李佳琦一晚卖了100亿,有位“硬汉”在背后默默发力
称得上“国货之光”的数据库
金磊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
“美眉,来喽,来喽,上链接!”
话音刚落。
“没了,全没了,都被抢光喽!”

头部主播李佳琦,一夜100亿元销售额这件事,着实震惊了不少人。
而经历过这位“大魔王”双11预售的友友们,或多或少肯定是见过刚才这种名场面了。
短短1秒不到的时间,数万甚至更多商品瞬间被抢了个精光。
从下单到支付,那叫一个一气呵成,卡顿一点点都得被抢购大军甩开十万八千里。
……
但你有没有想过一个问题:
为什么在这么短时间,面对如此高流量,付款却又是这般丝滑?
不卖关子,上答案。
因为在李佳琦疯狂卖货的背后,一直有位“硬汉”在默默发力。

它叫做OceanBase,是蚂蚁集团自主研发的纯国产数据库。
至于它的能力,讲真,让李佳琦直播带货体验变得丝滑“无感”,这都是小儿科了。
毕竟,OceanBase可是顶得住每年双11支付、金融级场景超级大流量狂虐的那种数据库。
经得起双11考验的OceanBase
先来感受一下历年双11成交额的恐怖增长。

光是去年的成交额,就达到了4982亿元之多。
什么概念?平均到双11当天每秒的成交量,那就是:
每秒58.3万笔订单!
而在如此海量又迅猛的交易面前,数据库就成了交易是否能够丝滑完成的关键。
这是为什么?
先来简单科普一下数据库在这个过程中起到的作用。
我们可以把数据库当做是一个“账本”,当一个客人在店里买了一瓶酱油,作为店主的你,是不是得在账本上记账?
何时何地、谁、买了什么、单价多少、交易是否成功、还剩多少瓶酱油……

所有与这次交易相关的信息,都得一五一十地纪录在这个账本中。
看似简单的流程,但往往会出现各式各样的问题,比如人数。
一个客人还好应付,但如果同一时间,客人一窝蜂的到店里,挤成一团吆喝着“快点记账”呢?
若是店里只有零星的几个账本,那你只能无奈地回应:“请……排……队……”。

再例如,即便你“奋笔疾书”,但订单源源不断,把整个账本记得满满当当呢?
那你只能跟后边的客人说:“抱歉,账本满了,没法再交易了。”
再或者你记账的时候写太快了,漏掉了哪点信息,或者把信息写串行了,那这几笔交易可就乱套了。
……
所以,这个账本,也就是数据库,在整个交易过程中,就显得尤为重要。毕竟在金融支付行业当中有一句话:
账目是支付系统皇冠上的明珠。如果一个系统可以被应用在账目上,那么意味着它有能力应对所有系统。
而阿里巴巴,更准确点来说,是它使用的交易系统支付宝,所采用的数据库,正是OceanBase。

但就像刚才提到的,像双11这种大促,数据库所面临的压力,在全球范围来看都是数一数二的。
也就是说,即便客人、交易再多,支付宝的“账本”也不许出现让客人排队、账本不够用,甚至账本出错等问题。
但仔细回忆一下,每年双11剁手的时候,支付过程似乎都是非常丝滑无感的(除非没抢到)。
而这,便归功于OceanBase经过数年考验,所沉淀下来的十八般武艺了。
整体来看,它的核心能力包括四点。
首先,是数据一致性。
这一点,不仅是对于OceanBase,对任何一个数据库来说,都是最基础但又是最难修炼的“功法”。
还是以酱油为例,假设它在数据库中有2张表,分别是商品类型和商品品牌。
当商店里进了一批酱油,那你就需要在商品类型里插入“酱油”属性,然而这个酱油是刚刚上市的新牌子,需要在商品品牌表里新增对应的牌子。
但如果没有数据一致性,那就会出现一个“没有牌子的酱油”了。

