谷歌让NLP模型也能debug,只要给一张「草稿纸」就行
语言模型的计算能力上去了
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
现在的大型语言模型,能力个个都挺强。
但,它们的计算能力都不太行:
比如GPT-3,没法做超过三位数的加法。
再比如它们当中的大多数都可以写代码,但是理解代码却很费劲——稍微遇到点带循环的程序就gg。

不过,来自MIT和谷歌的研究人员发现:
不用修改模型的底层架构,只需训练它们学会像程序员debug时那样“打断点”,读代码的能力就唰唰唰地涨上去了。

将同样的思路用于大数加法、多项式计算,那就更不在话下了。
所以,语言模型的数学能力终于也要跟上了?!
教语言模型用“打断点”的方法做加法、读程序
前面说的“打断点”,其实指的是在计算步骤较多的程序中,让模型把每一步都编码为文本,并将它们记录到一个称为“便签”的暂存器中,或者叫“草稿纸”。
听起来是个“笨”方法,但正是这样才使得模型的计算过程变得清晰有条理,性能也就比以往直接计算的方式提升了很多。
具体操作也很简单。
就比如在简单的加法计算中,计算“29+57”的方式就是像这样的:

其中C表示进位,#表注释。
先计算9+7,进位1;再计算2+5+进位1,最后得出86。
从上可以看出,这个训练示例由“输入”和“目标”组成。
训练时将两者都喂给模型;测试时,模型就能根据“输入”预测出正确的“目标”。
而“目标”就是要发送到临时暂存器上的内容,通过关注其上下文就可以引用;实际操作中,还可以对“草稿”内容进行检查纠错。
显著提高语言模型的计算能力
研究人员选用了仅含解码器结构的Transformer语言模型来实验,其参数规模介于200万到1370亿之间。
原则上,任何序列模型都可以使用这个方法,包括编-解码器模型或循环网络等。
首先,他们按这种“打断点”的方式训练语言模型进行1-8位数的整数加法。
训练包含10万个示例,并进行了5000步的微调,batch size为32。
然后分别用1万个数据来测试训练分布内的加法;1千个数据来测试训练分布之外,也就是9位和10位数的加法。
将结果分别与直接运算的语言模型进行比较,发现:
即使超出临界模型大小,用了“打断点”法的模型也能够进行加法运算,而直接运算的基线模型就没法做到这一点。
而在分布外的任务中,直接运算的基线模型完全挂掉——“没练过就不会做”,而用了“断点”法的模型随着规模的增大hold住了9-10位数的加法。
好,大数加法搞定。
接下来上多项式。
他们生成了一个包含1万个多项式的训练数据集和2000个数据的测试集。
其中项数一般不超过3项,系数范围在-10到+10之间,结果在-1000到+10000之间。
多项式的训练示例如下:

结果发现:无论是微调还是少样本训练之后,“断点”法的性能都优于直接预测。
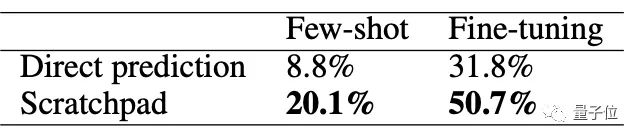
最后就是读Python代码了。
代码的训练示例中,记录了正在执行的是哪行代码,以及此时各变量的值,用json格式表示。

此前的语言模型读代码的能力都表现不佳。“打断点”的方式可以让它们一改常态么?
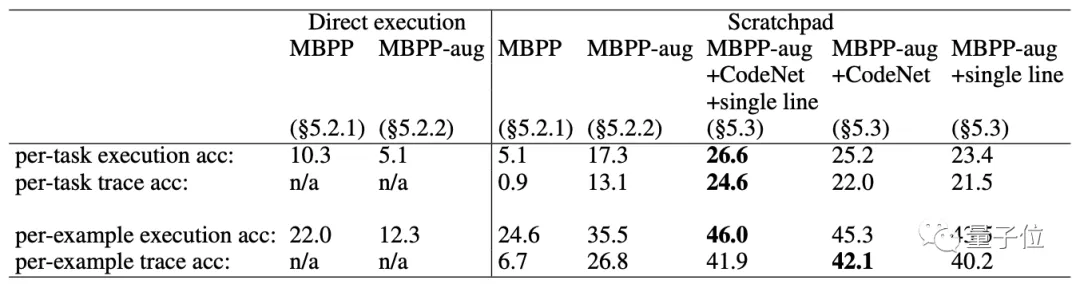
首先,经过200个程序(都是人工编写的,包括简单的while循环和if语句)的测试发现,“断点法”整体执行精度更高。
与直接执行的模型相比,微调还可以将模型性能从26.5%提高到41.5%。

一个真实例子:
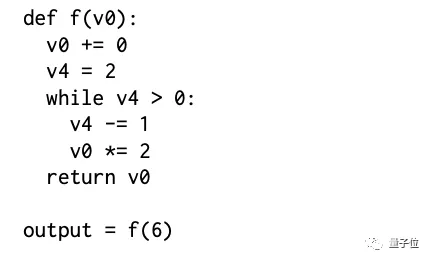
“断点”法经过3次while循环,最终给出了正确的变量值。

接着,他们又用包含了1000个程序的MBPP数据集进行训练和测试。
这些程序涉及多种数据类型的计算,包括整数、字符串、浮点数等,以及涉及循环、API调用和递归等流程结构。
并添加训练数据之外的“single line”程序集和CodeNet程序集进行测试。
结果发现,模型也可以很好地扩展。
当然,这个方法也有局限性:
比如复杂的计算可能需要很“长”的暂存器,这可能需要进一步改进Transformer生成窗口的大小。好在这也是NLP领域的一个活跃研究领域。
而在未来,他们可能会尝试在无监督情况下用强化学习让语言模型学会“打断点”。
总之,语言模型的计算能力、读代码的能力会越来越强。
论文地址:
https://arxiv.org/abs/2112.00114
— 完 —
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10