
阿里“通义”大模型炸场WAIC,背后要从一篇论文讲起
核心技术开源开放
杨净 萧箫 发自 凹非寺
量子位 | 公众号 QbitAI
“技术路线全公开,核心模型开源开放,应用场景200多个……”
在大模型这块,阿里直接在WAIC上憋了个大的——
通义大模型系列。
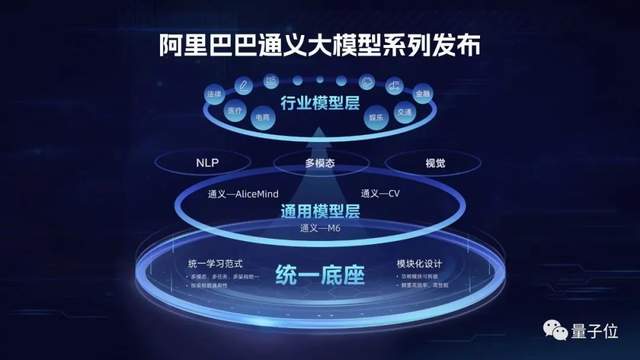
技术上,不光在NLP等单模态场景实现SOTA,许多多模态任务也实现了引领。
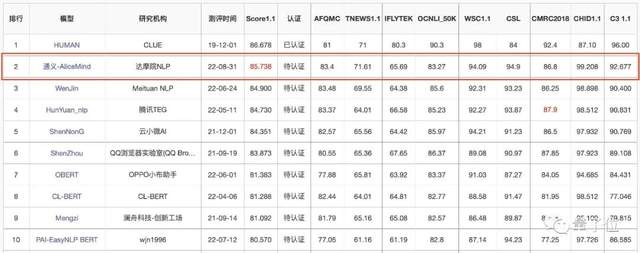
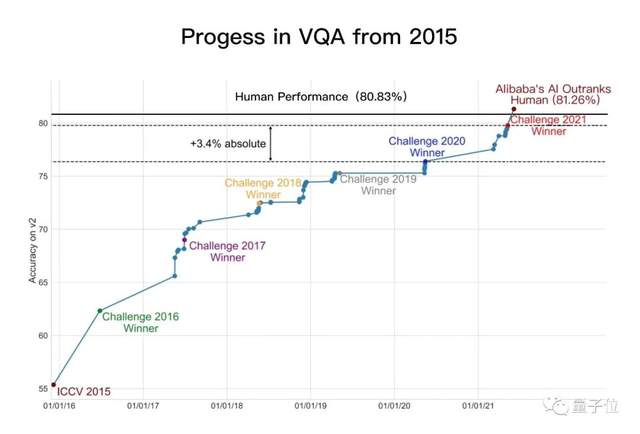
比如VQA challenge第一,准确率首超人类表现:
更硬核的是国内首个“统一底座”,业界首次实现模态表示、任务表示、模型结构统一。
不引入新增结构,单一模型就可以同时处理超过10项跨模态任务,升级后可以处理超过30种。
落地应用上,更是已经深入到电商、设计、医疗、法律、金融等行业,服务超过200个场景。
直接看文生图创作,中国风、科幻风、电影感、游戏场景、反现实风……全都不在话下。

资源消耗相对也不高,以通义系列中的M6大模型为例,相同参数规模下训练能耗仅是GPT-3的1%。
在落地层面,这次阿里也推出了新的技术框架,减少了大模型使用时的算力消耗,运行可提速10倍。
概括起来就是,既通用多种任务,又容易落地应用。
要知道,大模型落地几乎是行业公认的难题,“通用”很多时候意味着“大而全”,效率经常就跟不上。
而这次,阿里提出了统一底座+模型体系的技术路线,一言蔽之,就是“大一统”+“层次化”。不管是通用性还是易用性,都要做到极致。
这背后究竟有着什么样的底气?
“大一统”技术,什么来头?
答案早就藏在达摩院发布的一系列大模型论文里。
其中有一篇关键论文,就是通义大模型背后的核心技术支撑——统一学习范式OFA。
以这篇论文为技术底座,通义大模型真正具备了能搞定多种任务的“大一统”能力,变得既通用又易用:
不引入新增结构,单一模型即可同时处理图像描述、视觉定位、文生图、视觉蕴含、文档摘要等10余项单模态和跨模态任务,效果都很不错;升级后更是可以处理超过包括语音和动作在内的30多种跨模态任务。

