
浪潮信息刘军:智算力就是创新力 | MEET2023
AI领域的众多创新背后都离不开智算力的支撑
Pine 整理自 MEET2023
量子位 | 公众号 QbitAI
在人工智能的三驾马车中,算力作为算法和数据的支撑,它的作用一直都不容小觑。
目前,人工智能在和各个行业不断融合发展,这对算力也提出了更高的要求。
无论是AI大模型训练,自动驾驶系统的感知模型训练,还是AI+Science或者数字人的建模或渲染,都离不开强大算力的支撑。
在MEET2023智能未来大会上,浪潮信息副总裁、浪潮人工智能与高性能计算产品线总经理刘军分享了在AI新时代,他对智算算力的一些思考,并抛出了这样一个观点:
智算力就是创新力。

为了完整体现刘军的分享及思考,在不改变原意的基础上,量子位对他的演讲内容进行了编辑整理。
关于MEET 智能未来大会:MEET大会是由量子位主办的智能科技领域顶级商业峰会,致力于探讨前沿科技技术的落地与行业应用。今年共有数十家主流媒体及直播平台报道直播了MEET2023大会,吸引了超过300万行业用户线上参会,全网总曝光量累计超过2000万。
演讲要点
- 目前智算的发展有三个趋势:算力多元化、模型巨量化、元宇宙。
- 计算的目标是支撑业务,不同的业务类型对计算系统提出的需求也是不同的。
- AI算法正在从感知智能向认知智能迈进,模型参数持续增大,预训练算法要求也越来越高。
- 元宇宙的构建需要协同创建、高精仿真、实时渲染、智能交互四大环节,各个环节都会涉及到不同的计算类型。
(以下为刘军演讲全文)
智算力就是创新力
当今人工智能前沿领域的大模型,就是在智算算力驱动下重大创新的典型,比如GPT-3,浪潮“源1.0”等等。
为此,浪潮提出用“算力当量”来对AI任务所需算力总量进行度量,单位是PetaFlops/s-day也就是PD,即用每秒千万亿次的计算机完整运行一天消耗的算力总量(PD)作为度量单位。
一个任务需要多少PD的计算量,就把它视为这个任务的“算力当量”。
而现在人工智能的不断发展也对算力有了更高的要求,在各个领域均是如此,在这里举几个简单的例子:
首先是AI大模型训练方面,GPT-3等自然语言模型和DALL-E 2、stable diffusion等多模态模型训练都对算力有着非常高的需求,GPT-3的算力当量是3640个PD,源1.0作为2457亿的参数的大模型,它的算力当量是4095个PD。
再来讲讲元宇宙中数字人的建模和渲染,如果要创建一个栩栩如生的人物形象并对其进行渲染,以《阿丽塔:战斗天使》来举例,它平均每一帧需要花100个小时来渲染,总共这部影片的渲染计算使用了4.32亿小时的算力。
在自动驾驶领域,特斯拉创建了DOJO的智算系统,用于感知模型的训练和仿真。它的FSD全自动驾驶系统的融合感知模型,训练消耗的算力当量是500个PD。
在备受关注的AI+Science领域、蛋白质的结构预测、分子动力学的模拟、流体力学的仿真,它不仅融合了传统的HPC计算也融合了当今的AI计算。
比如说,经常被提及的AlphaFold2,它的训练消耗的算力当量是300个PD。与此同时,为AlphaFold2训练所做的数据准备,也需要花费200M CPU-hours HPC算力。

因此,我们可以确切地认识到,今天在AI领域的众多创新背后离不开智算力的支撑,可以说智算力就是创新力。
那么接下来就结合三个重要的趋势:算力多元化、模型巨量化以及元宇宙,谈一谈智算发展。

