OpenAI又出了一个文本生成图像模型,参数比DALL·E少85亿,质量却更逼真|可试玩
年初DALL·E,年末GLIDE
OpenAI刚刚推出了一个新的文本生成图像模型,名叫GLIDE。
相比今年年初诞生的大哥DALL·E,它只有35亿参数(DALL·E有120亿)。
规模虽然小了,质量却不赖。
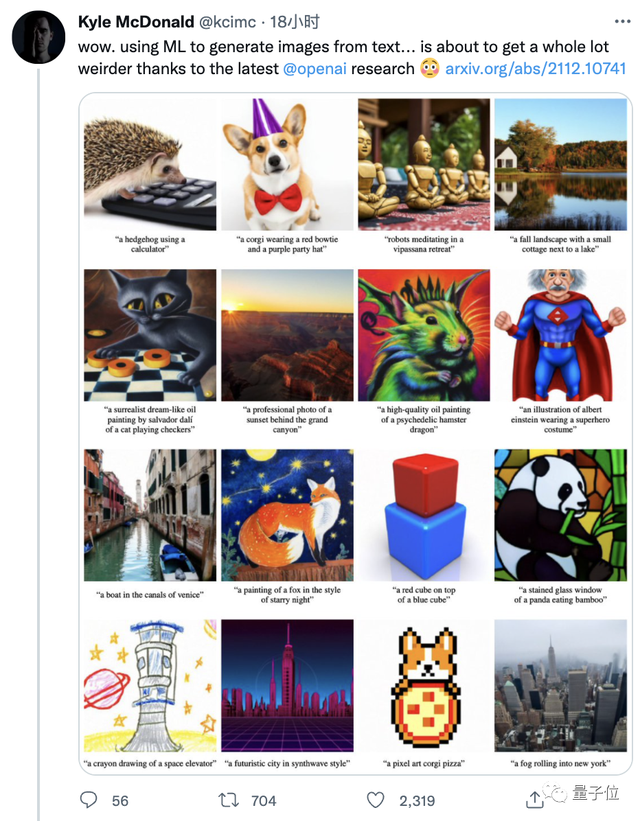
大家仔细看这效果,“使用计算器的刺猬”、“星空下的狐狸”、“彩色玻璃窗风格的熊猫吃竹子”、“太空升降舱蜡笔画”:

是不是很像样儿?
一位码农兼艺术家的网友则形容它“和真的难以区分”。

GLIDE在人类评估员的打分中,确实PK掉了使用CLIP给图片排序的DALL·E。

最有趣的是,这个GLIDE似乎具有“智力”——会否决你画出八条腿的猫的主意,也不认为老鼠可以捕食狮子。

OpenAI岁末新作GLIDE
GLIDE全称Guided Language to Image Diffusion for Generation and Editing,是一种扩散模型 (diffusion model)。
扩散模型最早于2015提出,它定义了一个马尔可夫链,用于在扩散步骤中缓慢地向数据添加随机噪声,然后通过学习逆转扩散过程从噪声中构建所需的数据样本。
相比GAN、VAE和基于流的生成模型,扩散模型在性能上有不错的权衡,最近已被证明在图像生成方面有很大的潜力,尤其是与引导结合来兼得保真度和多样性。
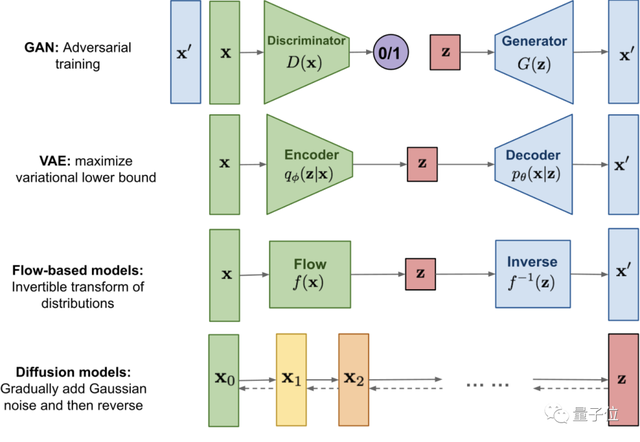
△扩散模型与其他三种生成模型的对比
研究人员训练了一个64×64分辨率的文本条件扩散模型,参数35亿;以及一个256×256分辨率的文本条件上采样扩散模型,参数15亿。
模型有两种引导形式来获得更好的生成效果:无分类器引导(classifier-free guidance)和CLIP引导。
对于CLIP引导,他们还训练了一个噪声感知的64×64 ViT-L CLIP模型 (vit)。
模型采用了SOTA论文《Improved Denoising Diffusion Probabilistic Models》(改进的去噪扩散概率模型)的架构,使用文本条件信息对其进行增强。
对于每个带噪图像xt和相应的提示文本caption,该模型预测出p(xt-1|xt,caption)。
为了对文本进行条件处理,模型还将文本编码为K个token的序列,并将这些token馈送到Transformer中,此Transformer的输出有两个用处:
1、在ADM模型中使用最终token embedding来代替class embedding;
2、token embedding的最后一层在整个ADM模型中分别映射每个注意层的维度,然后连接到每个层的注意上下文。
研究人员在与DALL·E相同的数据集上训练GLIDE,batch size为2048,共经过250万次迭代;对于上采样模型,则进行了batch size为512的160万次迭代。
这些模型训练稳定,总训练计算量大致等于DALL·E。
在初始训练完成之后,研究人员还微调了基础模型以支持无条件图像生成。
训练过程与预训练完全一样,只是将20%的文本token序列替换为空序列。这样模型就能既保留文本条件生成的能力,也可以无条件生成。
为了让GLIDE在图像编辑任务中产生不必要的伪影,研究人员在微调时将GLIDE训练样本的随机区域擦除,其余部分与掩码通道一起作为附加条件信息输入模型。

