谷歌推出深度学习调优手册,不到一天狂揽1200星,Hinton转发
5位大佬工程师合写
丰色 Pine 发自 凹非寺
量子位 | 公众号 QbitAI
各位炼丹er们,调参是你们最头疼的环节吗?
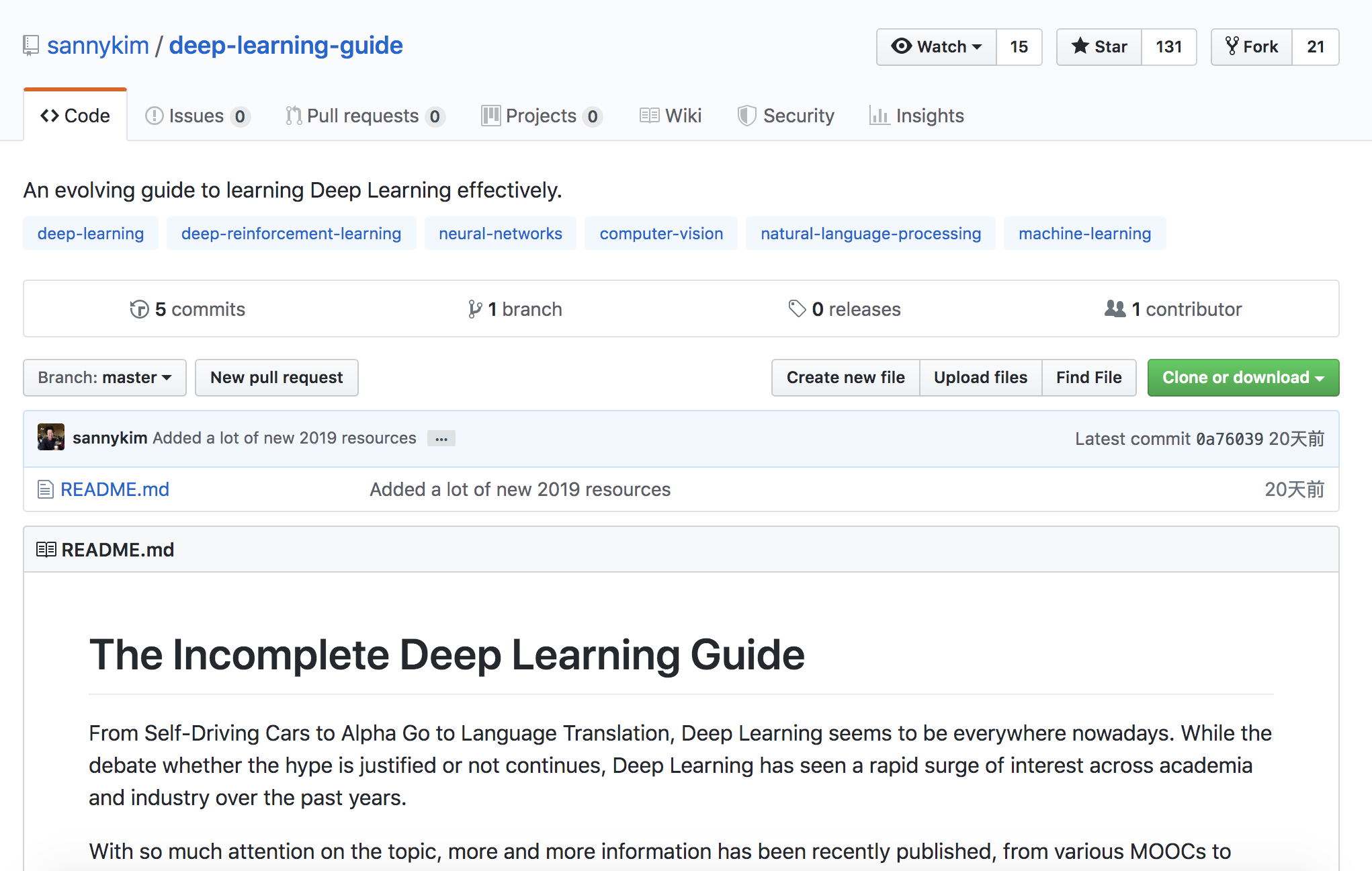
现在,一份上线不到一天就狂揽1200+星的《深度学习调优手册》来了。
△数字还在飞速上涨,估计马上就要登热榜了
这可能是市面上首个如此全面的炼丹宝典,由5位谷歌工程师大佬合作总结。
这些大佬们都已在深度学习领域“踩坑”多年、工作成果应用从语音识别到天文学都有涉猎。
为了这份手册,他们总结了自己在训练网络、带新工程师、以及和同事交流时get到的各种经验和技巧。
连“深度学习之父”Geoffrey Hinton都来盛赞:
来看看具体都有些啥。
谷歌炼丹宝典,聚焦超参数调整
本手册适用范围为:对系统地最大化深度学习模型性能感兴趣的工程师和研究人员,包括个人和团队。
默认翻开这本手册的都掌握了机器学习基本知识和深度学习概念。
其中内容主要聚焦超参数调整,因为这是作者们在工作中耗时最多、收获也最多的环节。
具体一共分为四大部分:
开始新项目
第一部分从训练一个新的模型开始,教大家如何选择:
(1)模型架构(2)优化器(3)batch size(4)初始配置。
比如,在选择优化器时,由于所有类型的机器学习问题和模型架构中都不存在最好的那一个,那么我们就坚持选择时下最流行、最成熟的那一个(尤其对于新项目来说)。
这里作者们推荐(但不限于):SGDM和更通用的Adam、NAdam,特别提醒:Adam有4个可调超参数 ,它们都很重要。
而在选择batch size时,需要注意它只是决定训练速度,不应该直接用于调整验证集的性能。
因为有研究表明,只要所有超参数都经过良好调整(尤其是学习率和正则化超参数)并且训练步数足够,任何batch size值都应该可以获得相同的性能。