算力多元化
首先先来讲下算力多元化。这是在不同的业务类型对计算系统的不同要求下催生出的,也体现出了场景多样化。
换句话说,AI应用引入了新计算类型,从推理到训练,跨度更大,同时数据量级不断提升,类型也更加复杂多样。
当然,不同数值精度的计算类型对于芯片指令集、架构的要求是不一样的。
比如说,在超算里面可能会需要LP64双精度的计算,在AI的训练需要使用数字范围更大、精度低的16位浮点,在AI推理的场景可以使用到8位或者是4位的整点。
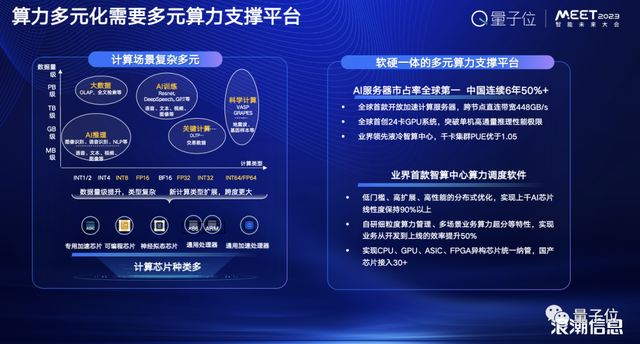
而要适应这些计算的特点,就需要引入多元的算力芯片来进行支撑,而浪潮也从软件和硬件上两方面来应对多元算力的挑战。
首先是硬件上,为了更好地推动多元算力部署应用、促进AI算力生态健康发展,浪潮开发了软硬一体的多元算力支撑平台:浪潮AI服务器。
它采用高带宽、全互联的拓扑构架、开放的硬件标准,支持8颗500W液冷开放加速芯片, 单集群可提供超过200PFLOPS峰值AI算力。
目前已兼容燧原、壁仞等多家高端AI算力芯片;基于这款服务器浪潮还与燧原科技联合开发了千卡级液冷智算中心产品——“钱塘江”,整体PUE实测值优于1.05,能效比业界领先。
并且, “钱塘江”还搭载了浪潮AIStation智能业务创新生产平台,“源”巨量模型算法能力,构成领先的算力算法一体化智算中心解决方案。
再来看看软件方面,除了AI服务器之外,浪潮还开发了业界首款智算中心算力调度软件:AIStation,将异构AI芯片管理进行标准化与流程化。
从基本的接入适配到业务应用在异构算力的使用优化,AIStation提供了完备的工具与解决方案,与传统开源方案相比,芯片接入稳定性方面提升30%,减少接入工作量90%以上。
在大型智算中心项目上,AIStation能够稳定高效的管理2000+异构AI芯片,支持上千户同时在线开发,满足多场景算法研发和大规模算力需求。
AIStation通过自研的算力调度系统,实现降低接入成本50%,整理资源利用率提升30%,管理效率提升50%以上,还让算力使用更便捷、更高效,降低AI开发与部署对异构算力使用的门槛,实现真正的算力普惠。

不仅如此,在实践方面,浪潮也在不断探索,依托于在AI服务器、AI软件等方面的技术创新,目前宿州市与浪潮达成战略合作,共同建设多元算力智算中心——淮海智算中心。
智算中心非常好地结合了GPU的算力芯片和国内的AI智算芯片,通过AIStation系统实现了混合算力的调度。
它采用通用GPU可提供FP64双精度、FP32单精度,FP16半精度及INT8整形等多种精度算力,支持专用的深度学习张量加速单元Tensorcore,比传统计算单元算力提升十倍以上。
并且还支持国内外主流的深度学习的框架、数学库、数据集降低用户的学习成本。
此外,智算中心还采用MLU370-M8芯片,采用先进的OAM芯片间高速互联架构,提供国内唯一一个能支持八颗国内高端AI芯片高速互联的的平台系统,AI芯片间的高速互联有利于提升大规模分布式训练的性能。

模型巨量化
然后是模型巨量化,目前在AI算法方面,一个明显的趋势就是在从感知智能向认知智能迈进,AI模型从“能听会看”逐步走向“能思考,会创作”,甚至推理、决策的层面。
模型巨量化也就是通常所说的大模型,大模型正在成为AIGC的算法引擎,无论是DALL-E,还是今年爆火的Stable Diffusion,它们背后都是大模型在驱动。
大模型使得我们今天能够从AI五年前的能听会看走到今天能思考、会创作,下一步它也即将朝着会推理、能决策发展。
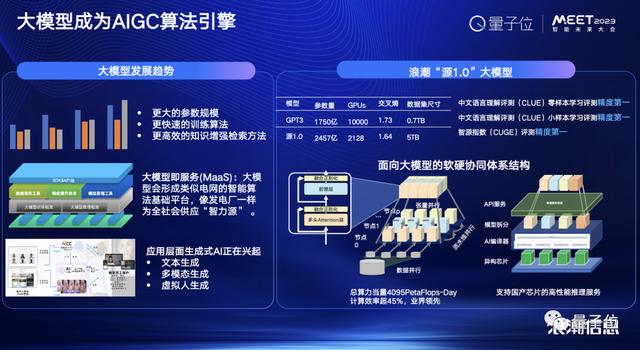
不过大模型在算力方面也面临着巨大的挑战:如何能够把大模型的能力交付到众多的中小的企业,帮助他们实现智能化的转型?
在这方面,浪潮认为Model as a service(MaaS)是比较好的一种方式。
在大模型能力的加持下,目前的AIGC,比如文本的生成、文生图以及虚拟数字人等应用都会迅速进入到商业化阶段。
就拿浪潮去年推出的源1.0来说,它是面向中文语言的拥有2457亿参数的巨量模型。
在算力这一块儿,浪潮做了大量深入的优化,实现了数据并行、流水线并行以及在算力的效率层面达到了45%的算力利用率。
也就是说,这已经遥遥领先于GPT-3,包括一些像megatron的大型训练的模型。
与此同时,源1.0还通过对推理框架的优化,现在已经实现了对多款AI芯片的支持。
这么强大的算力具体在源1.0上是怎么体现的?举几个简单的例子。
第一个是基于源1.0构建的AI剧本杀,在给定的背景和场景下,让AI与人进行多轮开放式对话,不但需要AI能够创造性思考,理解人的情感,甚至还需要有策略地与人博弈,影响对话走向。
这款AI剧本杀最后展现出来的效果也很强大,玩家很难感受到这是一个AI的玩家在和他一起玩剧本杀,因为它在这里面所表现出来的引导能力、情景化的理解能力是我们在传统的AI算法上面很难见到的。
这个项目已经在GitHub上开源,感兴趣的话可以查看。
第二个案例是,上海一个开发者的群体基于源1.0构建了数字社区助理,换句话说,就是打造了一个教练来提升居委会社区工作者应对居民的突发状况服务的能力。
同时这也开启了一个新的想象空间,也就是新的教培领域的产业。

