阿里达摩院开源新框架:入局隐私保护计算,联邦学习迎来重磅玩家
隐私和便利能两全吗?
明敏 梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
没人愿意随便交出自己的隐私。
当苹果正式推出“应用跟踪透明度”隐私保护功能时,只有16%的用户选择了允许App跟踪自己的活动。
但正如苹果提示所说,有时又不得不用隐私数据来交换便利和服务质量。
于是一年后的今天,据Adjust数据分析公司统计,这一数字又回升到25%。
也就是说,更多的用户重新认可了接收个性化内容对自己的价值。
究竟有没有方法能做到两全其美,让互联网平台在严格保障用户隐私的前提下,仍为用户提供优质的服务?
还真有。
当下最主流的一种解决方案就是联邦学习,一种用来建立机器学习模型的算法框架。
在联邦学习的框架下,用户自身的数据从始至终都停留在用户自己的手机、汽车和各类物联网设备等终端内。
同时,训练机器学习模型需要的信息会以加密、加噪声或拆分等方式保护起来,聚合到云端的服务器进行模型更新,此后云端再将更新的模型推送给用户终端。
通过这样的交互和迭代过程,服务提供商既能够训练高性能的模型为用户提供服务,同时也能保护好用户的数据隐私。
联邦学习2016年由谷歌首次提出,之后逐渐成为热门研究领域。
学术上,论文发表数量迅猛增长。
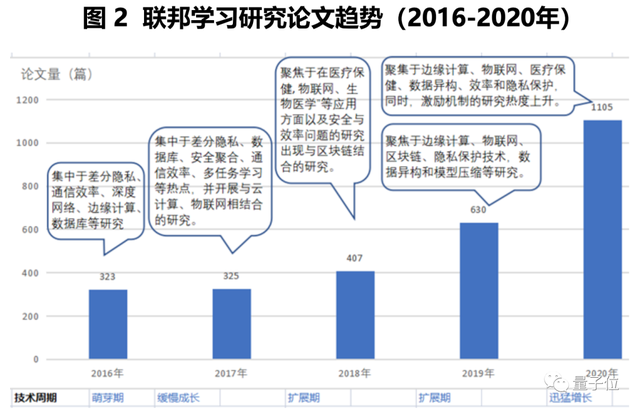
△来自清华大学《2021联邦学习全球研究与应用趋势报告》
开源框架上,也汇聚了国内外众多大厂。

△来自Github仓库Awesome-Federated-Machine-Learning
谷歌Tensorflow-Federated是横向联邦学习的代表:
本地和云端模型特征共享,样本数据不共享,更适合于C端同一企业为多个用户提供服务的情况。
杨强教授带领的微众银行FATE框架是纵向联邦学习的代表:
模型特征不一致,样本数据有重叠,更适合B端如两家企业共享一群客户但关注的特征不同。
再进一步又有联邦迁移学习,兼顾了上面两者的特点,适用于参与者间特征和样本重叠都很少的情况。
就在最近,又有重磅玩家悄然入局:阿里达摩院开源新的联邦学习框架FederatedScope。

△https://federatedscope.io
问题也随之而来:
新框架与之前有何差异点与竞争优势?达摩院为何选择此时入局?
不妨先从联邦学习领域现状,和FederatedScope框架自身的特性来一窥究竟。
当下需要什么样的联邦学习框架?