这里“大一统”技术的关键,在于提出并实现了三个“统一”:
- 架构统一。使用Transformer(encoder-decoder,编解码器)架构,统一进行预训练和微调,无需在应对不同任务时,增加任何特定的模型层。
- 模态统一。不管是NLP、CV这种单模态,还是图文等多模态任务,全都采用同一个框架和训练思路。
- 任务统一。将所有单模态、多模态任务统一表达成序列到序列(Seq2seq)生成的形式,同类任务的输入几乎就是“一个模子里刻出来的”。

基于这一思路,模型基于2000万个图像-文本对进行预训练,就达成了多个跨模态任务(图像生成、视觉定位、图像说明、图像分类等)的SOTA,同时单模态任务的水平也与行业领先不相上下。
乍一看,这种“大一统”的思路,似乎与刚刚新鲜出炉的微软“六边形战士”BEiT-3理念上不谋而合,但其实两者之间存在本质不同,加上OFA最早在今年2月就已露出苗头,也不存在数据上的可比性。
微软BEiT-3在网络架构、预训练方法、规模效应(19亿数量级参数)上实现了“大一统”,它采用的方式是和下游任务解耦,可灵活按需定制开发,性能表现突出。
而OFA考虑的是另一种思路——Task Scaling First,任务规模优先。让单一模型能做尽可能多的跨模态任务,这样预训练后不新增结构,就能直接在下游任务中使用。
模型一共使用了8个任务(含子任务共15个)进行预训练,并固定每一类任务的提问方式(输入)和获取目标(输出):

就连输入和输出的格式都给你规定好了,不论文字、图片还是边界框,只能用一种方式作答:
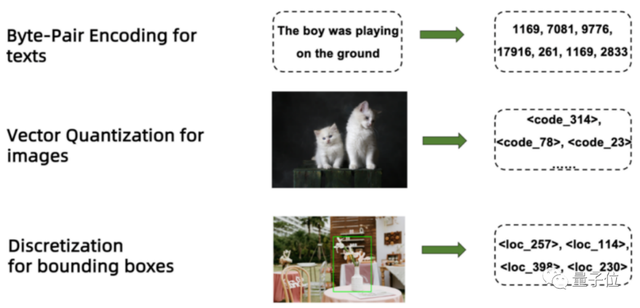
这样一来,大模型看到特定格式的问题就知道要怎么答,就像你看到作文框“口口”就知道往里面填字,看到数学题就想写“解”。
最关键的是,这种大模型理论上具备可扩展的能力,就像人一样可以学到越来越多的任务模型,掌握越来越多的做题方法。
至于这些任务是什么模态?并不会对模型产生影响,看到输入知道怎么输出就行了。
当然,在扩大任务规模时,也可能会遇到直接增加任务数量,导致模型输出效果降低等情况。
因此,如何更好地设计任务分组、找到合适的指令模板,也是在未来继续扩张任务规模时需要考虑的问题,而这也是研究小组下一步的计划。
但话又说回来,这样的“大一统”技术,实际落地表现究竟如何?
在“大模型落地难”这一行业公认现状的当下,它是否真的打开了大模型商业化应用的突破口?
落地场景200+,核心工具均开源
大模型落地难的原因,通常有两个。
其一,使用成本太高。以往对于预训练大模型来说,即使微调,依赖的底层资源也不低,如果对效果有进一步要求,则需要继续提升训练数据规模,成本还会进一步提升。
其二,落地效果有限。对于部分应用场景而言,大模型并不是一个性价比高的选择,实际使用时为了部署到特定设备上,往往需要模型压缩,导致性能下降明显。
但据介绍,阿里推出的通义大模型,在电商跨模态搜索、AI辅助设计、法律文书学习、医疗文本理解、开放域人机对话等200多个场景中应用落地时,均达到了2%~10%的效果提升。
这是怎么做到的?阿里采用了两种方法。
一方面,基于“大一统”思路做出通用大模型,再结合行业知识减少标注成本。
以法律场景为例,此前阿里已经与浙江省高院、浙江大学联合推出了一个能全流程辅助法官审判的AI,目前适用案件达到5000+,帮助法官提升效率达到40%。
这只法律AI实现了“10案连审”的能力,即在30分钟的开庭时间内,辅助法官连续审理10个简单案例,极大地提升了这一流程的效率。
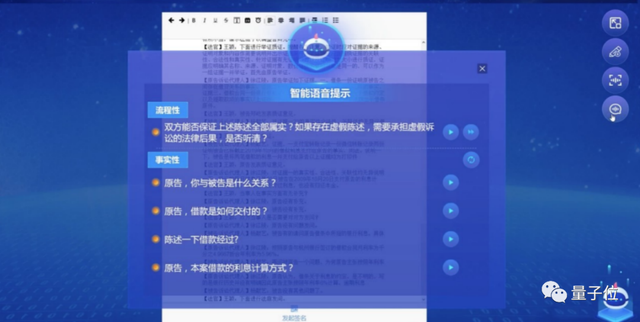
现在,这只AI,已经基于通用大模型+行业knowhow的思路进行迭代。通用大模型基于“大一统”技术,预训练时就已经具备了很强的理解和生成能力,只需再针对特定任务进行简单微调。
以AI学习法律文书时需要完成的“要素化抽取”为例,这里需要AI从大量的电子卷宗中提取有效信息,比如原被告信息、事件描述等,其中涉及的文本理解与抽取能力,就属于通用大模型的能力强项内。
另一方面,研发出多种高质量的大模型“浓缩”技术,可以根据客户的资源情况做快速适配,降低大模型落地的困难。
例如达摩院推出的大模型落地技术S4(Sound、Sparse、Scarce、Scale)框架,就包含了各种微调算法和模型压缩算法,本质上是希望将稀疏化等技术应用到到百亿量级的大模型中。

