
拒绝白嫖!Stable Diffusion新版:画师可自主选择作品是否加入训练集
计划推出画师删除选项
衡宇 发自 凹非寺
量子位 | 公众号 QbitAI
不希望自己作品被Stable Diffusion“白嫖”的画家们,可以松口气了!
Stable Diffusion 3.0版本将会提供一个选项:
艺术家们可以选择将自己的画作纳入Stable Diffusion 3的训练数据集,或从数据集中删掉。

据了解,未来几周内,这个操作就会被开启。
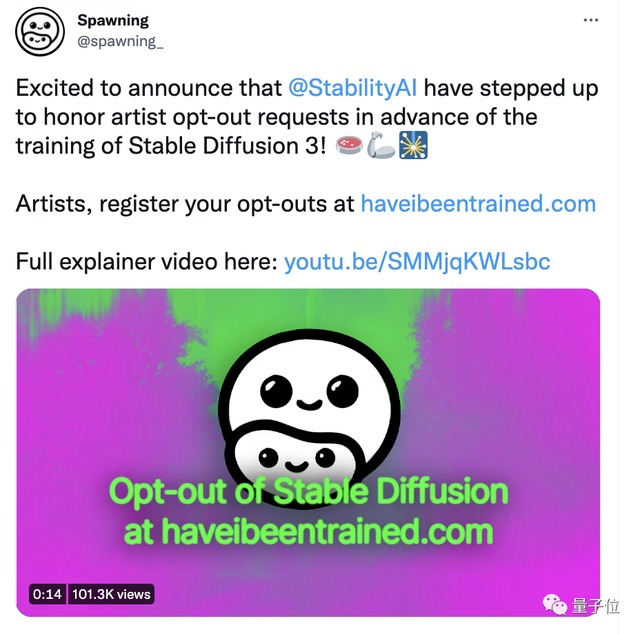
不过,承接这个任务的不是Stability AI本身,而是一个叫Spawning的艺术家倡导组织。
自由选择纳入或删除作品
选择在Stable Diffusion3中纳入或删除自己的作品,步骤十分简单。
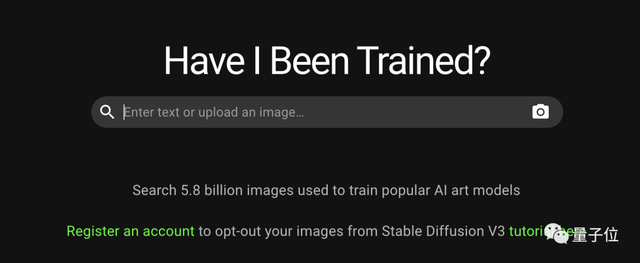
画师们只需要在网站“Have I Been Trained?”注册,并表明自己希望在训练数据集中删除或者纳入哪些自己的作品。
而后,Spawning会收集艺术家们在网站上的意向。
网站Have I Been Trained背后是LAION-5B训练数据集,它被用来训练Stable Diffusion和Google的Imagen AI等模型。
LAION是一个非营利性的开源数据集,Stability AI对其进行了部分资金资助。
具体操作是酱婶的:
首先需要在Have I Been Trained上注册一个账户,然后上传自己的画作。
利用LAION图像数据库,搜索引擎会显示出上传画作在数据库训练集中的匹配项。
这个时候,只需要分别右键单击几个缩略图,并在弹出选项中选择选择删除此图像即可。
所有退出数据集的图像,都会集中显示在一个“选择退出”的图像列表中。
当然,上述还只是进行操作的大概步骤,实施细节尚待完善。
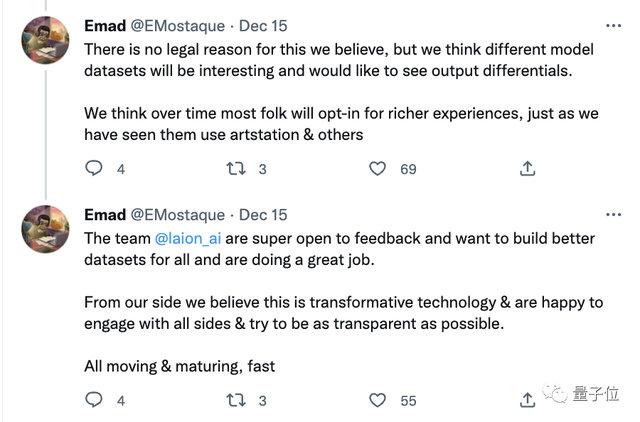
Stability AI创始人兼CEO Emad Mostaque在推特上表示,除了选择删除外,Spawning还将提供选择加入请求。
也就是说,希望自己作品成为训练集一部分的艺术家,同样可以把自己的画作添加到里面。
这位CEO在推特上还说了:
我们希望为大伙儿建立更好的数据集,相信这是一项变革性的技术。
我们乐意与各方接触,并尽可能做到透明。
承接数据收集工作的Spawning,是一个总部位于柏林的艺术家倡导组织。
它很年轻,今年9月刚刚创建创建,创始人是Dryhurst夫妇和一位音乐家。
Dryhurst表示,这三个月来,Spawning一直在和Stability AI和LAION进行洽谈,并得到了支持。
他还表示,Spwaning是一个独立组织,不会把收集来的数据拿去做任何别的事。
然而,人们对事情的担心并不局限在数据隐私上。

