腾讯发布万亿大模型训练方法:最快256卡1天训完万亿NLP大模型
腾讯混元AI大模型详细技术解读
允中 发自 凹非寺
量子位 | 公众号 QbitAI
编者按:
万亿大模型的落地成本,被打下来了:
现在,最快用256张卡,1天内就能训练完成,成本直接降至原来的1/8。
这项最新进展,来自腾讯混元AI大模型。
这也是国内首个低成本、可落地的NLP万亿大模型。
具体技术详情,一起来看研究团队怎么说~

随着AI技术不断发展,AI大模型(又称预训练模型)逐渐成为产业中最火热的技术名词。
预训练模型是指预先训练好,具有相对通用性的“一套算法”,具有“巨量数据、巨量算力、巨量模型”等特性。大模型通过学习样本数据的内在规律和表达层次,进化出接近、超越人类的智能程度,具备分析推理能力,能够识别文字、图像和声音。
今年4月,腾讯首次对外披露混元AI大模型(下文简称“HunYuan”)研发进展。HunYuan集CV(计算机视觉)、NLP(自然语言理解)、多模态理解能力于一体,先后在MSR-VTT,MSVD等五大权威数据集榜单中登顶,实现跨模态领域的大满贯。今年5月,更是CLUE(中文语言理解评测集合)三个榜单同时登顶,一举打破三项纪录。
近日,HunYuan又迎来全新进展,推出国内首个低成本、可落地的NLP万亿大模型,并再次登顶自然语言理解任务榜单CLUE。
如此来势汹汹的HunYuan,是如何在短时间内完成性能迭代?落地到具体的应用场景是如何发挥其效能的呢?
我们一起来看看它背后的技术揭秘。
概述
预训练的提出使得人工智能进入全新的时代,引发了学术界和工业界的研究热潮。
随着算力的发展,模型容量持续提升,模型通用性和泛化能力也更强,研究大模型成为了近两年的趋势。国内外头部科技公司均有布局,发布了若干千亿规模以上的大模型。
然而,面对参数量进一步扩大,业界并没有在高速网络、训练/推理框架、模型算法和落地应用等方面有全面深入的公开性研究。
基于腾讯强大的底层算力和低成本高速网络基础设施,HunYuan依托腾讯领先的太极机器学习平台,推出了HunYuan-NLP 1T大模型并登顶国内最权威的自然语言理解任务榜单CLUE。
该模型作为业界首个可在工业界海量业务场景直接落地应用的万亿NLP大模型,先后在热启动和课程学习、MoE路由算法、模型结构、训练加速等方面研究优化,大幅降低了万亿大模型的训练成本。
用千亿模型热启动,最快仅用256卡在一天内即可完成万亿参数大模型HunYuan-NLP 1T的训练,整体训练成本仅为直接冷启动训练万亿模型的1/8。

此外,业界基于万亿大模型的应用探索极少,对此腾讯研发了业界首个支持万亿级MoE预训练模型应用的分布式推理和模型压缩套件“太极-HCF ToolKit”,实现了无需事先从大模型蒸馏为中小模型进而推理,即可使用低成本的分布式推理组件/服务直接进行原始大模型推理部署,充分发挥了超大预训练模型带来的模型理解和生成能力的跃升。
目前HunYuan-NLP 1T大模型已在腾讯多个核心业务场景落地,并带来了显著的效果提升。
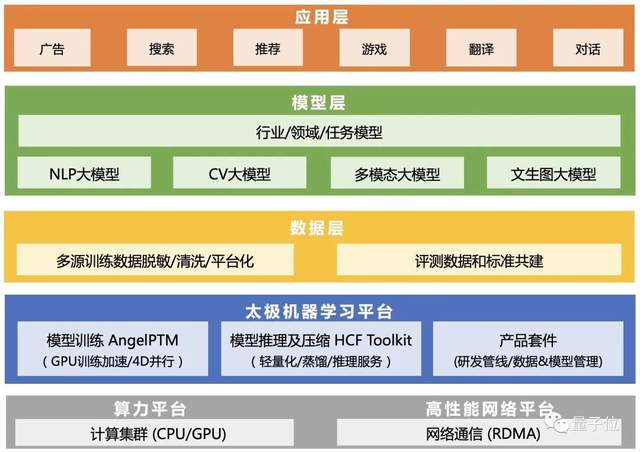
