
教自动编码器学会「自我纠正」,DeepMind提出语言模型“SUNDAE”
WMT14英德互译任务获SOTA
一直以来,自回归语言模型(Autoregressive model,AR)在文本生成任务中表现都相当出色。
现在,DeepMind通过教自动编码器学会“自我纠正”,提出了一个叫做“圣代”(SUNDAE)的非自回归模型。

它不仅能在WMT’14英德互译任务中取得非自回归模型中的SOTA,还表现出与自回归模型相当的性能。
更厉害的是,还能轻松做到自回归模型做不到的事儿——文字补全。

要知道,非自回归模型一直不被看好。
而这个“圣代”的文字补全功能,也为人类和机器共同编辑、创作文本提供了新的途径。
非自回归语言模型“圣代”
“圣代”全名“逐步展开降噪自动编码器”(Step-unrolled Denoising Autoencoder,SUNDAE),作为一种新的文本生成模型,它不依赖于经典的自回归模型。
与降噪扩散技术(denoising diffusion)类似,“圣代”在训练期间采用展开降噪(unrolled denoising),将一系列token重复应用,从随机输入开始,每次都对其进行改进,直至收敛。
这就是所谓的“自我纠正”过程。

下面用一张图来说明一下降噪和展开降噪的区别。
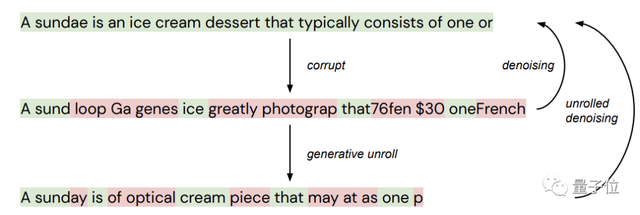
第一行为原始文本,它被随机“污染”(corrupt)后产生新的文本(第二行),其中绿色的token代表“未污染”文本,红色代表“污染”文本。
这个中间文本再通过降噪(从生成模型中采样),生成底部的又一个“污染”文本。
标准降噪自动编码器只学习从中间文本到顶部文本的映射,逐步展开降噪自动编码器(“圣代”)则会学习从底部到顶部的映射。
而在文本生成期间,网络遇到的大多数文本都并非像上图中间那样,而是底部那种,所以展开降噪是非常有用的。
此外,研究人员还提出了一个简单的改进算子,它能实现比降噪扩散技术收敛所需的更少的迭代次数,同时在自然语言数据集上定性地生成更好的样本。
直白的说,“圣代”采用的方法让文本合成的质量和速度都变得可控了。
在机器翻译和文本生成任务上表现如何?
下面就来看看“圣代”的具体表现。
研究人员首先在机器翻译基准上评估“圣代”。
使用BLEU分数作为衡量标准,将“圣代”在WMT’14德英互译任务上的翻译质量与自回归模型(AR)和非AR模型进行比较。
结果发现,在不使用序列级知识蒸馏等技术的情况下,“圣代”的性能几乎与AR模型相当,并且打败了所有非AR模型。

接着是对“圣代”在文本生成任务上的评估。
研究人员在大型高质量公开数据集 Colossal Clean Common Crawl (C4) 上训练“圣代”。
模型一共包含335M参数,24层,embedding size为1024 , hidden size为4096 , 以及16 个attention head,使用bacth size为4096的Adam optimizer训练了多达40万步。
最终生成的文本如下,未经cherry pick:
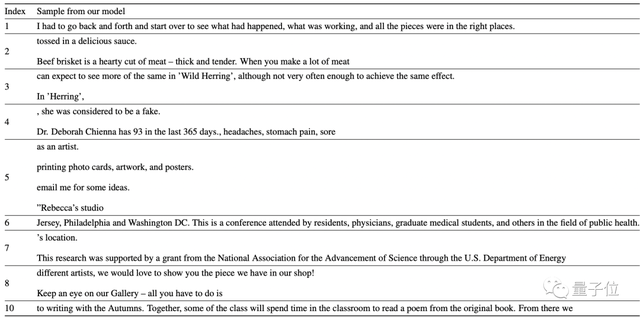
这10句里面,除了第4,都挺合理。
不过由于C4数据集来自网络,所以无论是训练集还是生成的最终结果,换行符都挺多。
此外,由于“圣代”模型的非自回归性,研究人员也测试了它的文本“修复”能力。
要知道,这对于只能从左到右按序生成的AR模型来说根本就办不到。
结果如下(cherry-pick过):
- C4数据集

- GitHub上的Python程序组成的数据集

大家觉得这效果如何?语法和逻辑似乎都没有问题。
更多数据和内容欢迎戳下方链接。
论文地址:
https://arxiv.org/abs/2112.06749
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10










