英伟达也来卷AI绘画,支持几笔完成精准构图,还提出扩散模型进化新方向
CLIP+谷歌T5都用上了
丰色 发自 凹非寺
量子位 | 公众号 QbitAI
英伟达也来卷扩散模型了。
这一次,它将文本生成图像的效果再次提高一个level。

比如,面对超长文本描述,它(下图最右列)比Stable Diffusion和DALL-E 2表达的都更精确:

注意第一组图刺猬的夏威夷风衬衣,以及第三组图猫猫的头盔。
当描述要求展示出具体的文字时,也只有它(下图最右列)可以准确做到:

除此之外,即时样式转换也是小菜一碟,只需一张样图就成。
比如来一个梵高风的泰迪熊冲浪:

或者这样的鸭子:

当然,英伟达最擅长的分割图作画,它也支持,可以让你用寥寥几笔完成精准构图:

(其中,每一个颜色块代表一个元素。)
看起来还阔以吧,它背后的方法也值得说道说道。
两个文本编码器+专家去噪网络
我们知道,扩散模型包含两个阶段:
从原图逐步到噪声的正向过程/扩散过程;
以及从噪声逐步到原图的逆向过程。
第二个过程就是去噪,作者想到,在此阶段,面对不同的噪声水平时都用不同的模型进行处理,也就是开发一个叫做“专家去噪”的网络,效果是不是会更好一些?
于是就诞生了这个新的AIGC工具:eDiffi。
eDiffi的pipeline由三个扩散模型级联而成:
一个可以合成64×64分辨率样本的基础模型,以及两个可以分别将图像分辨率递增到256×256和1024×1024的超分辨率模型。

当模型接收到一条文本描述时,会首先同时计算T5 XXL embedding和CLIP text embedding。
注意是用了两个文本编码器哦,不然效果不会这么好:

Ps. T5指的是谷歌的文本到文本转换器(Text-to-Text Transfer Transformer ),它可以帮助模型做到更精准地理解文本描述。
接着选择根据参考图像计算得出的CLIP图像编码,用作样式向量(可选可不选)。
然后再将所有embedding都馈送到上面的级联扩散模型中,最后逐渐生成分辨率为1024×1024的图像。
再来说说主角:去噪专家(Denoising experts)网络。
我们知道,在扩散模型中,图像的合成是通过迭代去噪过程来完成的,这个过程又指的是从随机噪声中逐渐生成图像。
在传统的扩散模型训练中,都是训练一个模型来对整个噪声分布进行去噪。
而在作者的这个框架中,他们训练了一组专家去噪器,专门用于在生成过程的不同步骤进行去噪。
如下图所示,作者是先从一个完整的随机噪声开始,然后分多个步骤逐步操作,最终生成一张骑自行车的熊猫图像。
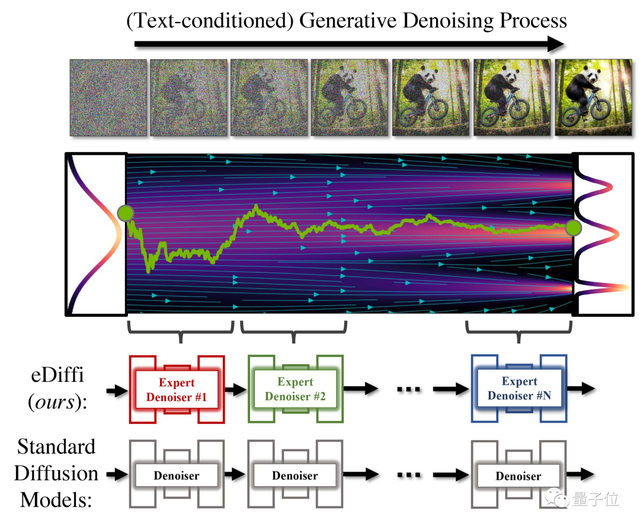
一位StabilityAI员工认为,这种方法可能是扩散模型的下一大突破/进步。因为不止英伟达的这个eDiffi,还有百度的文心ERNIE-ViLG 2.0也是这么做的。

zero-shot FID上获SOTA得分
eDiffi模型是在“公共和专有数据集的集合”上训练而成。
其中基础模型花了256块英伟达A100 GPU,两个超分辨率模型则花了128块A100。
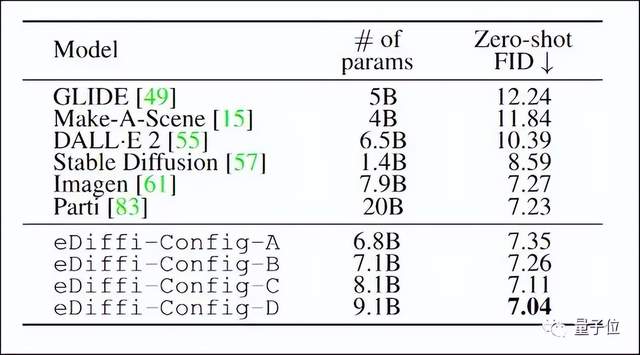
用于PK的模型包括GLIDE、Make-A-Scene、DALL-E 2、Stable Diffusion和谷歌的两个图像合成系统Imagen和Parti。
作者从COCO验证集中随机提取30000个文本描述,然后让这些模型生成结果,纪录zero-shot FID-30K得分。
最终,eDiffi获得了最低也就是最佳分数,说明它与文字的匹配度是最高的。
最后,再来两组效果展示和对比:

以及风格迁移的(第一列为参考风格,第二列为结果,第三列为参考图像):

关于作者
一共有12位,都来自英伟达,其中3位华人:
毕业于康奈尔大学的博士黄勋(AdaIN一作)、毕业于清华本科和斯坦福博士的Song Jiaming以及英伟达高级研究总监Liu MingYu。

目前,该模型还未开源,不过有人表示改动不算大,所以实现起来并不难,应该很快就有人复现出来了。
论文地址:
https://arxiv.org/abs/2211.01324
项目主页:
https://deepimagination.cc/eDiffi/
参考链接:
[1]https://twitter.com/iScienceLuvr/status/1587973173932195840
[2]https://twitter.com/_akhaliq/status/1587971650007564289
[3]https://www.unite.ai/nvidias-ediffi-diffusion-model-allows-painting-with-words-and-more/
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10