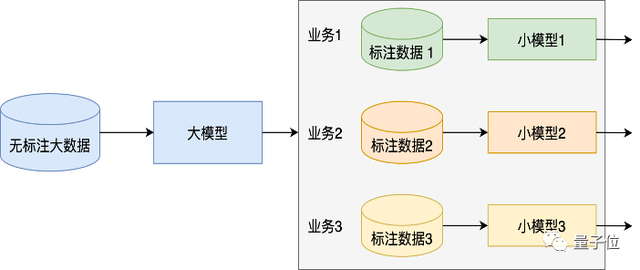
HunYuan协同了腾讯预训练研发力量,旨在打造业界领先的AI预训练大模型和解决方案(如下图),以统一的平台,实现技术复用和业务降本,支持更多的场景和应用。当前HunYuan完整覆盖NLP大模型、CV大模型、多模态大模型、文生图大模型及众多行业/领域任务模型。
背景
2018年提出的BERT模型[1],其规模最大为3亿参数,随后围绕亿级别参数规模的模型,有各种模型结构和训练方法的探索,包括Roberta[2]、ALBERT[3]等,模型结构和训练方法是提升模型能力的重要手段。
各大主流任务和工业界的关键业务(搜索、广告、推荐等)得益于预训练的能力,取得了显著的提升。对于工业界来说,随着业务的发展,小模型已经不能满足业务进一提升的需求,所以在大模型方向探索成为主流。
大模型对工业界来说,是一场变革,为业务带来更多的便利和更小的使用成本。
以前各个业务各自维护自己的小模型,标注和训练成本集中在下游,当业务需要提升模型规模,则需标注更大量的数据避免过拟合;同时各个业务单独训练模型需要耗费大量资源,但是产出的模型可复用性差,很难迁移到其他业务。
预训练大模型将更多的资源和数据转移到上游,集中力量办大事,海量数据训练的大模型提供给各个业务,只需要用很少的标注数据微调,就可以取得较好的效果,从而降低了业务的使用成本。
大模型的发展
下图展示了近几年NLP预训练模型规模的发展,模型已经从亿级发展到了万亿级参数规模。具体来说,2018年BERT模型最大参数量为340M,引发了预训练的热潮。2019年GPT-2为十亿级参数的模型[4]。2020年发布的百亿级规模有T5[5]和T-NLG[6],以及千亿参数规模的GPT-3[7]。2021年1.6万亿的MoE模型Switch Transformer[8]发布,首次将模型规模提升到万亿。
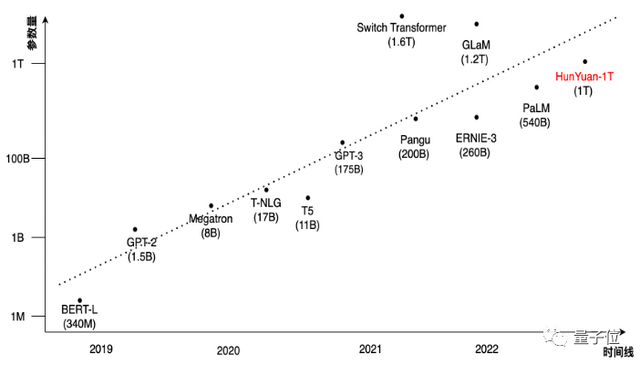
△M百万,B十亿,T万亿
业界做大模型有两种流派,MoE和Dense(稠密)模型流派。
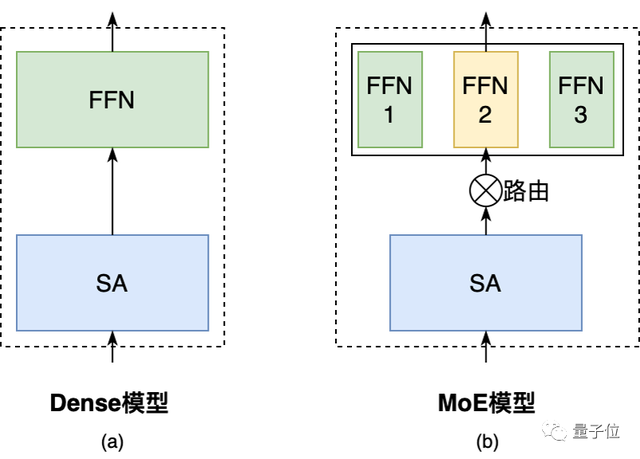
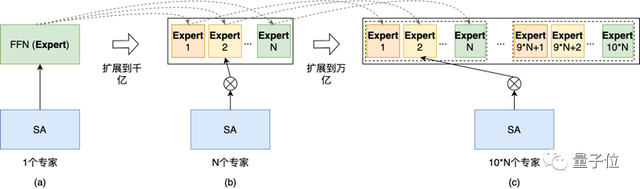
下图(a)是Dense模型的Transformer Block,在训练过程中,所有FFN和SA层的参数都是激活的,所以训练成本高。MoE是一种稀疏的模型结构,通过引入路由,只激活部分FFN(专家)的参数参与计算,从而能够节约训练成本。下图(b)是MoE模型的Transformer Block,该样例中FFN由3个专家组成,路由每次只激活其中1个专家。腾讯发布的HunYuan-NLP 1T大模型采用了MoE结构。
自研万亿MoE模型依据
1. 模型规模的提升能持续提升效果是做大模型的前提,如果增大规模不能持续大幅的提升模型效果,那么我们不值得投入高成本做大模型。这点GLaM[12]论文中已经得到了验证,当模型规模从0.1B/64E提升到64B/64E的时候,下游NLU和NLG任务的指标可以持续提升,且看上去不存在边际效益递减的情况。