因此,每当在事务完成的时候,必须保证所有数据都具有一致的状态。
OceanBase便具备数据块级实时校验、事务级实时校验、副本级定期校验等特性。
而且数据一致性,必须是在任何情况下都得满足的一点,而不是说能应付某次任务就行的那种。
为此,OceanBase的数据一致性,还具备运行连续的特点。
具体来说就是在高并发场景不会出现抖动、在极端异常场景下无损容错,以及还内置灰度变更的能力。

其次,是极致弹性。
在双11这种大促场景下,当天所需要的数据的容量,是平时的几十倍,普通机房在这种量级面前是招架不住的。
而OceanBase则修炼了快速上云、下云的功力,这便是所谓的弹性。
当需要超大数据库容量的时候,OceanBase可以飞速的将数据、服务部署到云上;而当不需要这么大容量时,就又可以飞速的从云上撤下来。
这个过程听起来非常简单,但实际上对于数据库来说,是一件非常有挑战的事情。
不论是上云还是下云,绝对不可能是一个一个地“拷贝”,定然海量并行,这个过程基本涉及了接近50万次的变更操作。
而所有的操作,绝对不能对业务产生任何的影响,是有种“一步错便天下大乱”的感觉了。
第三,是极致容量。
刚才我们也提到,去年双11平均每秒的成交量是58.3万笔。
但其实这个数字对于OceanBase来说并不算什么,因为它的真实实力,是能hold住每秒100万笔订单支付的那种。
这个数字对于一个数据库来说,可能就是接近亿级的QPS(每秒查询率)。
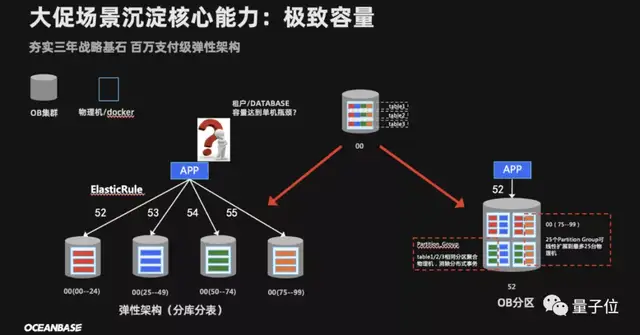
为了应对这种难题,OceanBase采用的是两级弹性架构。
第一级数据库经常会采用的分库分表,也就是从单个数据库拆分成多个数据库、从单张表拆分成多张表。
这样一来,就可以把数据“打散”处理,降低每个数据库的QPS。
除此之外,OceanBase还基于此做了一个“中间件”,它的作用就是避免重复劳动。
上述过程拆过一次,以后就交给OceanBase自动扩容就可以了。
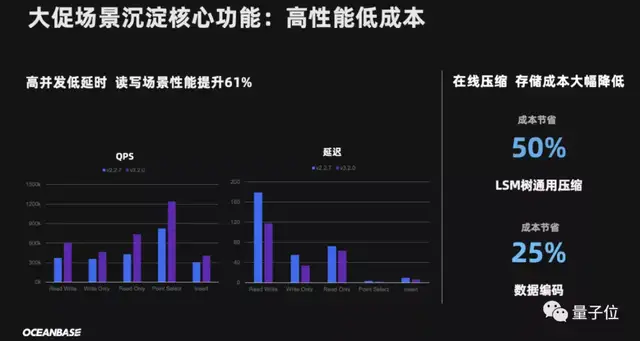
最后,是高性能低成本。
光是数据库能力上去还不行,还得考虑成本的问题,毕竟数据存储和管理花费巨大,已经成为了业内不争的事实。
而OceanBase可以说是那种“既能干又省钱”的数据库。
光是与去年相比,在性能提升61%的情况下,诸如LSM树通用压缩成本节省50%、数据编码成本节省25%。
……
由此可见,OceanBase确实是一个经得起双11考验的数据库了。
更强版本来袭,但今年没上“战场”
今年刚刚过去的双11,成交额数据再创新高。
那么问题来了:
OceanBase是否还能依旧坚挺?
答案很明显是肯定的。
OceanBase自6月1日宣布步入“3.0时代”后,目前已经3.2版本。
但是划重点——今年没用最新版!
理由很简单:因为现在的OceanBase就已经完全能hold住了。
不过既然升到了最新版本,也是有必要了解一下更强的性能。

