2040张图片训练出的ViT,准确率96.7%,连迁移性能都令人惊讶
诀窍是转为参数化实例判别
晓查 发自 凹非寺
量子位 | 公众号 QbitAI
ViT在计算机视觉领域取得了巨大的成功,甚至大有取代CNN之势。
但是相比CNN,训练ViT需要更多的数据,通常要在大型数据集JFT-300M或至少在ImageNet上进行预训练,很少有人研究少量数据训练ViT。
最近,南京大学吴建鑫团队提出了一种新方法,只需2040张图片即可训练ViT。
他们在2040张花(flowers)的图像上从头开始训练,达到了96.7%的准确率,表明用小数据训练ViT也是可行的。
另外在ViT主干下的 7 个小型数据集上从头开始训练时,也获得了SOTA的结果。
而且更重要的是,他们证明了,即使在小型数据集上进行预训练,ViT也具有良好的迁移能力,甚至可以促进对大规模数据集的训练。
论文内容
在这篇论文中,作者提出了用于自我监督 ViT训练的IDMM(Instance Discrimination with Multi-crop and CutMix)。
我们先来看一下ViT图像分类网络的基本架构:
将图像样本xᵢ(i = 1, 2, …, N; N为图片数量)送入ViT中,得到一组输出表征zᵢ。wⱼ为第j个分类的权重。
