全面覆盖CV任务!这个国产“书生”只学10%内容,性能就超越同行
而且马上就要开源了!
边策 金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
河边有个AI摄像头可以检测偷排污水,能不能顺手让它帮个忙,有人掉河里时也发个警告?
很难。
这要求有更通用的智能,因为对AI来说这是两个完全不同的任务。况且,可用的数据很少。
得有大量人掉河里的数据。可惜素材并不好找。难道让程序员亲自“跳进污水河”来构建一个数据集?
一个看似简单的附加小需求,实则很难且成本很高。
而这就是当下要突破的核心瓶颈:
具备零样本和少样本学习能力的全能AI势在必行。
自然语言领域首先迈出了第一步,GPT-3让我们看到在海量数据下AI举一反三的能力。
现在计算机视觉领域也迎来了一次“变天”。
继通用语言模型的巨大成功之后,在“大力出奇迹”这件事情上,搞计算机视觉的也迈出了这样的重要一步。
上海人工智能实验室联合商汤科技、香港中文大学、上海交通大学共同发布了通用视觉模型(General Vision Model)“书生”(INTERN)。
这位“书生”的学习效率有多高呢?
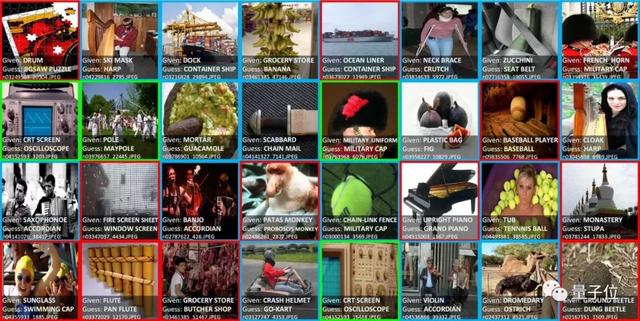
据透露,只要“书生”看过每种花的一两个样本,就能实现99.7%的花卉分类准确率。
也就是说,在开头那个问题中,只要城市的安防摄像头捕捉到一次意外事故,今后AI就可以做到识别和预警。
背负猜想能力“书生”
从通用视觉技术体系的名字来看,团队将其命名为“书生”背后有着这样的一个希冀:
可通过持续学习,举一反三,逐步实现计算机视觉领域的融会贯通,最终实现灵活高效的模型部署。
而现实情况是,过去的CV领域对AI模型的研究多集中于处理单一任务上。
但是随着AI技术在产业中的不断深化,AI的应用也在向复杂的多任务协同演进。
以自动驾驶为例,一套视觉模型要识别各个物体的种类,还要预测障碍物距离、行人可能的运动轨迹。
无论如何,这都是单一视觉模型无法完成的。
同时AI模型还有很多无法顾及的长尾、碎片场景。
举个例子:
某工厂生产线引入AI质量检测技术,希望用摄像头代替肉眼检测次品。但是如果产线的良品率非常高,那么只有极少数次品。
我们都知道,一般AI模型在数据不足的情况下,会导致训练不足,错误率高。在这种情况下,AI模型很难达到很难部署到产线上。
过去的做法是开发特定模型用于不同这类特殊碎场景,AI的应用成了专家才能参与的“作坊式”开发。
如果有一个通用AI模型,只需针对不同环境做微调,就能立即适应,便可以摆脱“作坊式”开发的低效率模式。
通用视觉模型“书生”应运而生,它已经在训练阶段“吃进”大量数据成为通才,只需要看到少量样本,就具备了“举一反三”的能力。
在自动驾驶、智能制造、智慧城市中还有很多类似的“长尾”场景,它们的共同点都是数据获取通常困难且昂贵。
通用视觉“书生”为打破了AI在以上场景中应用提供了可能。
而且从实验结果来看,“书生”的路数也在印证这种方式的正确性。
它能够同时解决图像分类、目标检测、语义分割、深度估计四大任务,而且做到样样精通。
例如与当今最强的开源通用模型CLIP相比,在CV领域的四大任务26个数据集上,“书生”的平均错误率分别降低了40.2%、47.3%、34.8%和9.4%。
和CLIP一样,“书生”也需要强大算力作为支撑, SenseCore商汤AI大装置恰好派上用场。
今年商汤宣布在上海临港的AIDC投入运营,这是目前亚洲最大的人工智能算力中心,仅仅是商汤AI大装置的一部分。
在商汤CEO徐立看来,AI大装置是推动机器猜想的一个基础要素。那么“书生”则是在此基础上背负商汤“猜想”能力的具体实现。
通才“书生”是怎么炼成的?