相比DALL·E,GLIDE的效果更逼真
- 定性实验
研究人员首先比较了GLIDE两种不同的引导策略:CLIP引导和无分类器引导。
分别用XMC-GAN、DALL·E(使用CLIP重排256个样本,从中选择最佳结果)和CLIDE模型(CLIP引导/无分类器引导)在相同的文本条件下生成了一些结果。
CLIDE模型的结果未经挑选。

可以发现,无分类器引导的样本通常比CLIP引导的看起来更逼真,当然,两者都胜过了DALL·E。
对于复杂的场景,CLIDE可以使用修复功能进行迭代生成:比如下图就是先生成一个普通客厅,再加画、加茶几、加花瓶……

此外,CLIDE还可以在SDedit模型上利用草图与文本相结合的方式,对图像进行更多受控修改。

- 定量实验
研究人员首先通过衡量质量和保真度的帕累托边界(Pareto frontier)来评估无分类引导和CLIP引导之间的差异。
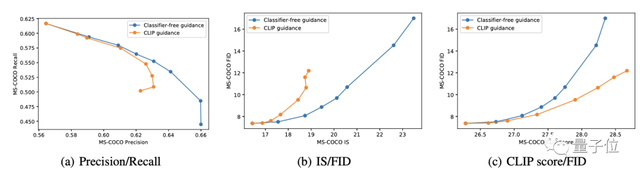
在前两组曲线中,可以发现无分类器引导几乎都是最优的——不管是在准确率/召回率上,还是在IS/FID距离上。
而在绘制CLIP分数与FID的关系时,出现了完全相反的趋势。
研究人员假设这是CLIP引导正在为评估CLIP模型寻找对抗性示例,而并非真正优于无分类器引导。为了验证这一假设,他们聘请了人工评估员来判断生成图像的质量。
在这个过程中,人类评估者会看到两个256×256的图像,选择哪个样本更好地匹配给定文本或看起来更逼真。如果实在分辨不出,每个模型各得一半分数。
结果如下:

无分类器引导产生了更符合相应提示的高质量样本。
同时,研究人员也将CLIDE与其他生成模型的质量进行了评估:CLIDE获得了最有竞争力的FID分数。
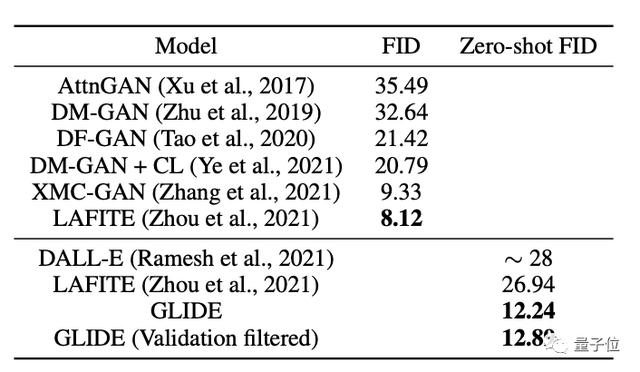
再将GLIDE与DALL-E进行人工评估。
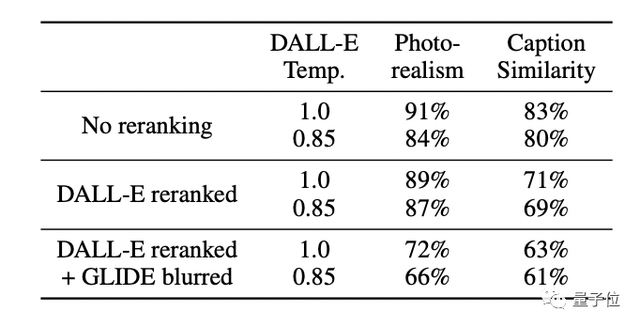
包含三种比法:两种模型都不使用CLIP重排序;仅对DALL·E使用CLIP重排序;对DALL-E使用CLIP重排序,并通过DALL-E使用的离散VAE映射GLIDE样本。
结果是不管哪种配置,人类评估员都更倾向于GLIDE的结果(每项第一行代表GLIDE)。
当然,说这么多,GLIDE也有它的不足,就如开头的例子,它没法画出不合常理的“八条腿的猫”,也就是有智力但缺乏想象力。
此外,未优化的GLIDE需要15秒才能在单张A100 GPU上生成一张图像,这比GAN慢多了。
最后,po一张我们在官方发布的Colab链接上亲手试的一张效果,还凑合(an illustration of a rabbit,demo上的模型比较小):

论文地址:
https://arxiv.org/abs/2112.10741
GitHub地址(是一个在过滤后的数据集上训练的小模型):
https://github.com/openai/glide-text2im
Colab试玩:
https://colab.research.google.com/github/openai/glide-text2im/blob/main/notebooks/text2im.ipynb#scrollTo=iuqVCDzbP1F0
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10