字节跳动智能创作语音团队SAMI(Speech, Audio and Music Intelligence)近日上线一项高保真、低延迟、高并发歌唱合成技术。该技术在兼顾保真度和速度上实现了一定的突破:一方面,AI模型可以模拟人类独特的音色、技巧和情感,使得演唱效果媲美真人;同时,该模型可以提供超低延迟、高并发的歌唱合成服务,可以轻松适配C端业务场景。
从语音合成到歌唱合成:听见更多AI的声音
语音合成作为人工智能的一个重要分支,已经被应用到大家日常生活的各个方面。它通过输入文字,经由人工智能的算法,合成像人类语音一样自然的音频。而相比于语音,歌唱需要额外的音高,时长信息,且音色也会更为多变。
同基于深度学习的语音合成一样,歌唱合成的模型也由声学模型(acoustic model)和声码器(vocoder)两部分组成,这两部分都采用了完全并行的神经网络架构,从而可以在生成高保真歌唱音频的同时达到25倍实时的生成速度。
通过上述两个模块的配合,对于给定的任意乐谱,都可由神经网络合成对应的歌唱音频;这些音频发音清晰,旋律和节奏准确,音高的衔接流畅,还会出现自然的真假声转换,做到媲美真人的效果:
稍安勿躁(朱兴东版)音频:00:00/00:29
勇气-(棉子版)音频:00:00/00:32
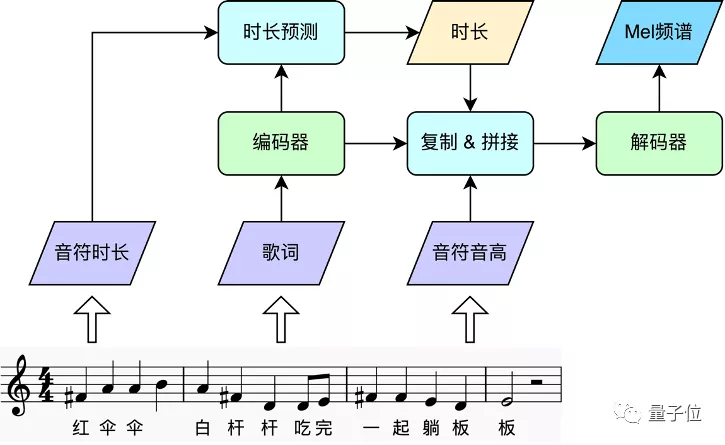
声学模型:将歌词与旋律转换为Mel频谱
声学模型首先从乐谱里得到三要素:歌词、音高、时长;然后通过文本处理前端将歌词转成拼音序列,使用编码器进行编码,得到歌词信息;另一方面,接着根据音符时长,预测每个拼音的时长,并据此将拼音与对应音符音高展开到帧级别,送入解码器生成Mel频谱。
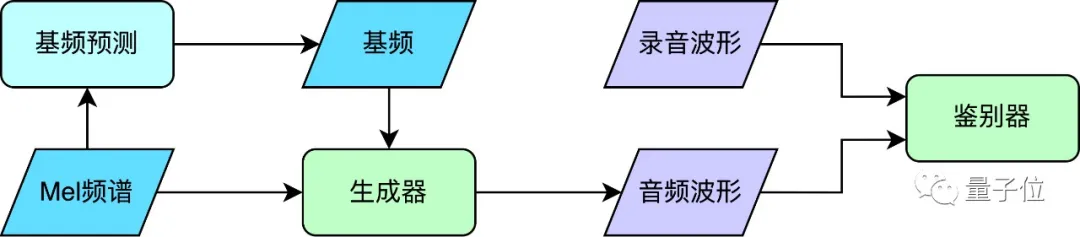
声码器:显式预测音高,生成歌唱音频
得到频谱后,使用基于神经网络的声码器将其转换为音频波形。
目前常见的商用歌声声码器解决方案主要有两种,一种是基于神经网络的串行架构,一种是基于传统数字信号处理的算法;前者可以生成相对自然的音频,但是速度较慢,而后者则相反。为了满足C端场景速度和保真度的双重需求,SAMI团队使用了基于神经网络的并行声码器,既能保证生成高保真的音频,又有极高的推理速度(GPU 200倍实时率),并且表现稳定,不会出现断音爆音等异常。声码器采用了生成对抗网络(generative adversarial network)的架构。其中,对于歌唱而言,旋律的准确性体现为基频(f0)的高低。为了让并行的生成器有稳定的基频,声码器额外增加了独立的“基频预测”模块,其预测的基频作为生成器的强化输入来实现稳定的基频生成。
“你填我唱”:C端互动娱乐场景下的歌唱合成落地方案
音乐创作不仅要求创作者进行文字创作,还要谱写旋律,无形中提高了C端用户的创作门槛。对此,SAMI团队提出了“你填我唱”玩法,让歌曲创作的输入尽可能简化,从而让更多人体会音乐创作的乐趣。
用户只需要输入文字内容并选择音色,接着这些文字会和预置的旋律进行智能匹配,再使用歌唱合成技术,即可实现与旋律的完美融合,并通过合成音色演唱出来。
2021年夏天,一首“红伞伞白杆杆,吃完一起躺板板”让无数人的DNA动了起来。这首歌的旋律取自美国乡村民谣《哦,苏珊娜》,由斯蒂芬·福斯特于1847年创作;而为了提醒广大群众远离毒菌,“云南消防”将歌词改编融入原曲旋律重新演唱,让这首经典歌曲在174年后又火了一把。这种不改旋律,只改编歌词的玩法,大家在儿时起就已经非常熟悉。比如对“太阳当空照,花儿对我笑”这首歌的改编,就是结合了身边发生的一些现象,套用一首耳熟能详旋律,贴近生活又十分有趣。
比如上述的《红伞伞白杆杆》:
01音频:00:00/00:31
当然,也可以脑洞大开,将其他歌曲的歌词交由AI演唱:
脑洞版音频:00:00/00:24
歌唱合成技术的新突破表明人工智能正不断在语音、音乐领域发掘自己的应用场景。有了AI的助力,人人都可以自由自在地表达,让音乐在不同的时代被赋予新的意义,让用户以丰富的声音记录美好生活。