2. 模型需要先做大后做小,大模型虽然能稳定提升下游任务效果,但实际在线业务使用的往往是压缩之后的小模型,用大模型压缩之后的小模型比直接训练小模型效果好,也是做大模型的关键依据,这点也在多个文章中被论证。
Switch Transformer用大模型蒸馏小模型,依然能保留大比例效果提升;此外,ICML2020[13]的文章也验证了先训练大模型后压缩,比直接训练小模型效果更好。
因此,模型需要先做大后压缩,才能取得更可观的收益。
3. 大模型包括了MoE稀疏模型和Dense稠密模型,我们的HunYuan-NLP 1T大模型基于MoE开展,主要依据如下:
(1)在多篇文章中论述了相同的资源和计算量前提下,MoE模型效果优于稠密模型,包括[8]和[14]。[8]通过提升专家数量,计算量没有增加,模型的性能持续提升。[14]在相同的计算量前提下,MoE模型效果优于Dense模型。
(2)相同规模的大模型,MoE模型的训练和推理效率更高,对资源的消耗更小。
模型算法
模型配置
挑战描述:(1)基于MoE模型,业界尚未有关于大模型专家数量上限的结论,配置专家规模和数量需要探索;(2)理论上只扩展专家数量提升模型规模是有瓶颈的,即不能无限扩大专家数量。
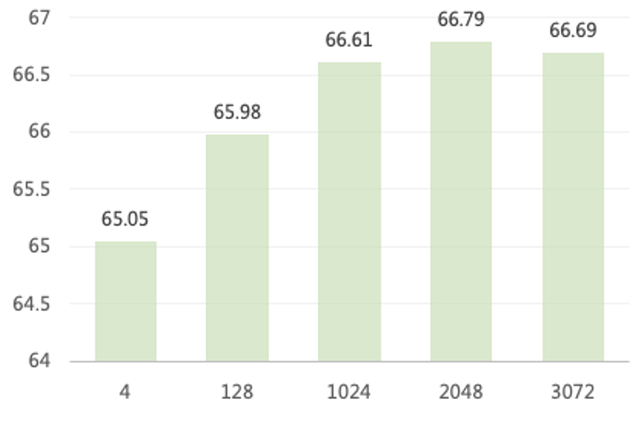
解决方案:在小规模模型上(千万级),通过扩大专家数量提升模型规模,我们发现专家数量的提升对下游任务(多个下游任务均值)效果是有瓶颈的。
下图为专家数量和下游任务效果的关系图,当专家数量提升到2000左右,效果提升开始减弱,当进一步提升专家数量到3000,下游任务指标不增反降。
所以我们基于30亿的Dense模型扩展HunYuan-NLP 1T大模型,专家数量设置为1536个。
热启动和课程学习
挑战描述,模型规模越大,需要喂越多的数据,对于万亿参数规模的模型,在有限的资源内训练收敛是非常有挑战的(业界万亿参数的模型基本需要~7000亿tokens)。
解决方案,热启动+模型规模课程学习的策略,我们借鉴了课程学习的思想,首先在小规模的模型上训练收敛,然后将小模型的知识迁移到大模型,逐步增加模型的规模。具体来说,如下图(a)所示,我们先训练只有一个专家的Dense模型,然后,如图下(b)通过扩展专家数量把模型规模提升到千亿规模并训练收敛,最后继续通过增加专家数量把模型规模提升到万亿直至收敛如下图(c)。
关键成果,千亿规模以下的模型训练成本相对于万亿少一个数量级,而万亿在千亿的基础上只需要很少的迭代就能到达较好的水平。具体来说,我们在千亿的基础上扩展万亿,只需训练~1天/256卡,即可在下游任务效果上超过千亿~10%。
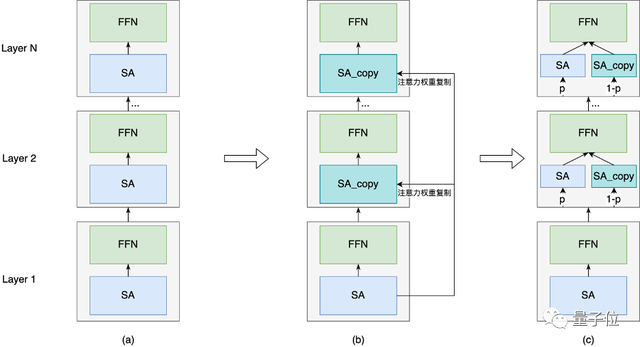
注意力权重复制
挑战描述:Transformer主要由SA层和FFN层组成,SA层计算Attention Weights,并加权。Attention Weights的计算时间复杂度很高(和序列长度成平方级关系)。
