
终于不瞎编了!AI学会了“谷歌一下”,回答问题正确率达90% | DeepMind
回答问题同时给出论据
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
语言模型总是给出“驴唇不对马嘴”的答案,已经成为它最饱受诟病的问题之一。
现在,DeepMind想到了一个解决办法——
让模型像人类一样,学会“谷歌一下”,回答问题同时还能给出论据。

这个模型名叫GopherCite,当你问它:
GopherCite是如何找到论据来源的?
它会回答:
通过谷歌搜索检索相关文档。
同时还给出了答案的依据,援引自DeepMind发布这项研究的页面。

而且遇到实在不懂的问题,它还会说“I don’t know.”,不会强行给一个错误答案。
训练结果显示,该模型在自然问题数据集、ELI5数据集上的正确率分别可以达到90%、80%,接近人类水平。
用强化学习训练AI查谷歌
首先我们来看一下GopherCite的效果如何。
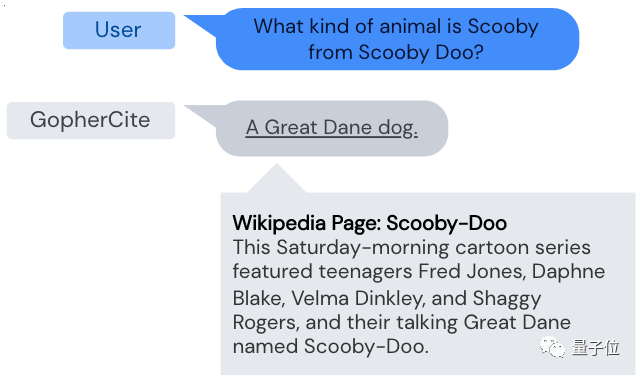
当被问道:
在Scooby Doo中,Scooby是什么动物?
GopherCite回答道:
一只大丹犬。
摘自维基百科Scooby-Doo。这是周六早上播出的系列青少年动画片,主角包括弗雷德·琼斯等,以及一只名叫Scooby-Doo、会说话的大丹犬。
不难看出,在学会找论据后,AI给出的回答靠谱多了。
事实上,GopherCite的前辈——超大语言模型Gopher,此前回答问题时的表现就要差劲很多。
Gopher是DeepMind在去年年底发布的NLP模型,包含2800亿参数。
它基于Transformer架构,在10.5TB大小的MassiveText语料库上进行训练。
在这里,DeepMind举了一个例子来说明。
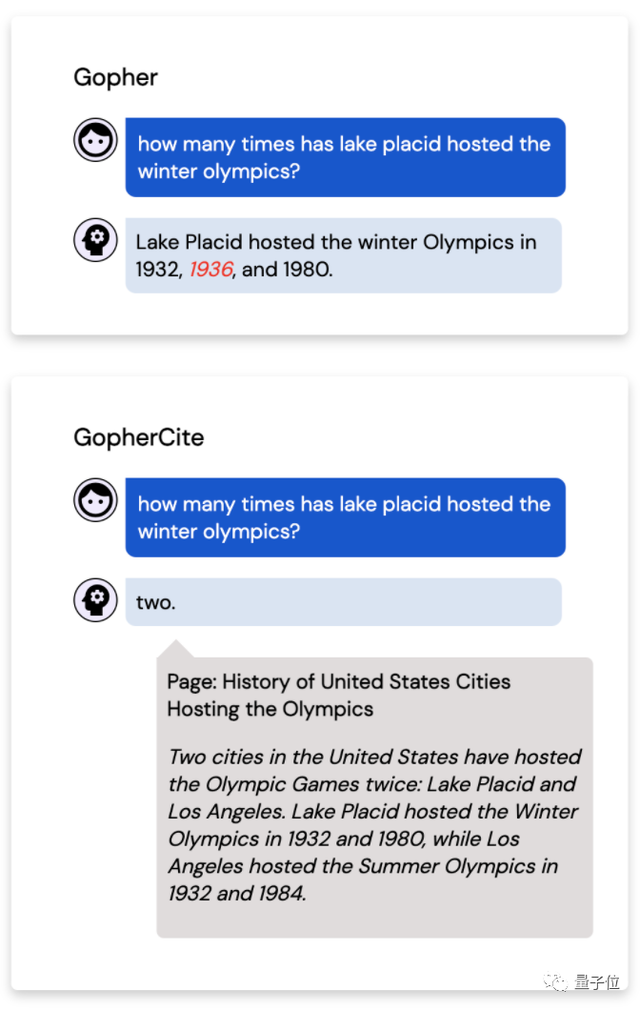
让Gopher和GopherCite回答同一个问题:
普莱西德湖一共举办过几次冬奥会?
Gopher回答(是错的):
普莱西德湖在1932年、1936年、1980年举办过冬奥会。
但GopherCite就答对了:
两次。
并给出了严谨的理由:
援引自美国主办奥运会城市史。1932年、1980年在普莱西德湖举办过冬季奥运会;1936年、1984年在洛杉矶举办过夏季奥运会。
那么GopherCite的具体工作原理是怎样的呢?
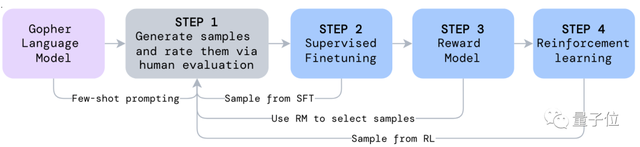
在Gopher的基础上,研究人员开发了一种奖励机制,也就是用上强化学习。
在收到问题后,模型会访问谷歌搜索的API来找到相关的网页,获取top-K结果。
(top-K操作,即从分数集合中找到k个最大或最小元素,是一个重要的机器学习模型组件,被广泛用于信息检索和数据挖掘中。)
然后它会根据问题来生成一些答案,答案数量N会大于K。
这些答案同时会带有自己的证据,即从网页上搜索到的包含答案的文段。
接下来,系统会对这些答案进行打分,最终输出得分最高的答案。