通常来说,理想的batch size是可用硬件支持的最大值。
具体如何选择,手册在这里作出了非常详细的解释:
初始配置方面,指导原则是找到一个简单、相对快速、资源消耗相对较低的配置,好获得一个“合理”的结果。
所谓简单,就是切记不要在开始时就添加一些花里胡哨的东西,现阶段没用不说还浪费时间。
比如在找到一个合适的学习率之前,就不要想着各种花式的decay schedule。
科学提高模型性能
本部分的经验建立以下两点前提之上:
- 我们已经有一个完全运行的训练pipeline以及能够获得合理结果的配置;
- 有足够的计算资源用于进行有意义的调整实验、用于并行运行多个训练项目。
具体一共分为7个小部分:
第1部分标题为“逐步调整策略”,即从一个简单的配置开始,逐步进行改进,需要重复以下四个步骤:
- 为下一轮实验确定范围适当的目标;
- 设计并运行实验,朝着目标取得进展;
- 分析结果;
- 考虑是否推出新的最佳配置。
后续部分就是围绕上面四个步骤进行详细的展开,超参数如何选择和修改也在本节作为重点出现。
比如不管我们的实验目标是什么,我们都需要将超参数分为三类:科学超参数、nuisance超参数和固定超参数。
如果我们的目标是“确定具有更多隐藏层(hidden layer)的模型是否会减少验证错误”,那么隐藏层数就是一个科学超参数,这是我们在设计新实验时需要首先确定的。
需要修改的主要是第二类。
当我们进行到第三步,也就是分析结果时,需要额外问自己以下几个问题:
搜索空间是否足够大?是否从里面采样了足够多的点?该模型是否存在优化问题?我们可以从最佳试验的训练曲线中学到什么?
具体怎么判断和解决这些问题,手册也有非常详细的解释。
最后,当我们确定好了应该调整哪些超参数,就可以善用贝叶斯优化工具了。
不同工作负载如何设置训练步数
在这部分,手册根据工作负载的不同分了两部分来展开,分别为:
- 工作负载为计算密集型(CPU密集型)时,训练步数如何设置?
