
万亿大模型究竟怎么用?达摩院&浙大&上海人工智能实验室联手推出洛犀平台:大小模型端云协同进化
须弥藏芥子,芥子纳须弥
鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
AI领域这股大模型之风,可谓是席卷全球,越吹越劲。
单说2021年下半年,前有微软英伟达联手推出5300亿参数NLP模型,后又见阿里达摩院一口气将通用预训练模型参数推高至10万亿。
而就在最近,扎克伯格还宣布要豪砸16000块英伟达A100,搞出全球最快超级计算机,就为训练万亿参数级大模型。
大模型正当其道,莫非小模型就没啥搞头了?

就在“中国工程院院刊:信息领域青年学术前沿论坛”上,阿里巴巴达摩院、上海浙江大学高等研究院、上海人工智能实验室联手给出了一个新的答案:
须弥藏芥子,芥子纳须弥。
大小模型协同进化,才能充分利用大模型应用潜力,构建新一代人工智能体系。
此话怎讲?
这就得先说说大模型“军备竞赛”背后的现实困境了。
大小模型协同进化
核心问题总结起来很简单,就是大模型到底该怎么落地?
参数规模百亿、千亿,乃至万亿的大模型们,固然是语言能力、创作能力全面开花,但真想被部署到实际的业务当中,却面临着能耗和性能平衡的难题。
说白了,就是参数量竞相增长的大模型们,规模太过庞大,很难真正在手机、汽车等端侧设备上被部署应用——
要知道,1750亿参数的GPT-3,模型大小已经超过了700G。
达摩院2022年十大科技趋势报告中也提到,在经历了一整年的参数竞赛模式之后,在新的一年,大模型的规模发展将进入冷静期。

不过在这个“阵痛期”,倒也并非没有人试吃“大模型工业化应用”这只螃蟹。
比如,支付宝搜索框背后,已经试点集成业界首个落地的端上预训练模型。
当然,不是把大模型强行塞进手机里——
来自阿里巴巴达摩院、上海浙江大学高等研究院、上海人工智能实验室的联合研究团队,通过蒸馏压缩和参数共享等技术手段,将3.4亿参数的M6模型压缩到了百万参数,以大模型1/30的规模,保留了大模型90%以上的性能。
具体而言,压缩后的M6小模型大小仅为10MB,与开源的16M ALBERT-zh小模型相比,体积减少近40%,并且效果更优。难得的是,10MB的M6模型依然具有文本生成能力。

在移动端排序模型部署方面,这支研究团队同样有所尝试。
主流的模型压缩、蒸馏、量化或参数共享,通常会使得到的小模型损失较大精度。
该团队发现,把云上排序大模型拆分后部署,可形成小于10KB的端侧精细轻量化子模型,即保证端侧推理精度无损失,同时实现了轻量级应用端侧资源。这也就是端云协同推理。
在阿里的应用场景下,研究团队基于这样的协同推理机制,结合表征矩阵压缩、云端排序打分作为特征、实时序列等技术和信息,构建了端重排模型。
该技术试点部署在支付宝搜索、淘宝相关应用中,取得了较为显著的推理效果提升,且相关百模设计解决了在不牺牲热门用户服务体验的同时,最大化冷门用户体验的难题。