随着5G、物联网、云计算技术的发展,联邦学习涉及的设备的应用场景也越发多样。
异构性成了对传统联邦学习最大的挑战。
不同设备在算力、存储能力和通讯能力上的差异称为系统资源异构。
各个设备本地数据非独立同分布会导致数据异构。
不同的应用场景又会带来行为异构。
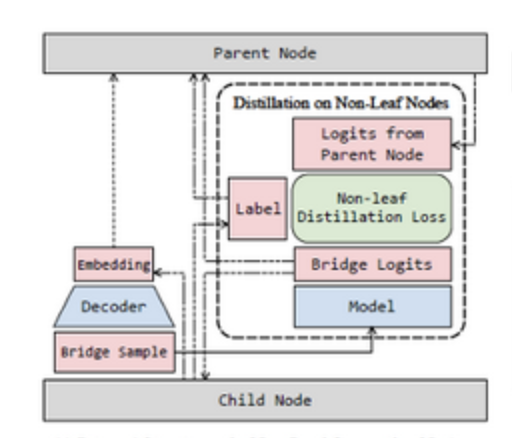
这些异构性对联邦学习提出了新的要求:
首先,联邦学习参与方之间传递的信息形式会更加丰富,不再局限于模型参数或者梯度这一类的同质信息。
如在金融、电信行业常用的图数据上进行联邦学习,参与方之间还会传递节点的嵌入式表示等信息。
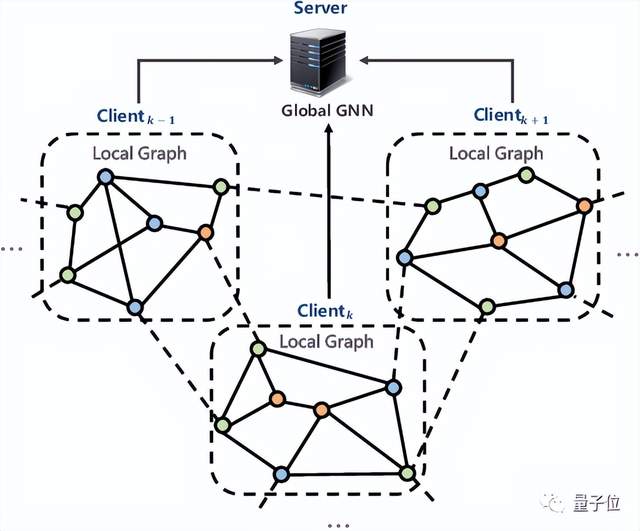
△来自《Federated Graph Learning – A Position Paper》
丰富的信息种类要求联邦学习框架能灵活支持不同类型的信息传递。
其次,跨设备联邦学习不能再拘泥于传统的“服务器端负责聚合,用户端负责本地训练”模式。
服务器端往往需要对模型做压缩处理,来满足终端设备的运行要求。而终端设备还要负责对收到的模型进行微调来取得更好的效果。
多样化的参与方的行为要求联邦学习框架能够灵活支持多种自定义行为。
跨设备还会带来的各参与方响应速度和可靠性参差不齐的问题,需要联邦学习框架允许开发者根据真实情况采用不同的异步训练策略。
甚至跨设备参与方还会使用不同的后端环境,例如有些设备使用PyTorch,另外一些则使用TensorFlow。
这要求联邦学习框架需要有更好的兼容性,支持跨平台组建联邦学习,避免要求使用者费时费力地对所有参与方进行环境的适配。
最后,随着联邦学习从研究前沿逐渐走向工业应用,需要联邦学习框架为单机仿真和分布式部署提供统一的算法描述和接口,以满足研究者和开发人员不同的应用需求,并降低从仿真到部署的迁移难度。
达摩院智能计算实验室开源的新联邦学习框架FederatedScope,正是为解决这些新挑战而生。
对于消息类型和自定义行为,FederatedScope将联邦学习看成是参与方之间收发消息的过程。