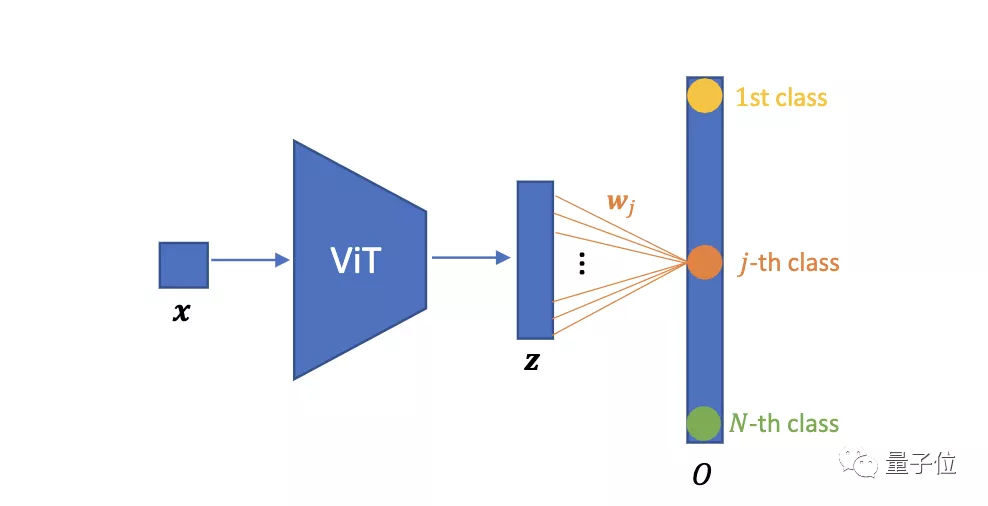
然后,使用全连接层W进行分类,当类的数量等于训练图像的总数N时,即参数化实例判别。
第j类的输出为:
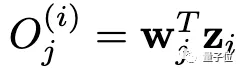
我们把O送入Softmax层,就得到一个概率分布P⁽ⁱ⁾。对于实例判别,损失函数为:
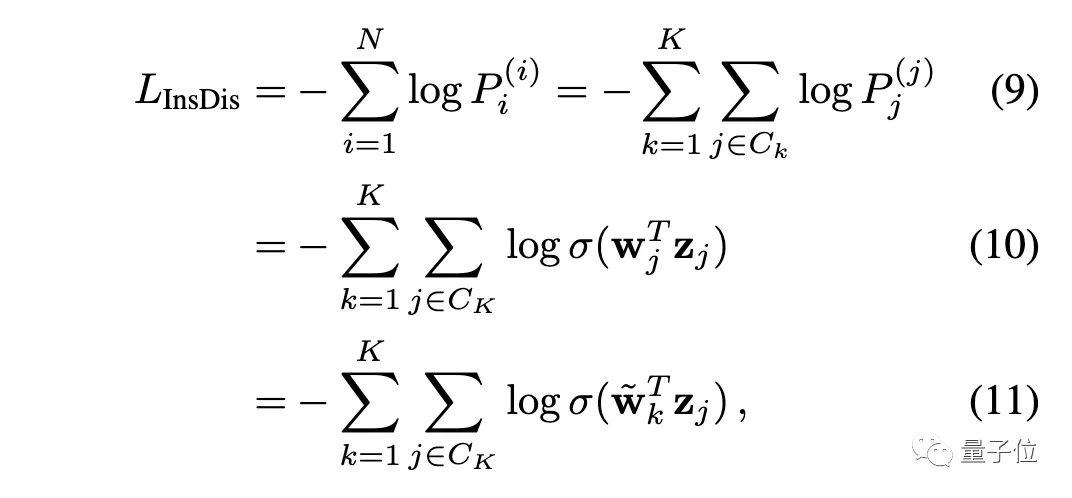
对于深度聚类,其损失函数为:
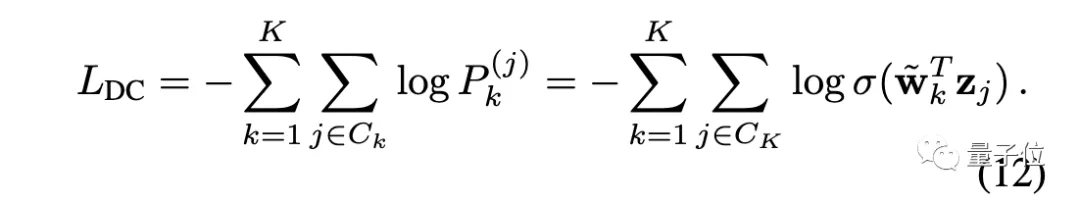
可以看出,只要适当设置权重(让wⱼ = ~wₖ ),就可以让实例判别等价于深度聚类。
从下图中可以看出,与其他方法相比,实例判别可以学习到更多的分布式表征,并能更好地捕捉到类内的相似性。
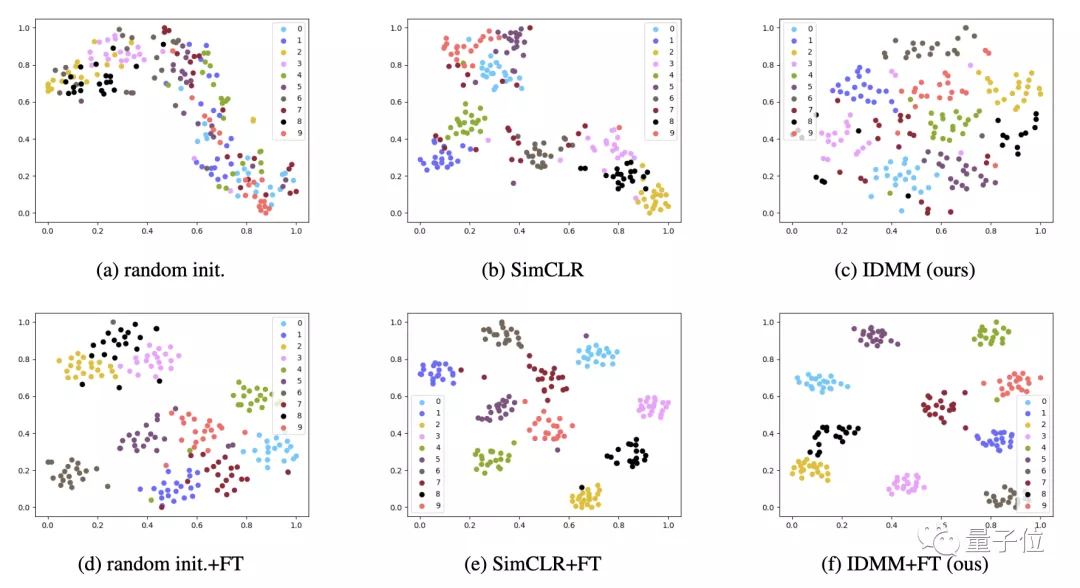
作者之所以选择参数化的实例判别,还有一个重要的原因:简单性和稳定性。
不稳定性是影响自监督ViT训练的一个主要问题。实例判别(交叉熵)的形式更稳定,更容易优化。
接下来开始梯度分析,损失函数对权重求导:
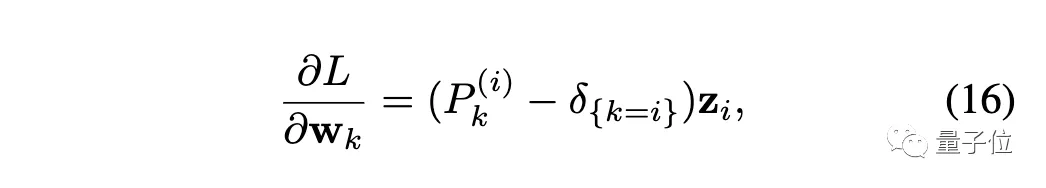
