
不拆分单词也可以做NLP,哈工大最新模型在多项任务中打败BERT,还能直接训练中文
性能和速度兼顾
众所周知,BERT在预训练时会对某些单词进行拆分 (术语叫做“WordPiece”)。
比如把“loved”、“loving”和“loves”拆分成“lov”、“ed”、“ing”和”es”。
目的是缩减词表、加快训练速度,但这样一来,在某些时候反而会阻碍模型的理解能力。
比如把”lossless”分成”loss”和”less”的时候。
现在,来自哈工大和腾讯AI Lab的研究人员,尝试利用不做单词拆分的词汇表开发了一个BERT风格的预训练模型——WordBERT。
结果,这个WordBERT在完形填空测试和机器阅读理解方面的成绩相比BERT有了很大提高。
在其他NLP任务,比如词性标注(POS-Tagging)、组块分析(Chunking)和命名实体识别(NER)中,WordBERT的表现也都优于BERT。
由于不用分词,这个WordBERT还可以直接进行中文训练。
更值得一提的是,它在性能提升的同时,推理速度并没有变慢。
可谓一举多得。
NO WordPieces
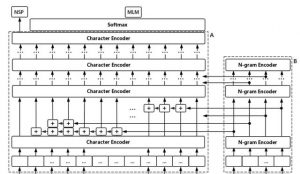
与BERT类似,WordBERT包含两个组件:词向量(word embedding)和Transformer层。
和以前的模型一样,WordBERT采用多层双向Transformer来学习语境表示(contextualized representation)。
word embedding则是用来获得单词向量表示的参数矩阵,与把单词分成WordPiece的BERT相比,WordBERT的词汇由完整的单词组成。
他们用自然语言处理软件包Spacy处理数据,生成了两个词汇表,一个规模为500K,一个为1M。
词汇表中还被单独添加了5个特殊单词:[PAD]、[UNK]、 [CLS]、[SEP]和[MASK]。
通过不同的词汇表规模、初始化配置和不同语言,最后研究人员一共训练出四个版本的WordBERT:
WordBERT-500K、WordBERT-1M、WordBERT-Glove和WordBERT-ZH。
它们的配置如上,嵌入参数都是随机初始化的,嵌入维数和基准BERT保持一致。
其中WordBERT-Glove用的词汇表是现成的Glove vocabulary,里面包含约190万个未编码的单词,该模型由相应的单词向量(word vectors)在WordBERT之上初始化而来。
WordBERT-ZH则是用中文词汇训练出来的WordBERT,它也保持了768的词嵌入维数。
性能与速度兼具
在测试环节中,完形填空的测试数据集来自CLOTH,它由中学教师设计,通常用来对中国初高中学生进行入学考试。
其中既有只需在当前句子中进行推理的简单题,也有需要在全文范围内进行推理的难题。
结果如下:
△ M代表初中,H代表高中
WordBERT-1M获得了最佳成绩,并接近人类水平。
它在高中题比BERT高了3.18分,初中题高了2.59分,这说明WordBERT在复杂任务中具有更高的理解和推理能力。
在词性标注、组块分析和命名实体识别(NER)等分类任务中,WordBERT的成绩如下:
相比来看,它在NER任务上的优势更明显一些(后两列)。
研究人员推测,这可能是WordBERT在学习低频词的表征方面有优势,因为命名实体(named entities)往往就是一些不常见的稀有词。
对于“中文版”WordBERT-ZH,研究人员在CLUE benchmark上的各种任务中测试其性能。
除了BERT,对比模型还包括WoBERT和MarkBERT,这也是两个基于BERT预训练的中文模型。
结果,WordBERT-ZH在四项任务中都打败了所有其他对比模型,在全部五项任务上的表现都优于基线BERT,并在TNEWS(分类)、OCNLI(推理)和CSL(关键字识别)任务上取得了3分以上的差距。
这说明,基于词的模型对中文也是非常有效的。
最后,实验还发现:
性能不差的WordBERT,在不同任务上的推理速度也并未“落于下风”。
关于作者
一作为哈工大计算机专业在读博士生冯掌印,研究方向为NLP、文本生成。
他曾在微软亚研院自然语言计算组、哈工大和科大讯飞联合实验室实习,在NLP领域的顶会ENNLP发表过一篇一作论文。
通讯作者为史树明,来自腾讯AI Lab。
论文地址:
https://arxiv.org/abs/2202.12142
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10

相关阅读

谷歌开源“穷人版”摘要生成NLP模型:1000个样本就能打败人类
BERT、GPT-2、XLNet等通用NLP模型都是“通才”,虽然全面,但在面向特定任务时需要微调,训练数据集也十分庞大,非一般人所能承受。 有没有一个非通用NLP模型,专门针对某项具体任务,在降低训练成本的同时,性能又有提高呢?这就是谷歌发布的“天马”(**PEGASUS**)模型,它专门为机器生成摘要而生,刷新了该领域的SOTA成绩>>>