这样便可以通过定义消息类型以及处理消息的行为来描述联邦学习过程,同时支持用户通过添加额外的消息类型和处理行为进行定制化。
FederatedScope把联邦过程(例如协调不同的参与方)和模型训练行为(例如训练数据采样、优化等)解耦开,使开发者能够专注于定制参与方的行为。
相比现有的联邦学习框架,FederatedScope不需要从顺序执行的角度考虑如何串联不同参与方,降低了开发的复杂度及所需代码量。
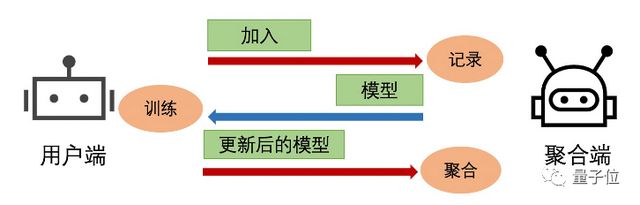
△经典联邦学习
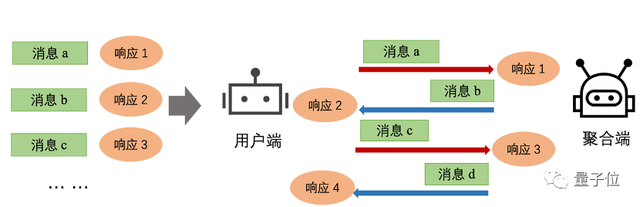
△FederatedScope模式
对于异步训练,FederatedScope采用事件驱动的编程范式来支持,并借鉴分布式机器学习的相关研究成果,集成了异步训练策略来提升训练效果。
对于后端跨平台支持,FederatedScope对训练模块做了抽象,使核心框架不依赖任意一种深度学习后端,能兼容不同的设备运行环境,大幅降低了联邦学习在真实场景部署的难度和成本。
除了解决这些挑战以外,FederatedScope还十分注意框架对多样化场景的适用性,以及对开发者的易用性。
对此,FederatedScope集成了多种功能模块,包括自动调参、隐私保护、性能监控、端模型个性化。
同时支持开发者通过配置文件便捷地调用集成模块,也允许通过注册的方式为这些模块添加新的算法实现并调用。
例如通过注册的方式使用准备好的新数据集和模型架构,可以方便的将经典联邦学习应用在不同下游任务,不需要修改其他的细节。
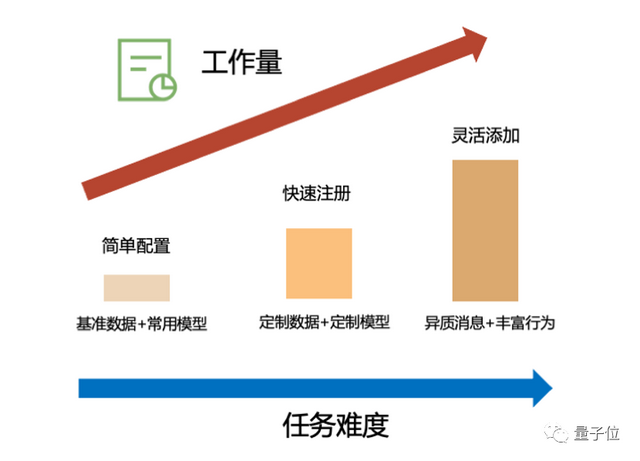
为了让即使是刚刚接触联邦学习的初学者能快速上手,FederatedScope提供了详尽的教程、文档和运行脚本。

同时FederatedScope也包含了常用的模型架构实现,对一些基准数据集也做了统一的预处理和封装,以帮助用户便捷地开展实验。
隐私保护计算发展到什么阶段了?