从以上的案例中,不难总结出大模型落地应用的一条可行的途径:
取大模型之精华,化繁为简,通过高精度压缩,将大模型化身为终端可用的小模型。
这样做的好处,还不只是将大模型的能力释放到端侧,通过大小模型的端云协同,小模型还可以向大模型反馈算法与执行成效,反过来提升云端大模型的认知推理能力。
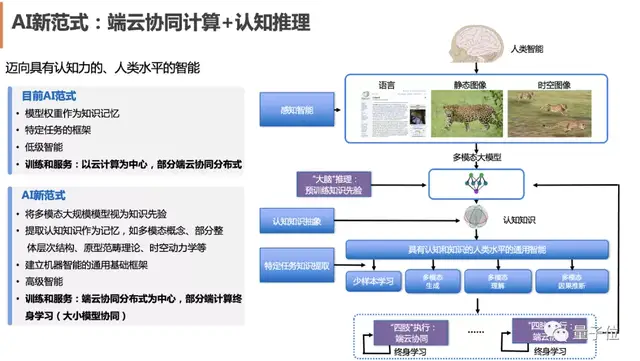
达摩院、浙大和上海人工智能实验室,还进一步将这一技术路线总结为端云协同AI范式:
云端大模型作为超级大脑,拥有庞大的先验知识,能进行深入的“慢思考”。
而端侧小模型作为四肢,能完成高效的“快思考”和有力执行。
两者共同进化,让AI向具有认知力和接近人类水平的智能迈进。
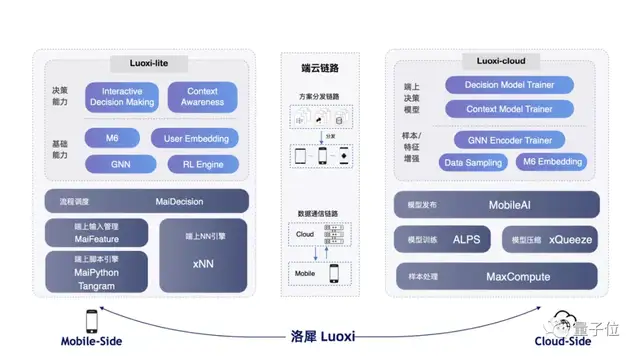
基于这样的思考和实践经验,三方联合研究团队最新推出了端云协同平台洛犀。
该平台旨在将端云两侧的最佳实践以文档、算法组件、平台服务的形式沉淀下来,为开发者提供一站式端云协同模型训练、部署、通信能力。
具体而言,洛犀平台可拆解为端侧、云侧、端云链路三部分。
其中,端侧以Python/js package的形式提供服务,称为Luoxi-lite,包含表征、文本理解、图计算等能力。
端云链路侧,平台提供实现端云协同关键的通信能力,包括方案分发链路、数据通信链路。
端云协同的模型训练沉淀在云端,称为Luoxi-cloud,包含端模型训练等。
目前,除了前文提到的部署于搜索场景的M6模型、排序模型,研究团队还借助洛犀完成了图神经网络、强化学习等技术在端云协同范式下的部署。
值得一提的是,1月12日,洛犀平台中云上大模型核心技术“超大规模高性能图神经网络计算平台及其应用”,获得了2021年中国电子学会科学技术进步奖一等奖。
芥子纳须弥,加速大模型落地应用
说了这么多,简单总结一下就是,大模型展现的效果再怎么惊艳,对于业界而言,终归是落地应用方为真。
因此,对于大模型发展的下一阶段来说,比拼的将不仅仅是谁烧的GPU更多、谁的模型参数规模更大,更会是谁能把大模型的能力充分应用到具体场景之中。
在这个大模型从拼“规模”到拼“落地”的过渡时期,达摩院、浙大、上海人工智能实验室三方此番提出的“须弥藏芥子、芥子纳须弥”的思路,便格外值得关注。
“庞大的须弥山如何纳入极微小的种子中?”
对于当下大模型、小模型的思辨而言,解决了这样一个问题,也就在充分利用大模型能力、探索下一代人工智能系统的路途上更进了一步。
结合历史上计算形态的变化,随着物联网技术的爆发,在当下,尽管云计算模式已经在通信技术的加持下得到了进一步强化,但本地计算需求也在指数级持续涌现,将全部的计算和数据均交由集中式的云计算中心来处理并不符合实际。
就是说,发展既发挥云计算优势、又调动端计算敏捷性的计算模式,才是当下的需求所在。
也正是在这样端云协同的趋势之下,大小模型的协同演进有了新的范式可依:云侧有泛化模型,端侧有个性化模型,两个模型相互协作、学习、推理,实现端云双向协同。
而这,正解决了我们在开头提到的,大模型落地过程中面临的性能与能耗平衡之困。
正如浙江大学上海高等研究院常务副院长吴飞教授所言,从大模型到终端可用的小模型,关键在于“取其精华、化繁为简”,实现高精度压缩;而在端云协同框架之下,小模型的实践积累对于大模型而言,将是“集众智者无畏于圣人”。
你觉得呢?
— 完 —
- SOTA自动绑骨开源框架来了!3D版DeepSeek开源月大礼包持续开箱ing2025-04-11
- 语音界Deepseek!百度最新跨模态端到端语音交互,成本最高降90%2025-04-02
- 从DeepSeek崛起到下一个亿级销量市场,这份硬核报告说明白了2025-04-01
- 宇树机器人侧空翻惊呆网友:“我**想要一个!”2025-03-20