解决方案:我们发现Attention Weights在不同层之间的差异性不大。一个直接的想法是只在第一层计算Attention Weights,在其它层复用这些值,那么整个模型Attention Weights的计算复杂度降低为原来的1/N,如下图(b)所示。但是,通过实验发现,这种方法对效果是有损失的。因此我们对模型做了进一步改进,在每一层我们随机掷骰子,有p的概率重新计算Attention Weights,1-p的概率复用上一层的Attention Weights。通过实验发现,当p设置为50%,模型效果无损,Attention Weights总的时间复杂度降低50%。
关键效果:大模型预训练提速~20%,下游任务指标略正。
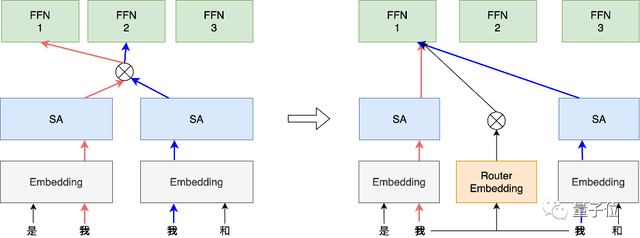
词向量路由机制
挑战描述,原来的Routing方法以Self-Attention的输出作为输入,有几个缺点:首先路由和词本身的关联随着SA对信息的加工逐渐变弱。其次不同层之间的Self-Attention输出差异很大,路由的稳定性比较差。如下图(左),对于相同的词“我”,路由分配到不同的专家(专家1和专家2)。
解决方案,我们引入了额外的词向量用于专家的路由,把路由和Attention层输出解耦。如下图(右)所示,相同的词的路由向量相同,所以它们从始至终分配到相同的专家提取特征,不仅保证了路由稳定性而且加速了收敛。
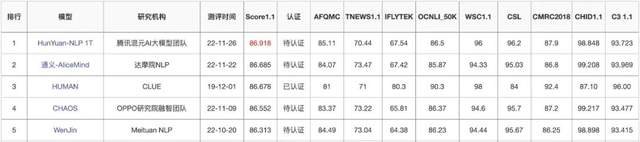
公开评测
CLUE 介绍
CLUE是中文最权威的自然语言理解榜单,主榜单总共包含了9个任务(6个分类任务和3个阅读理解任务)。
其中6个分类任务形成了分类榜单,3个阅读理解任务形成了阅读理解榜单。
这些任务是来自不同领域、不同场景的文本分类、句间关系判断、指代消解、阅读理解等任务,涵盖的场景和搜索、广告、推荐等业务场景高度契合,因此对预训练模型的通用理解能力挑战非常大,也对模型在不同领域、不同数据质量和数量的下游任务的知识迁移能力要求非常高。
业界各大互联网公司和知名研究机构都在中文预训练模型上发力,并且在CLUE榜单上提交验证,竞争非常激烈。
关键结果
如下图所示,我们提交的HunYuan-NLP 1T模型,在CLUE总榜、分类榜和阅读理解榜登顶,远超其他团队的预训练模型,甚至超过人类水平,凸显了大模型对自然语言理解任务以及业务应用的巨大潜力。
预训练加速(太极AngelPTM)
太极是腾讯自主研发的一站式机器学习生态服务平台。为AI工程师打造从数据预处理、模型训练、模型评估到模型服务的全流程高效开发工具。此次,基于高速网络基础设施建设,太极预训练框架为大模型的训练提供了有力保障。
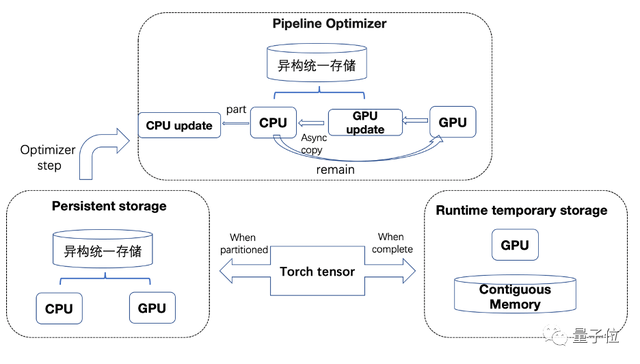
预训练框架,随着预训练模型的参数不断增大,模型训练需要的存储空间显著增加,如万亿模型仅模型状态需要17000多G显存,仅仅依靠显存严重束缚着模型参数的扩大。