综上不难看出,达摩院对于联邦学习框架的考量,更多集中在了便捷与广泛的应用方面。
之所以会形成这样的局面,其实还要看整个大环境的变化。
从去年开始,隐私保护计算行业发展日趋火热。
日前IDC发布报告显示,2021中国隐私保护计算市场规模突破8.6亿元人民币大关,未来增长率有望超过110%。
Gartner预测表示,到2025年之前,约60%的大型企业预计将应用至少一种隐私保护计算技术,达摩院2022十大科技趋势同样将隐私保护计算列为重要趋势。
量子位智库估算,截至今年3月,国内具有隐私保护计算相关业务的厂商可能已经达到150家左右。
整个赛道呈现出第三方初创公司、大型互联网公司、AI软件开发商、转型公司、甲方自研参与的“混战局面”。
市场蓬勃发展的同时,国家、社会对隐私保护计算的关注度也在增加。
2020年,国家将数据纳入生产要素,与土地、劳动力、技术等传统要素并列;
2021年,《中华人民共和国数据安全法》《中华人民共和国个人信息保护法》《汽车数据安全管理若干规定(试行)》相继实施。
可以看到,政府近两年来一边在大力培育以数据为基础的资源市场,另一边也在加速建立相关规范。
社会层面对隐私保护计算的需求也在增长。
尤其是近两年来,健康码、人脸识别等应用让大众看到了数据流通带来的价值,但隐私泄露引发的安全事件也层出不穷。
这导致社会上关于合理合规使用隐私数据的呼声愈加高涨,进而催生出隐私保护计算产业更多需求和场景。
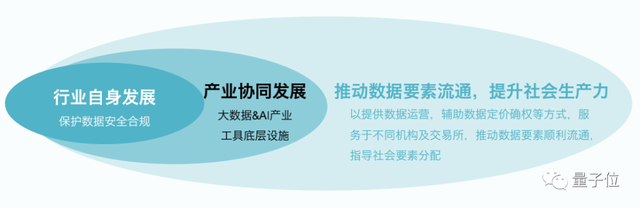
实际上,量子位智库分析,隐私保护计算产业非常重要的一层价值,就来自于为社会提供生产力。
量子位智库分析,隐私保护计算的价值分为三层:
- 第一层:行业自身发展
- 第二层:产业协同发展
- 第三层:推动数据要素流通,提升社会生产力
预计到2030年,我国隐私保护计算行业的总市场规模将达到1134亿。
其中第三层价值占比最高,可达到62%;第一层、第二层占比分别是11%、27%。
而另一边,学术研究上近两年对于联邦学习、隐私保护计算的关注度也在增高。
去年7月,Gartner预测,在2021-2025年的周期中,联邦学习将发挥主流作用,引导隐私保护计算的商业化大潮。
清华大学人工智能研究院联合多方发布的《2021 联邦学习全球研究与应用趋势报告》中也提及,联邦学习科研发展呈整体热度逐年上升趋势。
研究论文产出量及专利申请受理量,中美两国占据领先主导地位。
2016-2020年期间,中国联邦学习论文发表量为666篇,位居同期全球第一。
联邦学习高被引论文半数来自中美,全球该领域学者也主要聚集在这两国。
显然,科研界与产业界出现了协同共进的趋势。
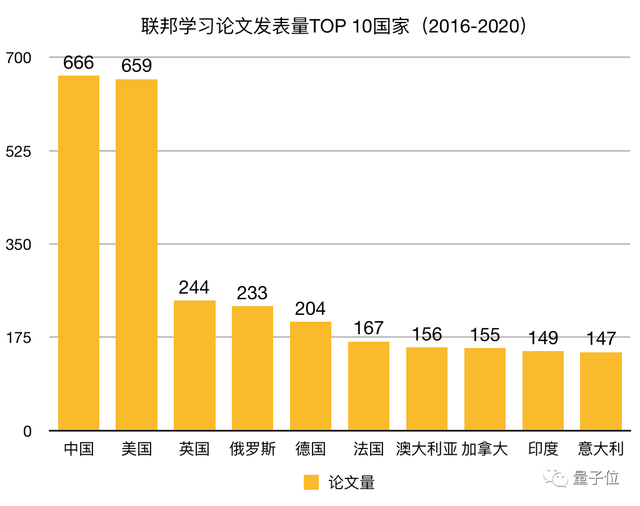
△来自清华大学《2021联邦学习全球研究与应用趋势报告》
在此背景下,也就不难理解达摩院为何在此时以开源平台,入局隐私保护计算了。
但为什么选择从底层技术做起?我们找到达摩院的技术专家,直接求问思考和答案。
一方面源自于达摩院的自身属性。
作为技术圈重磅玩家,达摩院自然更关注前沿技术本身的价值及前瞻性。
另一方面,还来自达摩院对隐私保护计算长期的洞察。
达摩院智能计算实验室资深技术专家丁博麟,有着十余年的隐私保护计算研究经历。他在与我们的交谈中提到,近两年来,联邦学习方面的科研成果开始集中涌现。
作为技术人员,自然而然想到从工具入手,推动这股研究浪潮更快前进。
“我们也是希望能够开源一个轻量级、易用的平台,让大家能够在上面实现更多的科研协同,从而产生更多学术成果,并更进一步推动产业创新。”
举个例子来说,现在很多服务商都需要申请用户的隐私数据权限,但每个人对隐私保护的要求不同。
在并不是所有人都愿意提供数据的情况下,如何保证产品能不断优化?