其中δ是指示函数,当k=i时值为1,否则为0。
需要注意的是,对于实例判别,类的数量N通常很大,而且存在对实例样本访问极稀少的问题。
对于稀少的实例k≠i,可以预计P⁽ⁱ⁾ₖ≈0,因此∂L/∂wₖ≈0,这意味着wₖ的更新频率极低。
在小数据集问题上,作者使用CutMix和标签平滑,来缓解此问题。
CutMix:
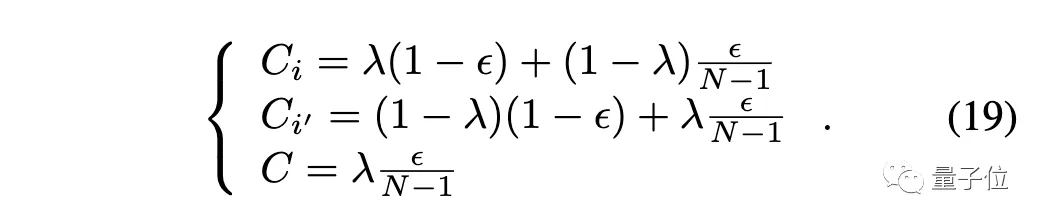
标签平滑:
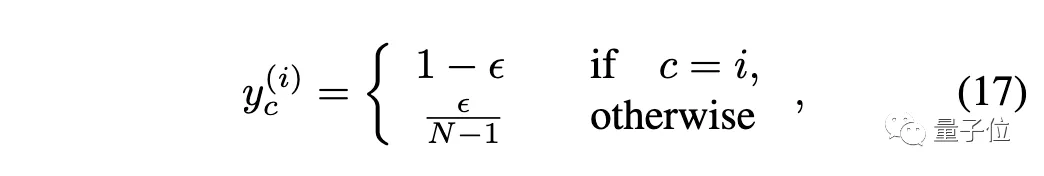
最后梯度变为:
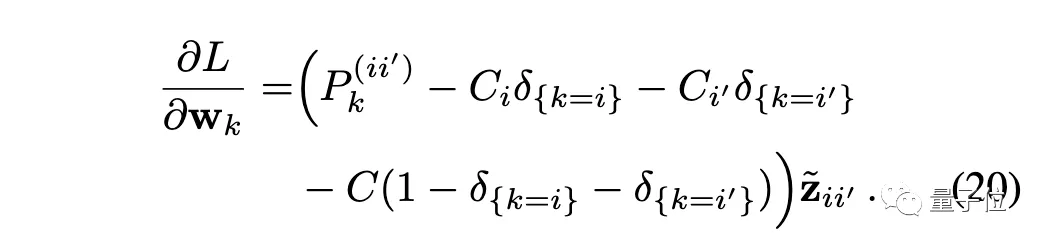
本文第一作者是南京大学在读博士曹云浩,通讯作者是南京大学人工智能学院吴建鑫教授。
总之,作者使用了以下策略来加强小数据集上的实例判别。
- 小分辨率:预训练中的小分辨率对小数据集很有用。
- 多次裁剪:实例判别概括了对比损失,保证了在使用多种实例时获取特征的对齐和统一性。
- CutMix和标签平滑:有助于缓解使用实例判别时的过拟合和不经常访问的问题。
至于为什么需要直接在目标数据集上从头开始训练,作者给出了3点原因:
1、数据
目前的ViT模型通常在一个大规模的数据集上进行预训练,然后在各种下游任务中进行微调。由于缺乏典型的卷积归纳偏向,这些模型比普通的CNN更耗费数据。