为了降低显存的压力同时扩大模型参数,基于Zero-Infinity的理念我们开发了太极AngelPTM,其同Zero-Infinity一样在所有GPU之间partition模型的参数、梯度、优化器状态,并把参数、梯度、优化器状态offload到CPU内存,为了最优化的利用内存和显存进行模型状态的Cache,太极AngelPTM引入了显存内存统一存储视角,同时太极AngelPTM将多流异步化做到了极致,在充分利用CPU和GPU进行计算的同时最大化的利用带宽进行数据传输和NCCL通信,使用异构流水线均衡设备间的负载,最大化提升整个系统的吞吐。
在太极机器学习平台1T内存+单卡40G显存硬件环境下(由于SSD会以5倍多的速度拖慢训练,万亿模型并未考虑使用SSD作为三级存储),Zero-Infinity单机最大可容纳30B模型,需要至少320张卡训练万亿模型,太极AngelPTM单机最大可容纳55B模型,需要192张卡就可以训练万亿模型。相比Zero-Infinity,太极AngelPTM训练速度有2倍提升,节省40%训练资源。
高速网建设,大规模、长时间的GPU集群训练任务,对网络互联底座的性能、可靠性、成本等各方面都提出巨大挑战。
为了满足AI大模型训练需求,腾讯打造了星脉高性能网络,追求网络平台的极致高性能与高可用。
在极致高性能上,采用1.6T超带宽服务器接入、流量亲和性网络架构、自研高性能通信库TCCL,构建了1.6T ETH RDMA网络,实现了AI大模型通信性能的10倍提升,通信时延降低40%,单集群规模达到2K(最大规模32K),基于全自研网络硬件平台网络建设成本降低30%,模型训练成本降低30%~60%。
在高可用保障上,通过全自动化部署配置核查,覆盖服务器NUMA、PCIE、NVSwitch、网卡、交换机数百个配置项,并通过实时Service Telemetry技术监控业务系统运行效率,保障大规模集群部署,实现性能实时监控与故障告警。
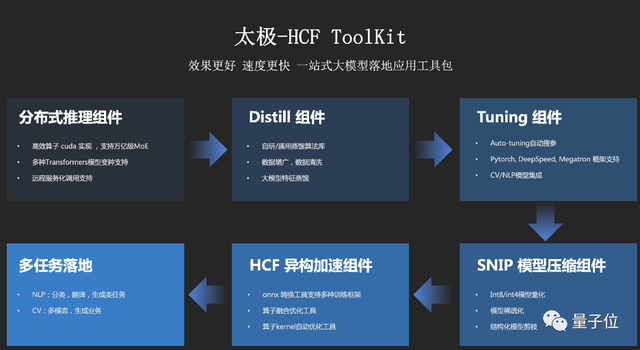
大模型压缩和分布式推理(太极-HCF ToolKit)
一个典型的预训练大模型应用流程如下所示,为了使大模型能够在可接受的推理成本下最大化业务效果,设计了一套“先蒸馏后加速”的压缩方案实现大模型的业务落地。
为此腾讯推出了太极-HCF ToolKit,它包含了从模型蒸馏、压缩量化到模型加速的完整能力。
太极 – HCF distributed(大模型分布式推理组件):我们采取了服务化teacher大模型来加速蒸馏训练,利用训练框架的分布式能力做大模型推理是一种简单直接的做法,但是训练框架在推理过程包含很多冗余的步骤,会占用额外的资源,造成不必要的浪费,且无法充分利用现有的单卡推理优化能力。
为此我们融合分布式能力和单卡推理优化构建了一套分布式推理的工具HCF-distributed,它兼顾分布式高效推理能力的构建和易用性建设。
基于我们的分布式推理能力,HunYuan-NLP 1T大模型推理只需 96张A100(4G) 卡,相比于megatron至少需要160卡,资源设备占用减少了 40%。
