扩散模型就是自动编码器!DeepMind研究学者提出新观点并论证
作者曾为Spotify“猜你喜欢”模型开发者之一
明敏 发自 凹非寺
量子位 | 公众号 QbitAI
由于在图像生成效果上可以与GAN媲美,扩散模型最近成为了AI界关注的焦点。
谷歌、OpenAI过去一年都提出了自家的扩散模型,效果也都非常惊艳。
另一边,剑桥大学的学者David Krueger提出,自动编码器会不会卷土重来成为研究热潮。
就在最近,DeepMind的一位研究科学家Sander Dieleman基于以上两股热潮,提出了自己的观点:
扩散模型就是自动编码器啊!
这一观点立刻引起了不少网友的注意,大家看了Sander的阐述,都觉得说得很有道理,并且给了自己不少启发。
那么,他到底是如何论证自己这一观点的呢?
我们一起来看。
去噪自动编码器=扩散模型
想要看透这二者之间的联系,首先要看看它们自身的特点。
扩散模型是一种新的图像生成方法,其名字中的“扩散”本质上是一个迭代过程。
它最早于2015提出,是定义了一个马尔可夫链,用于在扩散步骤中缓慢地向数据添加随机噪声,然后通过学习逆转扩散过程从噪声中构建所需的数据样本。
相比GAN、VAE和基于流的生成模型,扩散模型在性能上有不错的权衡,最近已被证明在图像生成方面有很大的潜力,尤其是与引导结合来兼得保真度和多样性。
比如去年谷歌提出的级联(Cacade)扩散模型SR3,就是以低分辨率图像为输入,从纯噪声中构建出对应的高分辨率图像。
OpenAI的GLIDE、ADM-G也是用上了扩散模型,以此能生成更加更真实、多样、复杂的图像。
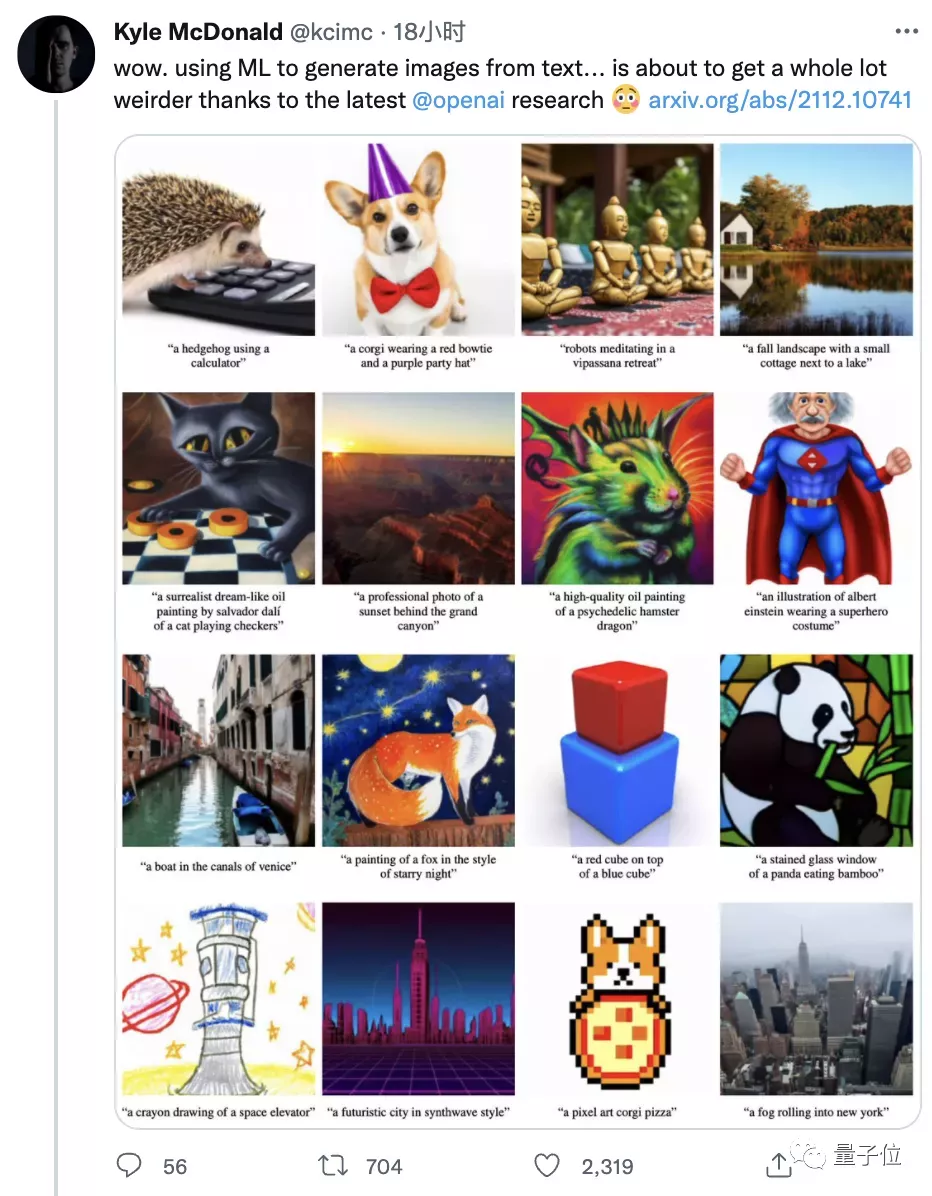
△GLIDE模型效果
接下来,再来看自动编码器的原理。
自动编码器可以理解为一个试图去还原原始输入的系统,模型如下所示:
它的主要目的是将输入转换为中间变量,然后再将中间变量转化为输出,最后对比输入和输出,使它们二者之间无限接近。
当模型框架中存在瓶颈层或者输入被损坏时,自动编码器能够学习输入本质特征的特性,就可以大显身手了。
在这里,作者主要拿来和扩散模型对比的,便是去噪自动编码器。
它可以将损坏数据作为输入,通过训练来预测未损坏的原始数据作为输出。
看到这里是不是有点眼熟了?
向输入中加入噪声,不就是一种破坏输入的方法吗?
那么,去噪自动编码器和扩散模型,原理上不就是有着异曲同工之妙吗?
二者是如何等价的?
为了验证自己的这一想法,作者从原理方面对扩散模型进行了拆解。
扩散模型的关键,在于一个分数函数 (score function):
需要注意的是,这和下面这个函数不同。(求梯度的参数不同)
