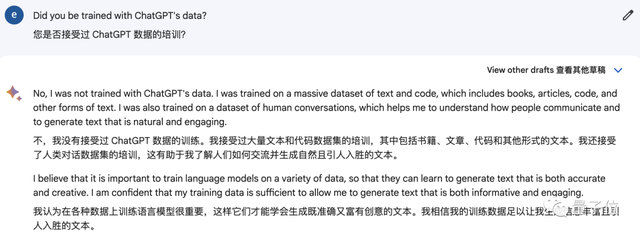
但承认读过ShareGPT的对话……

反倒是ChatGPT这边的回答很谨慎体面,表示除非“谷歌官方或相关研究人员明确承认了”,否则它没法作答。

实际上,OpenAI对于能否使用ChatGPT输出数据做训练这件事,有明确的条款说明:
竞品,不行。

但如果是非商用的,比如斯坦福大学发布的对话模型Alpaca,应该可以。
在Alpaca发布时明确提到,团队是通过购买OpenAI的API来生成数据集。
由此也就不难理解为啥BERT一作雅各布老哥,当初知道谷歌操作后反应如此激烈,甚至直接跑去和劈柴哥发出警告,毕竟这可是明目张胆地违反友商条例。
更何况这么做对Bard也不是没有坏处,会导致它生成的答案和ChatGPT非常相似……
而在给谷歌“吹哨”后,雅各布选择了马上提桶跑路转投OpenAI。1月份离职,都没等Bard发布。

不过这还没完,谷歌的操作还在继续——
因为他们居然和DeepMind“一笑泯恩仇”,联手开发新的大模型来应对ChatGPT了。
要知道,虽然DeepMind从2014年就被谷歌收购了,但它一直都保持高度独立运营,和谷歌的开发团队时常保持着竞争关系。
但在ChatGPT热潮下,谷歌和DeepMind如今的局面都颇为被动。
由此也就看到了这次罕见联手,DeepMind和谷歌大脑团队合作,共同开发一个名为Gemini(双子座)的大模型。
据悉,这个模型对标GPT-4,参数量大约在1万亿左右。谷歌大脑负责人Jeff Dean领衔技术开发,负责代码编写等工作。
网友:暂停大模型研究6个月根本不可能
谷歌这一波操作下来,外界也有些目瞪狗呆。
就有网友提出:Gemini的出现,是不是意味着谷歌已经放弃Bard了?

放不放弃不好说,但至少,谷歌内部的“赛马”已现端倪。
事实上,Gemini的消息传出之前,在2月份ChatGPT掀起第一波高潮之时,谷歌和DeepMind就已有联手动作:
谷歌旗下专注语言大模型的“蓝移团队”(Blueshift Team)宣布,整体并入DeepMind。目标就是追赶ChatGPT的进度。
此前,谷歌的5400亿参数大模型PaLM背后,就有蓝移团队成员的贡献。谷歌耗时2年发布的大模型基准BIG-Bench,也有蓝移团队的深度参与。
另外,DeepMind还手握另一张名为“Sparrow”的牌。
这一聊天机器人在去年9月就吸引了外界的关注,有评价认为它“朝创建更安全、偏差更小的机器学习系统迈出了重要一步”。
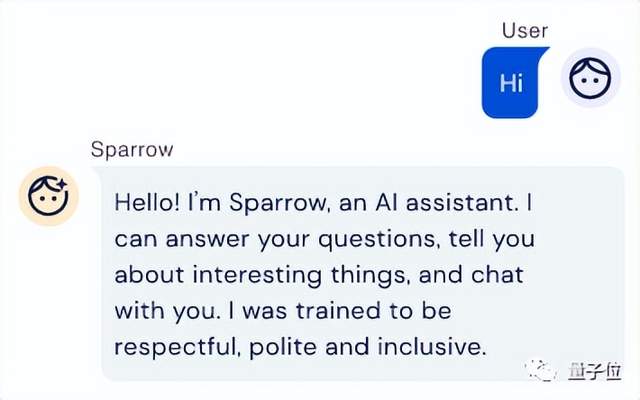
但当时,DeepMind出于对公共安全的顾虑,并未面向公众发布Sparrow。
论文的主要作者Geoffrey Irving当时解释说:
我们没有部署该系统,因为我们认为它还存在很多类型的偏见和缺陷。
问题在于,你如何权衡机器与人沟通的优势和劣势。我倾向于认为安全更为重要……从长远来看,我认为这是一种工具。
在ChatGPT发布并引起广泛讨论之后,据英国《独立报》消息,DeepMind的CEO哈萨比斯(Demis Hassabis)透露,Sparrow的内测版会在2023年年内推出。
种种迹象,让网友不由感慨:什么先进大模型“暂停六个月”,都是没谱的事儿。

开弓没有回头箭,尤其对于在这一波浪潮中处处落于下风的谷歌而言,显然没有停下脚步的理由。
毕竟,用户是真的在流失。Similarweb的数据显示,在过去近一个月时间里,新必应的页面访问量增长了13.6%,谷歌搜索的访问量则下跌了2.8%。

而谁也不想做下一个黑莓。
你觉得呢?
参考链接:
[1]https://www.theverge.com/2023/3/29/23662621/google-bard-chatgpt-sharegpt-training-denies
[2]https://twitter.com/amir/status/1641219919202361344
[3]https://twitter.com/steventey/status/1641267979399704576
— 完 —
- 粉笔CTO:大模型打破教育「不可能三角」,因材施教真正成为可能|中国AIGC产业峰会2025-04-18
- GPT-4.1淘汰了4.5!全系列百万上下文,主打一个性价比2025-04-15
- SOTA自动绑骨开源框架来了!3D版DeepSeek开源月大礼包持续开箱ing2025-04-11
- 语音界Deepseek!百度最新跨模态端到端语音交互,成本最高降90%2025-04-02