基于这一技术,阿里的270亿参数语言大模型PLUG在压缩率达99%的情况下,多项任务的精度损失在1%以内。
这意味着百亿参数大模型也可能在几乎不损失精度的情况下进行稀疏化,最终实现单卡运行。
值得一提的是,无论是这次发布的多模态统一底座模型M6-OFA,还是超大模型落地关键技术S4框架,又或是之前发布的通义语言大模型AliceMind-PLUG、多模态理解与生成统一模型AliceMind-mPLUG等核心能力,均已全部开源。
但即便具备将通用大模型落地的技术实力,仍然绕不过一个最根本的问题:
为何阿里要选择“大一统”这条技术路线?
激发大模型“通用”的潜力
一方面,通用大模型一直是行业研究趋势之一。
尤其是多模态多任务技术,最近更是成为一波研究潮流,不仅谷歌和DeepMind接连提出Pathway和Flamingo等多任务多模态通用大模型,艾伦人工智能研究所一直在做相关技术,就连微软前段时间“卷土重来”的BEiT-3也在延续这一思路。
无论是加强模型的“任务意识”,还是做多模态大模型,本质都是希望能挖掘出大模型更“通用”的潜力。

另一方面,多模态大模型本身也是趋势之一,它更有可能模仿人类构建认知的过程。
业界目前有一类非常流行的观点,认为纯LM(语言模型)相关的预训练模型,距离所谓的人类智能,就不是一个完全正确的道路。
正如人类无法仅从语言中学到整个世界的构造一样,AI也必须有能力从图片、文字乃至视频音频等多模态混合的数据中学到模态之间的关联,才可能进一步加强对世界的认知。
这正是模型从感知智能到认知智能的关键一步。
回望大模型发展历程,从BERT至今已经过了很长一段路,但达摩院资深算法专家黄松芳认为,AI距离AGI依旧还有很长的路要走:
大家都希望AI系统越来越接近通用或是人类智能,但说实话从技术现状来看,还是有很长一段距离。
这次提出的通义大模型,也是希望能够把底座做得更实,尽可能减少AI模型在实际场景落地的定制化成本,这才能真正体现大模型的效果,说实话这也是整个AI落地应用最具挑战性的一点。
至于这种“大一统”技术中的“任务规模”路线,是否就真的能集成大模型已有的经验,将它做到离AGI真正更进一步?
或许还得交由时间来验证,但阿里在这条路上迈出了尝试的重要一步。
通义核心开源项目:
[1]https://github.com/alibaba/AliceMind/
[2]https://github.com/OFA-Sys/OFA
- 首个AI科学家发论文进ICLR!得分6/7/6,从选题到实验全程零人工2025-04-09
- AI应用突围,中小企业的新周期已至2025-04-11
- 商汤大装置发放“1亿代金券”,全栈赋能场景落地2025-04-10
- 米哈游蔡浩宇新作iPhone实机演示:10分钟就被AI小美撩到脸红,她的命运由我掌控2025-04-07