太极 – SNIP(大模型压缩组件):我们结合量化、稀疏化和结构化剪枝等多种加速手段,进一步加速了student模型的推理速度。
我们先将大模型蒸馏到较小(bert-base, bert-large)的中间规模,然后在此基础上利用模型压缩手段加速中间规模模型的推理速度,最终获得一个效果更好,推理更快的业务模型。
在技术上,我们从蒸馏框架和压缩加速算法两方面,实现了迭代更快,效果更好,成本更低的大模型压缩组件。
应用案例
HunYuan先后支持了包括微信、QQ、游戏、腾讯广告、腾讯云等众多产品和业务,通过NLP、CV、跨模态等AI大模型,不仅为业务创造了增量价值而且降低了使用成本。特别是其在广告内容理解、行业特征挖掘、文案创意生成等方面的应用,在为腾讯广告带来大幅GMV提升的同时,也初步验证了大模型的商业化潜力。
接下来,我们通过样例展示混元AI大模型在对话生成和小说续写等场景下的能力。
对话应用案例

小说续写应用案例[18]

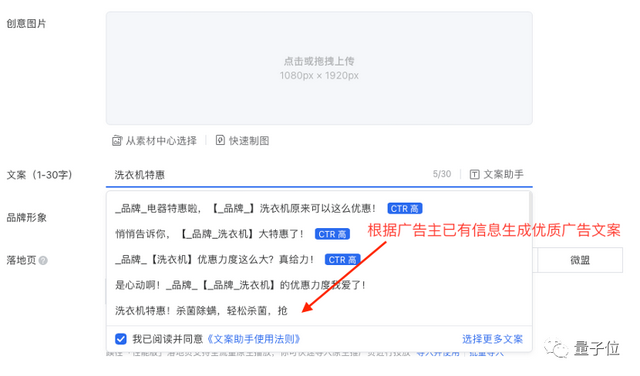
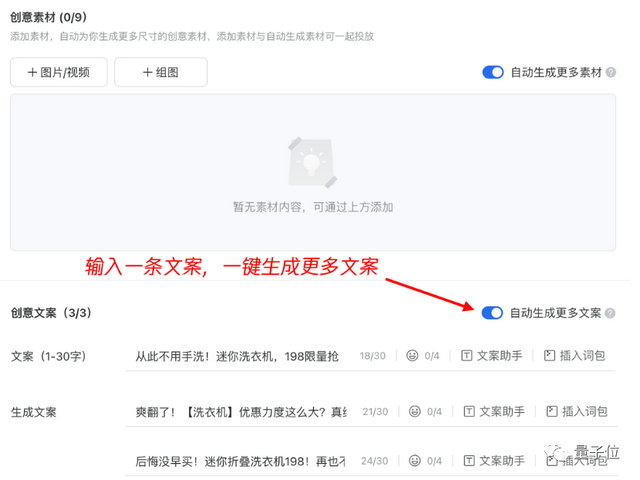
广告文案生成和衍生应用案例
广告文案生成:
广告文案衍生:
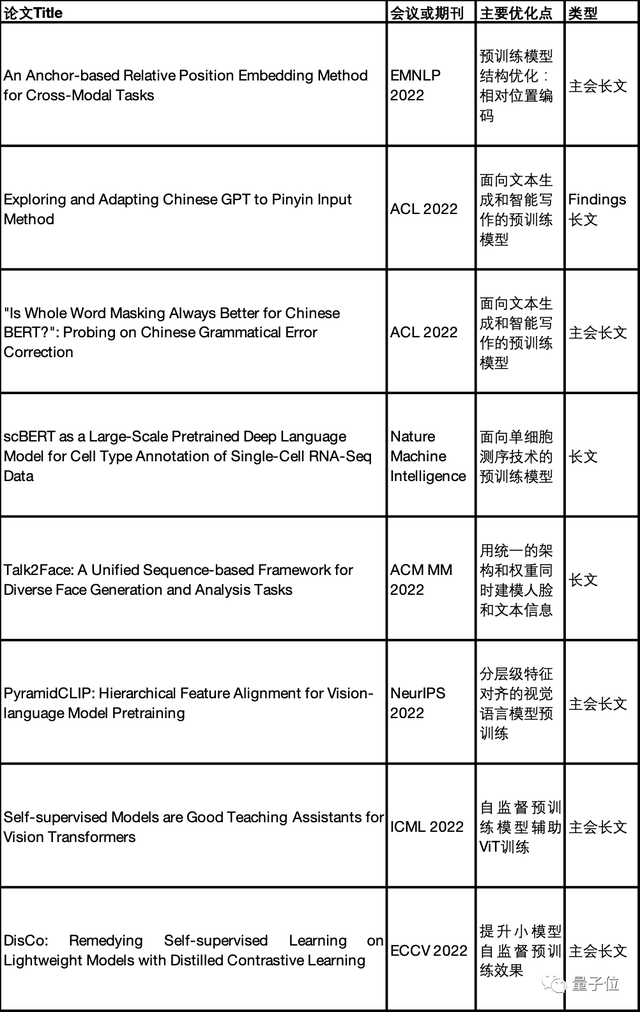
附录:混元顶会论文
参考链接:
[1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding https://arxiv.org/abs/1810.04805
[2] RoBERTa: A Robustly Optimized BERT Pretraining Approach https://arxiv.org/abs/1907.11692
[3] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations https://arxiv.org/abs/1909.11942
[4] Language Models are Unsupervised Multitask Learners https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
[5] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer https://arxiv.org/abs/1910.10683
[6] T-NLG https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/
[7] Language Models are Few-Shot Learners https://arxiv.org/abs/2005.14165
[8] Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity https://arxiv.org/abs/2101.03961