因此从头开始训练ViT,能够用图像总量有限的任务是至关重要的。
2、算力
大规模的数据集、大量的耗时和复杂的骨干网络的,让ViT训练的算力成本非常昂贵。这种现象使ViT成为少数机构研究人员的特权。
3、灵活性
预训练后再进行下游微调的模式有时会很麻烦。
例如,我们可能需要为同一任务训练10个不同的模型,并将它们部署在不同的硬件平台上,但在一个大规模的数据集上预训练10个模型是不现实的。
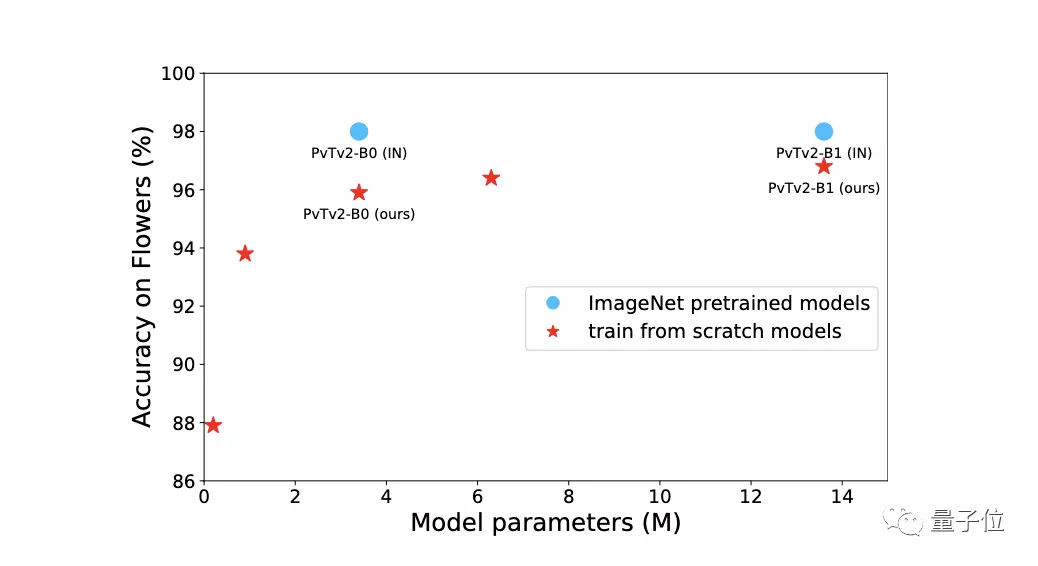
在上图中,很明显与从头开始训练相比,ImageNet预训练的模型需要更多的参数和计算成本。
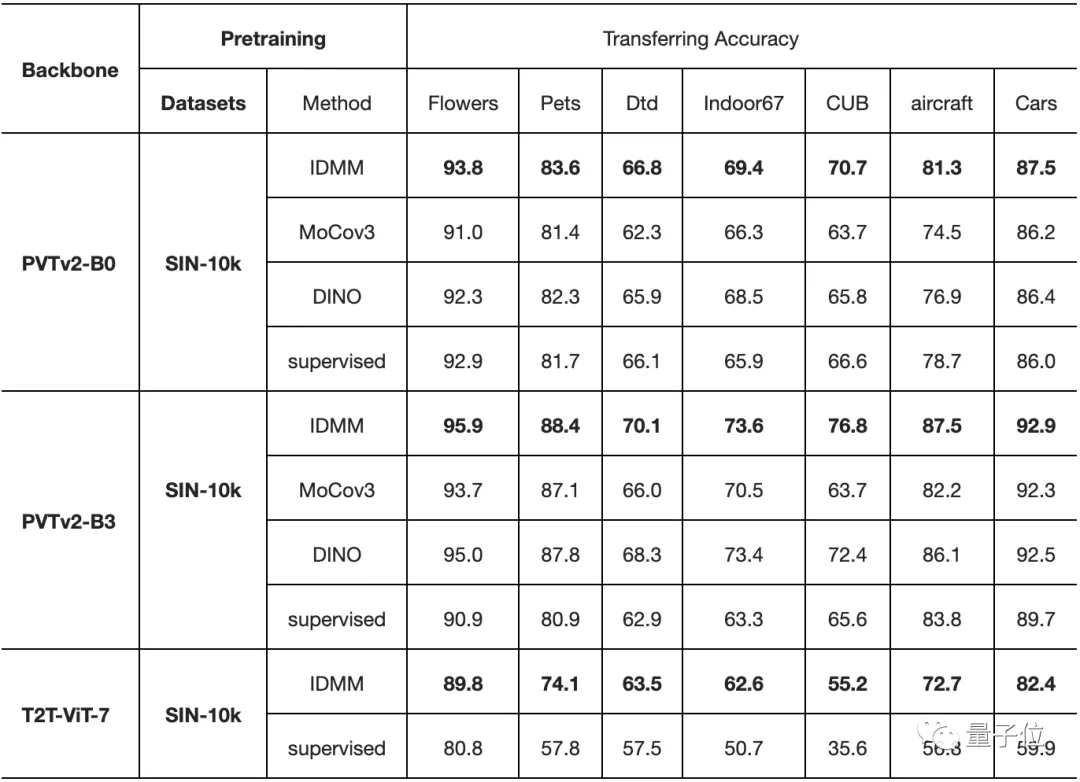
在小数据集上进行预训练时的迁移能力。每个单元格和列中精度最高的元素分别用下划线和粗体表示
最后,在下表中,作者评估了在不同数据集上预训练模型的迁移精度。
对角线上的单元(灰色)是在同一数据集上进行预训练和微调。对角线外的单元格评估了这些小数据集的迁移性能。
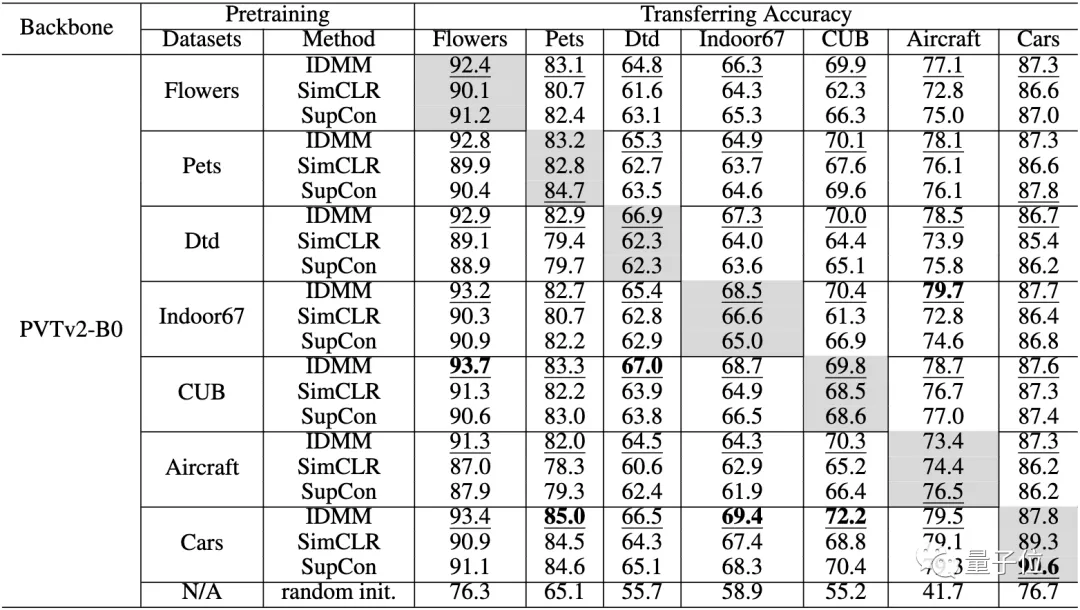
从这张表中,我们可以看到以下几点:
- 即使在小数据集上进行预训练,ViT也有良好的迁移能力。