一个方面是,要从训练集中删除图像,前提是你想要删除的图像已经存在于LAION数据集中,且可以在Have I Been Trained上搜索到。
此外,目前没有办法选择批量删除图片,如果数据集中存在同一图像的多个副本,那么删除起来可是个费时费力的大工程。
而争议的目光最为聚集的一点,则是让艺术家们纷纷跑去注册一个和Stability AI或LAION没有法律约束的网站。
目前在Have I Been Trained完成“删除图像”的操作,整个流程可以说是畅通无阻。
没错,你既不会遇上任何试图验证身份的步骤,也不会遇上任何法律约束的条约。
也就是说,你想把别人的作品添加或从训练集中删除,轻而易举,完全不受阻碍。

△有人上传了一张版权不属于自己的图像,并将其从数据集中删除
以及,针对Spawning在其公告视频中关于同意的声明,有网友指出,选择退出过程不符合欧洲通用数据保护条例(GDPR)中关于“同意”的定义。
这份条例中规定,必须予以用户主动同意的权利,而不是默认同意了。
谁拥有AIGC作品版权?
有看客拥有更激烈一些的看法:
设置的选项,应该只有“要不要让自己的画作加入训练集”,而不是既有加入也有删除。
他们的观点是,所有的艺术作品都应该默认被AI训练集排除在外。
今年,AIGC的力量喷薄而出,席卷全球各行各业。
自DALL·E 2在4月发布以来,创意产业一直对AI艺术图像所有权的问题议论纷纷,尤其是画家本人,他们中不少都抱着饭碗对AIGC骂骂咧咧。

△DALL·E 2生成图像
等到开源的Stable Diffusion在8月发布时,有关模型训练的争议也越来越大。
用大量网络中真人画师的作品组成数据集,然后生成AI画作,被有的网友批判为“抄袭和偷窃”。
但是这样的“抄袭”很难衡量其频次,因为扩散系统是根据来自不同来源的数十亿张图像进行训练的。
而且,这样生成的作品,版权到底归属哪一方?
是被“学习”的画家,还是AI模型背后的公司,抑或是AI模型本身?
一切尚未有所定论。
前几天,马里兰大学和纽约大学的科学家们做了一项新研究,研究表明:
DALL·E2和Stable Diffusion这样的文生图AI模型,可以并且确实在从它们的训练数据集中,疯狂复制数据集图像的各个方面。
“使用扩散模型生成数据的公司,可能需要重新考虑涉及知识产权法的任何部分。”研究人员表示,“因为几乎没办法验证Stable Diffusion生成的任何图像,是不是全新的,或者有没有从训练数据集中窃取别人的成果。”

△Stable Diffusion 从其训练数据集中复制元素的更多示例(图源:TechCrunch)
研究表明,模型复制的频率取决于几个因素,包括训练数据集的大小,较小的集合往往比较大的集合导致更多的复制。
与此同时,一旦模型记住了原画作,就很难判定生成图像和原始图像之间的界限。
相似度达到多少,才能判定抄袭与否或版权归属何方呢?
研究人员也并没有给出答案,他们只是说:
我们不能抛弃扩散模型,应该考虑如何在不损害隐私的情况下保持它们的性能。
那么,有没有一种办法,让艺术家的版权受到保护需求,和AI生成技术继续进步达到微妙的平衡?
Stability AI承认,自家产品引发了对在线AI生成艺术的大规模道德辩论,其间主流还是抗议的声音。
不过,就让艺术家自动选择加入或删除图像这事儿,CEO同志Emad Mostaque毫不忌讳地表达了自己的开放态度。
他在推特上写道:
@laion_ai 团队对反馈有着非常开放的心态,我们的初心是希望为所有人构建更好的数据集。
那么,你是怎么看待AIGC生成作品版权归属的?
参考链接:
[1]https://venturebeat.com/ai/stability-ai-to-honor-artist-opt-out-requests-for-stable-diffusion-3/
[2]https://twitter.com/EMostaque
- 心影随形创始人刘斌新:做不跟用户抢时间的AI产品丨中国AIGC产业峰会2025-04-22
- 狸谱App负责人一休:从“叫爸爸”小游戏到百万月活AI爆款,社交传播有这些底层逻辑丨中国AIGC产业峰会2025-04-23
- 直观即时绘制3D模型,可添加文本提示,VAST又开源了2025-04-21
- LIama 4发布重夺开源第一!DeepSeek同等代码能力但参数减一半,一张H100就能跑,还有两万亿参数超大杯2025-04-06











