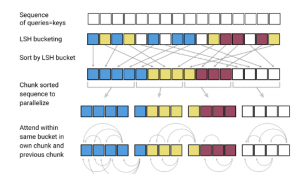
学完这个教程,小白也能构建Transformer,DeepMind科学家推荐
从视觉化矩阵乘法教起
Pine 发自 凹非寺
量子位 | 公众号 QbitAI
真正零门槛!小白都能轻松看懂的Transformer教程来了。
在自然语言处理和计算机视觉领域,Transformer先后替代了RNN、CNN的地位成为首选模型,最近爆火的ChatGPT也都是基于这个模型。
换言之,想进入机器学习的领域,就必须得懂Transformer。
这不,量子位就发现了一篇零基础也能学的教程,作者是前微软、Facebook首席数据科学家,也是MIT机械工程的硕博士,从视觉化矩阵乘法开始,带你一步步入门。
DeepMind研究科学家Andrew Trask也转发评论道:
这是我至今见过最好的教程,它对入门者非常非常友好。
这条帖子也是掀起了一阵热度,浏览量已经有近30w。
网友们也纷纷在评论区作出“码住”状。
从视觉化矩阵乘法开始学
因为这是一个新手入门的教程,所以在正式学Transformer之前,会有很多介绍矩阵乘法和反向传播的内容。
并且在介绍的过程中,作者逐个添加学习Transforme所需要了解的概念,并加以解释。
具体有多新手友好,我们先来浅看下这篇教程~
基础概念解释
首先,了解Transformer的第一步就是编码,就是把所有的单词转换成数字,进而可以进行数学计算。
一般来说,将符号转换为数字的有效方法是先对所有单词符号分配数字,每个单词符号都会对应一个独立的数字,然后单词组成的句子便可以通过数字序列来表示了。
举个简单的例子,比如files=1、find=2和my=3。然后,句子“ Find my files”可以表示为数字序列[2,3,1]。
不过这里介绍的是另外一种方法,即独热编码。
具体来说,就是将单词符号转换成一个数组,这个数组中只能有一个1,其他全为0。还是上面那个例子,用这种方式表示的话如下图。
这样一来,句子“Find my files”就变成了一维数组的序列,压缩到一块也就像是二维数组了。
接下来就要再来了解下点积和矩阵乘法了。
点积这里也就不再过多赘述,元素相乘再相加便可以了。
它有两个作用,一个是用来度量两个单词之间的相似性,一个是显示单词的表示强度。
相似性很容易判别,一个单词的独热矢量和自己的点积是1,和其他的点积为0.
至于表示强度,和一个能够表示不同权重的值向量进行点乘便可以了。
矩阵乘法,看下面这幅图便足矣。
从简单的序列模型开始介绍
了解完这些基础概念之后,就要步入正轨了,开始学习Transformer是如何处理命令的。
还是用例子来解释,开发NLP计算机界面时,假设要处理3种不同的命令
- Show me my directories please.(请给我看看我的目录)
- Show me my files please.(请给我看看我的档案)
- Show me my photos please.(请给我看看我的照片)
可以用下面这个流程图(马尔可夫链)来表示,箭头上的数字表示下一个单词出现的概率。
接下来解释将马尔可夫链转换为矩阵形式了,如下图。
每一列代表一个单词,并且每一列中的数字代表这个单词会出现的概率。
因为概率和总是为1,所以每行的数字相加都为1。
以my为例,要想知道它的下一个单词的概率,可以创建一个my的独热向量,乘上面的转移矩阵便能得出了
再然后,作者又详细介绍了二阶序列模型,带跳跃的二阶序列模型,掩码。
至此,关于Transformer,已经学到了最核心的部分,至少已经了解了在解码时,Transformer是如何做的。
不过了解Transformer工作的原理和重新建造Transformer模型之间还是有很大差距的,后者还得考虑到实际情况。
因此教程中还进一步展开,作了更大篇幅的学习教程,包括Transformer最重要的注意力机制。
换句话说,这个教程就是从最基础的东西教我们重新构建一个Transformer模型。
更加具体内容就不在这里一一列出了,感兴趣的朋友可以戳文末链接学习。
目录先放在这里,可以根据自己的基础知识选择从哪个阶段开始学起:
1、独热(one-hot)编码
2、点积
3、矩阵乘法
4、矩阵乘法查表
5、一阶序列模型
6、二阶序列模型
7、带跳跃的二阶序列模型
—-分割线—-(学完上面这些,就已经把握住Transformer的精髓了,不过要想知道Transformer,还得往下看)
8、矩阵乘法中的注意力
9、二阶矩阵乘法序列模型
10、完成序列
11、嵌入
12、位置编码
13、解除嵌入
14、softmax函数
15、多头注意力机制
16、使用多头注意力机制的原因
17、重现单头注意力机制
18、多头注意力块之间的跳过连接
19、横向规范化(Layer normalization)
20、多注意力层
21、解码器堆栈
22、编码器堆栈
23、编码器和解码器栈之间的交叉注意块
—-又一个分割线—-(如果你学到这里,那说明Transformer你已经掌握得差不多了,后面讲的东西就是关于如何让神经网络表现良好了)
24、字节对编码(Byte pair encoding)
作者介绍
Brandon Rohrer,目前是Linkedin的一名机器学习工程师,曾先后在微软,Facebook担任首席数据科学家。
在Facebook工作期间,他建立了一种更精确的电网映射预测模型,以评估全球的中压电网的连通性和路由。
写教程算是Brandon的一大爱好了,目前他所有的教程都不断更新在他的新书《如何训练你的机器人》中,帖子的跨度从职业发展到各种编程工具的介绍。
传送门:
https://e2eml.school/transformers.html#softmax
更多教程:
https://e2eml.school/blog.html
- GPT-5不能停!吴恩达田渊栋反对千人联名,OpenAI CEO也发声了2023-03-30
- ChatGPT标注数据比人类便宜20倍,80%任务上占优势 | 苏黎世大学2023-03-29
- 马斯克嘲讽比尔盖茨不懂AI/ 苹果收购AI视频公司/ 壁仞GPU联创出走…今日更多新鲜事在此2023-03-28
- GPT-4老板:AI可能会杀死人类,已经出现我们无法解释的推理能力2023-03-28