还有一个案例就是基于源1.0的公文写作助手,最近AIGC领域备受热议的当属ChatGPT了,也不用多做解释,简单来说它就是基于大模型的一个AIGC面向长文本、多轮对话的应用。
而浪潮的公文写作助手也是生成文本的AI,专门面向公文写作场景,通过在高质量公文数据上进行知识蒸馏,构建的公文写作技能模型可支持总结报告、学习心得等内容辅助写作。
最终可实现从语义到段落级、篇章级文本生成和优化,辅助文字工作者打造高质量文案。
目前这个AI还处于内测阶段,欢迎大家来申请使用。
除了上面说的那些具体应用之外,浪潮也把这样的大模型应用在自身业务上面,以实现自身业务智能化的转型。
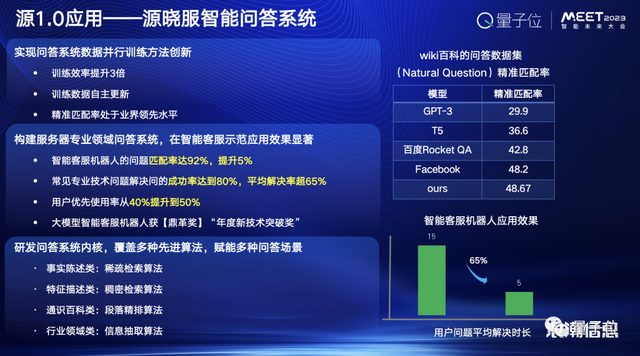
作为中国最大、全球第二的服务器的厂商,浪潮构建了一个基于源1.0的庞大的客户服务系统,并且不同于传统的智能化客服的问答系统,浪潮的系统可以进行长文本的内容生成,能够持续的进行多轮的对话。
更重要的是它不仅仅基于一个知识的规则去构建问答系统,还可以自己去主动阅读全球所有和服务器相关的产品文档。
可以说这个系统是真正的服务器“服务大佬”,在它的支撑下,客户的支持效率得到了大幅的提升,它也荣获了《哈佛商业评论》年度新技术突破奖这样一个顶格奖。
元宇宙需要强大算力支撑
最后一个再来说说元宇宙,先抛出一个问题,大家觉得元宇宙需要算力吗?
答案是不仅需要,而且是非常需要!元宇宙的构建包括协同创建、高精仿真、实时渲染、智能交互四大环节,这其中每个环节都涉及到不同的计算类型,需要大量的算力去支撑。

比如说在协同创建阶段,会涉及到多个3D软件的协同,这时便需要桌面虚拟化来给建模工程师提供工作界面。
在高精仿真阶段,需要进行元宇宙场景的物理仿真,既有传统的基于HPC的仿真软件,也有基于AI的仿真算法。同时也会涉及到对仿真结果的可视化展示。
对于元宇宙来说,3D场景的实施渲染是必不可少的,因此像光线追踪,路径追踪等前沿的图像渲染算法,和DLSS等基于AI的算法,也是必不可少的。
最后,人工智能计算在元宇宙的智能交互环节会有很多应用。比如数字人和环境的交互会涉及到ASR、TTS、NLP等多种AI算法。
如此种种都对算力基础设施提出更高的要求,不仅仅要求高性能、低延迟、易扩展的硬件平台,还要求有端到端、生态丰富、易用的软件栈。
在此,浪潮推出了元宇宙服务器MetaEngine,旨在打造支撑元宇宙的软硬一体化算力基础设施。
在硬件上,采用浪潮领先的异构加速服务器的旗舰系统,支持最先进的CPU和GPU,具有强大的RDMA通信和数据存储能力,可提供强大的渲染和AI计算能力。
在软件上,MetaEngine可以支持对应每个作业环节的各类专业软件工具,用户可以根据使用习惯灵活选择,同时它还可以系统全面支持Nvidia Omniverse Enterprise。
当前MetaEngine可实现每秒AIGC 2000+场景,支持1000+XR用户同时接入,共享10K超高清3D数字世界顺畅体验。
当然在具体的实践方面,浪潮也稳步前进,为了推动了元宇宙的快速落地,上个月青田人民政府和浪潮信息,谷梵科技一起签约建设国内首个元宇宙算力中心。
这个元宇宙算力中心用于支撑在青田、浙江乃至于长三角在元宇宙的数字空间创建、数字产业发展,支撑数字经济、数实融合的发展。
谢谢大家!
(最后,如果想回看大会全程,请点击阅读原文)
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10