整体而言,“书生”这个视觉通用体系包含七大模块——三个基础设施模块和四个训练阶段模块。
其中,三个基础设施模块分别为:
- 通用视觉数据系统
- 通用视觉网络结构
- 通用视觉评测基准
它们三个就像是“藏经阁”一样,奠定了在通往通才道路上海量知识和建模等能力的基础。
例如通用视觉数据系统就包含了一个超大规模视觉数据集,拥有100亿个样本和各种监督信号。
它还提出了一个广泛的标签系统,包括11.9万个视觉概念,可以说是涵盖了自然界的众多领域和目前计算机视觉研究中的几乎所有标签。
通用视觉网络结构,则提供了强悍的建模能力。
具体而言,它是由一个具有卷积和Transformer运算符的统一搜索空间构建而成。
通用视觉评测基准就像是一个“擂台”,收集了4种类型共26个下游任务。
在此基础上,让“书生”产生的模型和已公布的预训练模型同台竞技。
并且这个“擂台”还引入了百分比样本(percentage-shot)的设置,如此一来,下游任务训练数据被压缩的同时,还可以很好地保留原始数据集的长尾分布等属性。
但也正如刚才提到的,除了基础设施模块之外,“书生”还有四个训练阶段模块。
而这条路径所采取的是一种阶梯式学习的方法。
其中,前三个训练阶段是属于技术链条的上游,主要的发力点是在表征通用性方面。
它们分别叫做基础模型(Amateur)、专家模型(Expert)和通才模型(Generalist)。
在基础模型阶段,如其名,要做的事情就是让“书生”打下广泛且良好的基础。
具体而言,它是一个获取基础模型的多模态预训练阶段,也就是同时使用来自图像-文本、图像-图像和文本-文本对的监督信号来训练任务,并诊断模型。
而在基础模型阶段“历练”后得到的输出,将作为下一阶段,即专家模型的初始化输入。
专家模型要培养的是“书生”的专家能力,也就是让多个专家模型各自学习某一领域的专业知识。
主要是通过多源监督(multi-source supervisions)的方式,来积累某个类型任务中的专业知识。
值得一提的是,在这个过程中每位专家只关注自己的专业,不干扰“其他人”的学习。
上游的第三个阶段,便是通才模型。
它是一个组合式的预训练阶段,这个阶段的结果就是产出一个通用模型。
这个模型整合了专家的知识,并生成能够处理任何已知或未知任务通用表示的最终形式。
在经历了前三个训练阶段模块后,便来到了最后的泛化模型 (Adaptation)。
这个阶段属于技术链条的下游,用来解决各式各样不同类型的任务。
而这也是最考验“书生”举一反三能力的时刻。
换言之,它需要在这个阶段把之前学到的通用知识,融会贯通地应用到特定的不同任务中去。
以上便是“书生”这个通用视觉技术体系完整的一套流程,它的全景如下图所示:
总而言之,在“书生”炼成之后,便是有了一种“兵来将挡”的味道了。
无论是面对智慧城市、智慧医疗、自动驾驶,亦或是未知领域,“书生”都能以专家的实力来迎刃而解。
像“书生”这样实现以一个模型完成成百上千种任务的新范式,体系化解决人工智能发展中数据、泛化、认知和安全等诸多瓶颈问题。
而这只是“书生”在算法层面上的炼就功法,但对于大模型来说,算力也是非常重要且必要的硬性要求。
这就不得提到商汤早在数月前发布的SenseCore AI大装置。
它可以说是商汤引擎的底层架构了,可以类比为整个引擎夯实有力的地基。
具体而言,先从算力角度来看,商汤通过结合AI芯片以及AI传感器,构建了亚洲最大的人工智能智算中心(AIDC)。
这个AIDC的计算峰值可以达到3740Petaflops (1 petaflop等于每秒1千万亿次浮点运算),相当于一天处理时长达到23600万年!
除此之外,从平台角度来看,AI大装置打通了从数据处理、模型生产、模型训练、高性能推理运算,以及模型部署等等各个环节。
而且不同于其它厂商采用开源工具,商汤这“一整套”都是自研的,具备更强的适配性,更利于模型的部署和应用。
如此一来,在算法、算力、平台“三位一体”之下,便可明显区别于“小作坊式”的模型打造方式了。
但毕竟常言道学无止境,那么已经具备如此实力的“书生”,还能通过怎样的方式来提高自己呢?
“书生”还要加码开源的力量
从人工智能技术发展的历史长河来看,多数主流AI工具都具备一个共性——开源。
开源的力量可以说是不言而喻了,越开放、越分享,就会越发让AI工具具备活力。
而这,也是“书生”要做的一件事情:
基于“书生”的通用视觉开源平台OpenGVLab也将在明年年初正式开源。
更具体的,上海人工智能实验室联合商汤要将向学术界和产业界公开的不仅仅是预训练模型,还包括它的使用范式、数据系统和评测基准等。
但“书生”的开源布局图还不止于自身。
OpenGVLab将与上海人工智能实验室此前发布的OpenMMLab 、OpenDILab一道,共同构筑开源体系OpenXLab。
其背后所要实现的目的,就如商汤所说的,持续推进通用人工智能的技术突破和生态构建。
从涉足领域来看,这个生态里,应该包括了智慧城市、智慧医疗,也包括了自动驾驶和智能交通……
开源的“书生”,仗剑变革,前景广阔。
论文地址:
https://arxiv.org/abs/2111.08687
- 教育信创到底怎么选?能做到”无感切换”的只有C862025-04-21
- 清华张亚勤:10年后,机器人将可能比人都多2025-04-21
- 全球首个无限时长视频生成!新扩散模型引爆万亿市场,电影级理解,全面开源2025-04-21
- 具身空间数据技术的路线之争:合成重建VS全端生成2025-04-21