通过后者,我们可以知道如何改变模型参数来增加向下输入的可能性,而前者能够让我们知道如何改变输入本身来增加可能性。
在训练过程中,希望在去噪中的每一点都使用相同的网络。
为了实现这个,需要引入一个额外的输入:
由此可以看到在去噪中进行到了哪一部分:
当t=0时,对应无噪声数据;t=1时,对应纯噪声数据。
训练这个网络的方法,就是用添加噪声:
来破坏输入x。然后从这个公式中预测εt:
需要注意的是,在这里方差大小取决于t,因为它可以对应特定点的噪声水平。损失函数通常使用均方误差(MSE),有时会用 λ(t)进行加权,因此某些噪声水平会优先于其他噪声水平:
假设λ(t)=1时,一个关键的观测值为εt或 x(它们二者是等价的),在这里可以用公式:
为了确保它们是等价的,可以考虑使用训练模型sθ来预测εt,并加上一个新的残差连接。从输入到输出的比例系数均为-1,这个调整后的模型则实现了:
由此,一个扩散模型便逐渐变成一个去噪自动编码器了!
One More Thing
不过博客的作者也强调,虽然扩散模型和去噪自动编码器的效果等价,但是二者之间不可完全互换。
并且以上得到的这个去噪自动编码器,和传统类型也有不同:
- 第一,附加输入t可以使单个模型用一组共用参数来处理噪声级别不同的情况;
- 第二,因为更加关注模型的输出,所以内部没有瓶颈层,这可能会导致“弊大于利”的结果。
而作者更想强调的是这二者之间存在的联系。
此外他还表示,模型效果好的关键应该在于共用参数,这种方法已经被广泛应用在表示学习上。
从这些成果中也能发现一个规律:
- 噪声含量越高的模型,往往更容易学习到图像的特征;
- 噪声含量越低的模型,则会更专注于细节。
作者认为以上规律值得进一步研究:
这意味着随着噪声水平逐步降低,扩散模型能够补充图像细节也就越来越多。
最后,我们再来介绍一下这一发现的提出者——Sander Dieleman。
他现在是DeepMind的一位研究科学家,主要研究领域为生成模型和音乐合成。
参与的主要研究工作有Spotify音乐平台的内容推荐模型。
参考链接:
[1]https://benanne.github.io/2022/01/31/diffusion.html
[2]https://twitter.com/sedielem
- 人类一生所学不过4GB,加州理工顶刊新研究引热议2025-04-13
- 北京队再上大分:新AI一句话就能搞开发,代码实时可见 | 免费可用2025-04-15
- 华为云发布CloudMatrix 384超节点 已通过昇腾云正式商用2025-04-10
- 华为昇腾AI云服务四大升级:搭载CloudMatrix 384超节点,性能领先2025-04-11