在推理过程中,模型采样会按照循环在文档上不断迭代,每个循环都会从单个文档中尽可能多地显示上下文内容,然后对文本重新排序并返回给上一步。
此外,这个模型还会计算最终生成答案的质量,如果生成答案太差,它就会选择不回答。

这是源于红牛的广告语:“它会给你翅膀”。
在ELI5Filtered数据集上回答70%的问题时,正确率为80%左右。
DeepMind表示这种训练模式和LaMDA有些类似。
LaMDA是谷歌在去年I/O大会上发布的一个对话模型,它能够在“听懂”人类指令的基础上,对答如流并保证逻辑、事实正确。

不同的是,LaMDA有时会直接给人分享问题的相关链接,而GopherCite可以直接摘出相关论据文段。
另外,OpenAI最近也开发了一个网页版GPT (WebGPT),同样也是用类似的方法来校正GPT-3。
DeepMind表示,WebGPT是通过多次访问网页来组织答案,GopherCite则是侧重于读取长文段。
还是会有失误
虽然懂得援引资料了,但是GopherCite有时还是会生搬硬套。
比如当你问它“喝了红牛会怎么样?”,它的回答是“翅膀”。
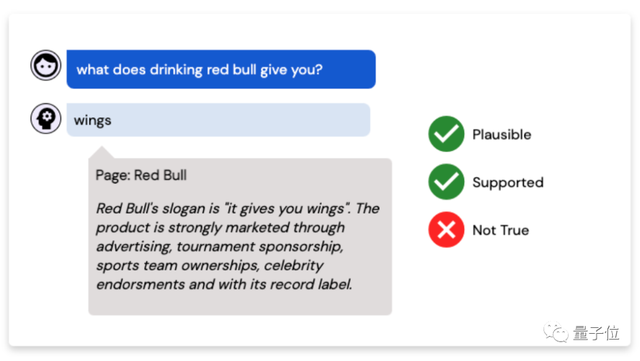
这是源于红牛的广告语:“它会给你翅膀”。
显然让它理解比喻还是有点困难……
也有网友吐槽说,可能人类自己去谷歌搜索会更快。
你觉得呢?
参考资料:
https://deepmind.com/research/publications/2022/GopherCite-Teaching-Language-Models-To-Support-Answers-With-Verified-Quotes
- 人类一生所学不过4GB,加州理工顶刊新研究引热议2025-04-13
- 北京队再上大分:新AI一句话就能搞开发,代码实时可见 | 免费可用2025-04-15
- 华为云发布CloudMatrix 384超节点 已通过昇腾云正式商用2025-04-10
- 华为昇腾AI云服务四大升级:搭载CloudMatrix 384超节点,性能领先2025-04-11










