秒秒钟揪出张量形状错误,这个工具能防止ML模型训练白忙一场
首尔大学最新开发PyTea
函擎 发自 凹非寺
量子位 报道 | 公众号 QbitAI
模型吭哧吭哧训练了半天,结果发现张量形状定义错了,这一定没少让你抓狂吧。
那么针对这种情况,是否存在较好的解决方法呢?
这不最近,韩国首尔大学的研究者就开发出了一款“利器”——PyTea。
据研究人员介绍,它在训练模型前,能几秒内帮助你静态分析潜在的张量形状错误。
那么PyTea是如何做到的,到底靠不靠谱,让我们一探究竟吧。
PyTea的出场方式
为什么张量形状错误这么重要?
神经网络涉及到一系列的矩阵计算,前面矩阵的列数必需匹配后面矩阵的行数,如果维度不匹配,那后面的运算就都无法运行了。

上图代码就是一个典型的张量形状错误,[B x 120] * [80 x 10]无法进行矩阵运算。
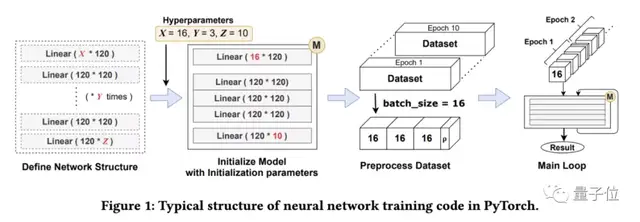
无论是PyTorch,TensorFlow还是Keras在进行神经网络的训练时,大多都遵循图上的流程。
首先定义一系列神经网络层(也就是矩阵),然后合成神经网络模块……
那么为什么需要PyTea呢?
以往我们都是在模型读取大量数据,开始训练,代码运行到错误张量处,才可以发现张量形状定义错误。
由于模型可能十分复杂,训练数据非常庞大,所以发现错误的时间成本会很高,有时候代码放在后台训练,出了问题都不知道……
PyTea就可以有效帮我们避免这个问题,因为它能在运行模型代码之前,就帮我们分析出形状错误。
网友们已经在热烈讨论了。
PyTea是如何运作的,它能否有效地检查出错误呢?
受各种约束条件的影响,代码可能的运行路径有很多,不同的数据会走向不同的路径。
所以PyTea需要静态扫描所有可能的运行路径,跟踪张量变化,推断出每个张量形状精确而保守的范围。
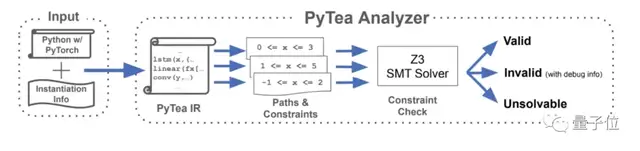
上图就是PyTea的整体架构,一共分为翻译语言,收集约束条件,求解器判断和给出反馈四步。

首先PyTea将原始的Python代码翻译成一种内核语言。PyTea内部表示法(PyTea IR)。
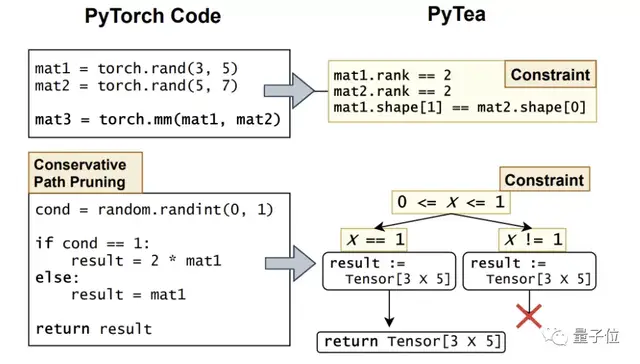
接着PyTea追踪PyTea IR每个可能的执行路径,并收集有关张量形状的约束条件。
判断约束条件是否被满足,分为线上分析和离线分析两步:
- 线上分析 node.js(TypeScript / JavaScript):查找张量形状数值上的不匹配和误用API函数的情况。如果PyTea发现问题,就会停止在当前位置,然后给用户报错。
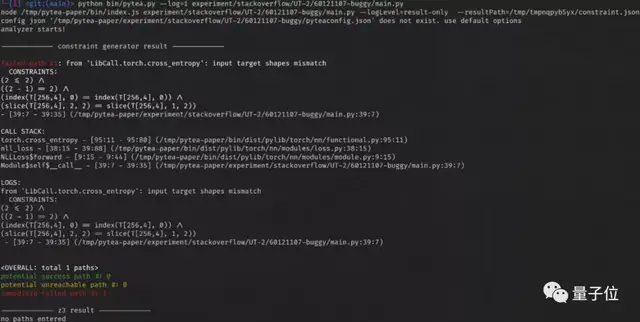
- 离线分析 Z3/Python:如果线上分析没有问题,PyTea将收集到的约束条件传给SMT(Satisfiability Modulo Theories)求解器 Z3,求解器负责查看每条路径的约束条件是否都能被满足,如果不能,返回给用户第一条出错路径的约束条件。
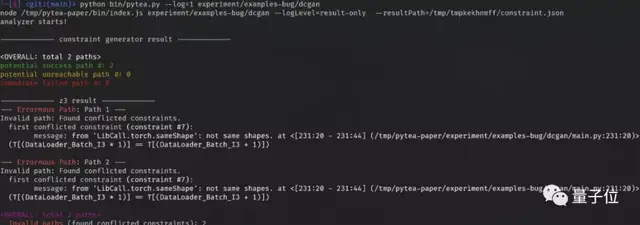
如果求解器过久没有反应,PyTea会返回不知道是否存在问题。
然而追踪所有可能的路径是指数级别的任务,对于复杂的神经网络来说,一定会发生路径爆炸这个问题。

比如说在这个例子中,网络的最终结构是由24个相同模块块构成的(第17行),那么可能的路径就有16M之多。
所以路径爆炸是一定要处理的,PyTea是怎么做的?
PyTea选择保守的地对路径剪枝和超时判断来处理这种路径爆炸。
什么样的路径可以被剪枝?
PyTea给出的答案是,如果该前馈函数不改变全局值,并且它的输出值不受分支条件影响,对于每条路径都是相等的,我们就可以忽略许多完全一致的路径,来节约计算资源。
如果路径剪枝还是不行,那么就只能按超时处理了。
原理就介绍这么多了,感觉还是值得一试的,现在代码已经在GitHub上面开源了,快去看看吧!
使用方法
依赖库:

安装方法:

运行命令:

参考链接:
[1]https://github.com/ropas/pytea
[2]https://arxiv.org/abs/2112.09037
- 教育信创到底怎么选?能做到”无感切换”的只有C862025-04-21
- 清华张亚勤:10年后,机器人将可能比人都多2025-04-21
- 全球首个无限时长视频生成!新扩散模型引爆万亿市场,电影级理解,全面开源2025-04-21
- 具身空间数据技术的路线之争:合成重建VS全端生成2025-04-21