[9] PanGu-α: Large-scale Autoregressive Pretrained Chinese Language Models with Auto-parallel Computation https://arxiv.org/abs/2104.12369
[10] ERNIE 3.0 Titan: Exploring Larger-scale Knowledge Enhanced Pre-training for Language Understanding and Generation https://arxiv.org/abs/2112.12731
[11] PaLM: Scaling Language Modeling with Pathways https://arxiv.org/abs/2204.02311
[12] GLaM: Efficient Scaling of Language Models with Mixture-of-Experts https://arxiv.org/abs/2112.06905
[13] Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers https://arxiv.org/abs/2002.11794
[14] A Review of Sparse Expert Models in Deep Learning https://arxiv.org/abs/2209.01667
[15] RoFormer: Enhanced Transformer with Rotary Position Embedding https://arxiv.org/abs/2104.09864
[16] Talking-Heads Attention https://arxiv.org/abs/2003.02436
[17] GLU Variants Improve Transformer https://arxiv.org/abs/2002.05202
[18] 腾讯AI Lab发布智能创作助手「文涌 (Effidit)」,用技术助力「文思泉涌」https://mp.weixin.qq.com/s/b-kPSR3aFPKHpUnFv7gmeA
[19] 腾讯“混元”AI大模型登顶CLUE三大榜单,打破多项行业记录 http://ex.chinadaily.com.cn/exchange/partners/82/rss/channel/cn/columns/snl9a7/stories/WS628df605a3101c3ee7ad730e.html
— 完 —
- 文生图进入R1时代:港中文发布T2I-R1,让AI绘画“先推理再下笔”2025-05-14
- Manus终于开放注册!每天能免费玩一次2025-05-13
- 大模型终于通关《宝可梦蓝》!网友:Gemini 2.5 Pro酷爆了2025-05-03
- 10秒生成官网,WeaveFox重塑前端研发生产力 | 蚂蚁徐达峰@中国AIGC产业峰会2025-04-30