
Meta用一个头显搞定全身动捕,无需手柄和下身传感器,网友:VR终于少点物理挂件了
“元宇宙终于要有腿了”
萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
还记得你玩VR的时候,完全看不到自己下半身的样子吗?

毕竟,目前的VR设备通常只有手柄和头显,没有下半身传感器,系统无法直接判断下半身的动作,预测时也容易出bug。
现在,Meta终于迈出了一大步——只凭头显(甚至不用手柄),就能搞定全身动捕,连双腿的不同动作都预测得一清二楚!

新研究一po出就在网上爆火。

有网友调侃,小扎的元宇宙终于要有腿了,顺手还po了个Meta的股票。
还有VR玩家感到高兴:玩游戏时终于可以在身上少挂点硬件了!
这项研究究竟是如何只用头显做到全身动捕的?
给强化学习AI搞个物理约束
研究人员设计了一个框架,以头显(HMD)和手柄控制器的位置和方向数据作为输入,其他数据全靠AI预测。
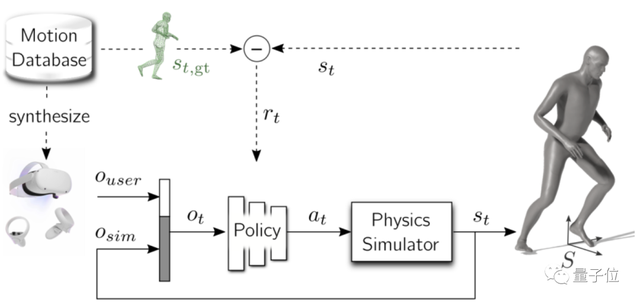
为此,他们先基于强化学习训练了一个策略(policy,基于三层MLP),根据仅有的HMD和手柄数据,尽可能逼真地还原真实动作捕捉的姿势(动捕数据一共10小时)。
他们搞了4000个身高不同的仿真人形机器人,每个机器人具有33个自由度。
随后,将这些机器人在英伟达的Isaac Gym(一个专门用于强化学习研究的机器人物理模拟环境)中同时进行训练,比单个环境下训练一个机器人要更快。

在物理环境中一共训练了2天(约140亿步)后,这只框架就能基于这个强化学习策略,根据头显和手柄数据直接预测用户全身动作了——
包括慢跑、行走、后退或过渡动作(transition)等。
不仅如此,Isaac Gym还允许添加其他不同的模拟对象,因此还能通过训练环境复杂度以增强动作真实性。
例如,根据虚拟环境中新增的皮球,模拟出“踢”的交互动作:

所以,相比其他模型,为什么这个框架预测的效果更好?
(此前虽然也有手柄和头显预测全身姿态的AI,但预测全身动作时往往会出现身体不自然抖动、走路时脚像是在“滑冰”、接触力不稳定等bug)
Meta研究人员分析后认为,此前模型难以准确预测下半身姿态的原因,是预测时上下半身的关联度较小。
因此,如果在预测时增加一定的物理约束(人体力学),例如惯性平衡和地面接触力等,就能让预测精度更上一层楼。

△脚上的红色直条大小表示接触力大小
研究人员还进一步发现,即使不用手柄控制器,只需要头显的60个姿势(包含位置和方向数据),就足以重建各种运动姿态,还原出来的效果同样没有物理伪影。
除此之外,由于这个策略是基于4000个身高不同的仿真人形机器人训练,因此它也能自动根据用户的不同身高来调整策略(具有基于动捕的重定向功能)。
不过,也有网友好奇他为什么要采用强化学习来预测运动姿态,毕竟当前监督学习是主流方法。
对此作者回应称,强化学习更方便加入物理约束(即降低抖动、脚滑等bug的关键原因),但对于监督学习来说,这通常是个难点。

但研究人员也表示,目前这个框架还有一定限制,如果用户做的动作不包含在训练数据中(例如快速冲刺)、或是进行了某些过于复杂的交互,那么虚拟环境中的仿真机器人就可能当场跌倒、或出现模拟失败的情况。
作者介绍
三位作者都来自Meta。

一作Alexander W. Winkler,目前是Meta Reality Lab的研究科学家,研究方向是非线性数值优化、高自由度运动规划、基于三维物理的仿真和可视化等。
他本硕毕业于德国卡尔斯鲁厄理工学院(KIT),博士毕业于瑞士苏黎世联邦理工学院(ETH)。

Jungdam Won,目前是Meta AI Lab的研究科学家,本科和博士毕业于韩国首尔大学计算机科学与工程系,研究方向包括强化学习中智能体的控制和交互,以及通过机器学习方法优化动作捕捉等。

Yuting Ye,目前是Meta Reality Lab的研究科学家,参与过Quest和Quest 2的手柄跟踪功能研发,本科毕业于北京大学,并在弗吉尼亚大学获得硕士学位,博士毕业于佐治亚理工学院,研究方向是动作捕捉和元宇宙等。
论文地址:
https://arxiv.org/abs/2209.09391
参考链接:
https://twitter.com/awinkler_/status/1572968904401776641
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07

相关阅读




幻霄科技CTO高天寒:创新教育体验—探索AIGC在元宇宙教学实训中的无限潜能|量子位·视点分享回顾
围绕AIGC技术和元宇宙技术在创新教育中的应用,幻霄科技联合创始人兼CTO、首席科学家高天寒在「量子位·视点」直播中分享了他的从业经验和观点。