- 与SimCLR和SupCon相比,该方法在所有这些数据集上也有更高的迁移精度。
- 即使预训练的数据集和目标数据集不在同一领域,也能获得令人惊讶的好结果。例如,在Indoor67上预训练的模型在转移到Aircraft上时获得了最高的准确性。
作者简介
本文第一作者是南京大学在读博士曹云浩,通讯作者是南京大学人工智能学院吴建鑫教授。

吴建鑫本科和硕士毕业于南京大学计算机专业,博士毕业于佐治亚理工。2013年,他加入南京大学科学与技术系,任教授、博士生导师,曾担任ICCV 2015领域主席、CVPR 2017领域主席,现为Pattern Recognition期刊编委。
参考链接:
[1]https://arxiv.org/abs/2201.10728
[2]https://cs.nju.edu.cn/wujx/index.htm
- 脑机接口走向现实,11张PPT看懂中国脑机接口产业现状|量子位智库2021-08-10
- 张朝阳开课手推E=mc²,李永乐现场狂做笔记2022-03-11
- 阿里数学竞赛可以报名了!奖金增加到400万元,题目面向大众公开征集2022-03-14
- 英伟达遭黑客最后通牒:今天必须开源GPU驱动,否则公布1TB机密数据2022-03-05
相关阅读