- 工作负载为非计算密集型(IO密集型)时,训练步数如何设置?
通俗来讲,计算密集型与非计算密集型就是受不受计算量的限制。而我们要解决的问题,就是无论在哪种情况下,如何让模型都能达到最佳效果。
也不多说废话,直接举个栗子来看宝典中是如何讲的?
当工作负载受计算限制时,也就是说计算资源成为主要的限制因素,首先面临的问题就是:
如果训练损失在无限期的改善,有没有必要这样一直训练下去?
宝典给出的答案是:没有! 多轮调整最明智,1~3轮最实用。
并且还附有两轮调整的具体建议:
- 第1轮:较短的运行时间以找到好的模型和优化器超参数
- 第2轮:不要在良好的超参数点上长时间运行以获得最终模型
(详见手册)
关于当工作负载不受计算限制时,调整的部分主要围绕max_train_steps,具体这里就不再赘述。
其他补充
到这里,宝典差不多就接近尾声了,谷歌研究员们还贴心地给出了一份pipeline训练的补充指南,内容包括:
- 优化输入pipeline
- 评估模型性能
- 保存检查点并回顾性地选择最佳检查点
- 建立实验跟踪
- Batch规范化实现细节
- multi-host pipelines的注意事项
在“优化输入pipeline”部分,宝典列出了导致输入pipeline的一些常见原因,并给出了一些小tips。
关于“评估模型性能”,也给出了详细的操作步骤。
……
宝典全文的链接也已附在文末,感兴趣的朋友可以扔进收藏夹了。
mem it~
关于作者
一共4位谷歌在职大佬,1位哈佛的在读博士生(以前也在谷歌工作了5年多)。
Varun Godbole,目前是谷歌AI的一名软件工程师,主要经验集中在建模和构建处理大型数据集的基础设施方面。
之前,他的研究领域是计算机视觉和医学图像的交叉点,合著的论文“International evaluation of an AI system for breast cancer screening”曾登上Nature。
George E. Dahl,是谷歌大脑团队的研究科学家,他的研究集中在高度灵活的模型上,并且他还对语言、感知数据以及化学、生物和医学数据的应用感兴趣。
George在多伦多大学攻读博士学位时,主要解决语音识别、计算化学和自然语言文本处理等问题的深度学习方法,其中包括一些首次成功的深度声学模型。
Justin Gilmer,谷歌大脑的研究科学家,他在Google Scholar上引用已经破万,主要研究方向为深度学习、组合型、随机图论。
量子位前不久的《几十年数学难题被谷歌研究员意外突破!曾因不想搞数学自学编程,当年差点被导师赶出门》讲的正是这位科学家。
Christopher Shallue,目前正在攻读哈佛大学的天体物理学博士学位,在此之前,他曾在谷歌工作了5年10个月。
在谷歌工作的那段时间,Shallue有3年多的时间在谷歌大脑担任机器学习研究工程师,研究的内容包括:
- 开发识别系外行星的机器学习技术(包括神经网络首次发现行星)
- 加快超级计算机规模的机器学习培训
- 实证研究机器学习中的优化算法和超参数调整
- TensorFlow 中的开源参考模型实现(图像字幕、句子嵌入、系外行星探测)
Zachary Nado,谷歌大脑的研究工程师,本科就读期间,曾先后在谷歌和SpaceX实习,研究领域包括数据挖掘与建模、机器智能、NLP等。
宝典传送门:
https://github.com/google-research/tuning_playbook
- GPT-5不能停!吴恩达田渊栋反对千人联名,OpenAI CEO也发声了2023-03-30
- ChatGPT标注数据比人类便宜20倍,80%任务上占优势 | 苏黎世大学2023-03-29
- 马斯克嘲讽比尔盖茨不懂AI/ 苹果收购AI视频公司/ 壁仞GPU联创出走…今日更多新鲜事在此2023-03-28
- GPT-4老板:AI可能会杀死人类,已经出现我们无法解释的推理能力2023-03-28