这就需要学界和产界进行共同探索。
FederatedScope开源平台便能为此提供一个模拟环境,支持多方联合开发。
而最后探索出来的成果,达摩院也会将它用开源框架工具的形式固定下来,避免后续开发者重复工作。
达摩院智能计算实验室高级技术专家李雅亮,负责了此次FederatedScope开源。
他表示目前这一版开源平台,主要是为技术开发提供助力,下一阶段将会更加侧重产业部署方面的考量。
而且除了联邦学习,达摩院在隐私保护计算的其他领域(如多方安全计算、可信执行环境等)也有部署。
达摩院智能计算实验室一直在密切关注数据安全和隐私保护方面技术发展,注重研究数据采集、数据共享和数据呈现等阶段中用户隐私安全保护问题,同时关注降低数据损耗、提高数据分析能力等研究。
技术和法规之间的gap如何填补?
值得一提的是,在与达摩院两位技术专家交谈的过程中,“合规”一词,被提及了20余次。
与之相关的内容,不是技术在法规压力下发展受限,在法规推动下蓬勃发展。
在隐私保护计算领域已有十余年研发经验的丁博麟提到,隐私保护计算技术的首要价值,就是促进合规。
这一点是任何一项隐私保护计算服务设计和开发阶段,最先考虑的问题。
或者说,在合规条件下实现技术创新、让数据流通价值更大化,是隐私保护计算技术的初衷之一。
那么,怎样才是合规的?技术的边界到底在哪里?
这个标准答案业内期盼已久。
实际上,我国不仅近年来出台多部数据隐私相关法律政策,立法严格程度也处于世界领先水平,这在一定程度上,促使我国隐私保护计算市场在起步较晚的情况下高速发展。
丁博麟认为,应该明确的边界包括几个层面:“哪些数据严格不能采集”,“哪些数据可以通过技术方案实现安全地采集和应用”,以及“哪些技术方案可以通过围绕合规法条构建的安全模型检验、在什么样的场景下可被使用”。
近年来出台的法规逐步明确了第一层面的边界,第二层面和第三层面的边界还有待政府部门联同产学研界共同探索。
这其中需要学术界来提供最核心和前沿的技术进展,也需要产业界从实际技术应用中提炼案例思考,共同为边界的细化提供参考。
而当边界更加清晰后,技术探索和产业发展的脚步还会加快,从而持续驱动数据隐私保护技术的进步和发挥数据应用的价值。

最后,回到文章的开始:
对于“隐私和便利是否能两全”这个问题,你怎么看?
FederatedScope开源地址:
https://github.com/alibaba/FederatedScope
参考链接:
[1]https://9to5mac.com/2022/04/14/number-of-users-opting-in-to-app-tracking-on-ios-grows-significantly-since-last-year/
[2]https://github.com/weimingwill/awesome-federated-learning
[3]https://arxiv.org/abs/2105.11099
- 手机实现GPT级智能,比MoE更极致的稀疏技术:省内存效果不减|对话面壁&清华肖朝军2025-04-12
- 7B小模型写好学术论文,新框架告别AI引用幻觉,实测100%学生认可引用质量2025-04-11
- 字节新推理模型逆袭DeepSeek,200B参数战胜671B,豆包史诗级加强?2025-04-11
- Llama 4发布36小时差评如潮!匿名员工爆料拒绝署名技术报告2025-04-07