从数据层面来看,OceanBase3.2的性能可谓是猛增。
在相同环境和任务下,与3.1版本相比:
- Sysbench OLTP 性能提升24%
- BMSQL tpmC 性能提升30%以上
- TPC-H 性能提升655%
而且OceanBase以前的目标可能就是如何撑住双11,解决的是一种纯粹的交易类问题。
而将来则不同,OceanBase剑指更智能和更实时。

智能化方面,就是通过AI的能力自动发现问题,而且还把诊断和决策“权利”,也一并交给OceanBase自己来处理。
以往我们看到的双11“战场”上,都会有众多一线员工把守,生怕突发一些重大问题。
但以后就不一样了,甚至身兼要职的OceanBase CTO杨传辉都表示:
我不用去了!
这份自信,也是可见一斑了。
而在实时化方面,以往很多人会认为双11只是一个交易的场景,但其实细看下来,它还是一个实时智能分析的场景。
因为在双11的时候,是要对商家做分析的,以往的方式在交易完成之后会到数据仓库里再做分析,这就需要消耗很长时间才能得出结果。
而理想的状态是什么呢?当然就是交易完立即出分析结果。
而现在,这已经不是一种理想了。
OceanBase3.2把很多对商家分析的工作,整合到了一套HTAP(混合事务和分析处理)系统里面,既可以做实时交易又可以做实时分析。
这里需要补充解释的是,HTAP是OceanBase主打的数据库类型。
而目前市场主流的是OLAP(联机实时分析)和OLTP(联机事务处理)两种类型。
HTAP作为“新起之秀”,不仅打破了OLAP和OLTP之间长久以来固有的隔阂,而且在复杂场景中的优势也是显而易见。
就目前来看,OceanBase对这条道路的选择是持坚定不移的态度。
而从上结果来看,能hold住全球数一数二复杂场景的OceanBase,是迈出了正确的一步。
从一个收藏夹开始,走向世界
现在的OceanBase,说是发展到全球最强原生分布式数据库方队也不足为过。
除了能轻松应对双11这种“超高压”场景,在全球权威的性能测试TPC-C上,也是独占鳌头。

国产原生分布式数据库打破了巨头Oracle、IBM等集中式数据库,长期垄断全球数据库的局面。
2019年,OceanBase以6088万tpmC的在线事务处理性能创造了世界纪录,终结了Oracle九年的霸榜。
而时隔仅1年,又以7.07亿tpmC的成绩,刷新了自己的纪录。
……
但谁又能想象,就是这样“功成名就”的数据库,它的起点却是一个小小的“收藏夹”呢。

故事还要从2010年开始讲起。
在这一年,OceanBase在淘宝正式立项,但当时的情况是却是“一无所有”。
但唯有一点是贯穿至今的,那就是它要走的路线——分布式系统。
简单来讲,就是把大活变成多个小活一起来搞。
而关于路线的确定,就不得不提一个人了,OceanBase创始人阳振坤。
在他看来,分布式系统就是数据库的未来:
相比于集群等已有的模式,分布式系统具备更“抗压”、“无限大”等优势。
项目和路线是确定了,但技术嘛,“实践才是检验真理的唯一标准”。
但这也成了OceanBase迈出第一步的最大阻碍——没人敢用。
即便阳振坤和小伙伴们,像销售一样“地推式”地去推广,依旧是无济于事。
当时的淘宝虽然在使用Oracle等数据库时,面临着瓶颈问题,但当时已经做出了“拆分”这样的应对措施。
加之还要MySQL的加持,基本上平稳运行是没有问题。
在这节骨眼上,换谁想从头折腾一遍,又有谁敢承担其中的风险呢?
但淘宝的收藏夹,却成为了重要转折点。
因为当时收藏夹团队的一个需求,无论是Oracle或者其它数据库,都没有办法解决。
简单来说,就是商品信息在发生变更的时候,“收藏夹数据库”和“商品数据库”中对应的两张表,需要做一个join的操作。
但以当时无论何种技术来看,开销着实过大。
而阳振坤团队却说:I Can!
收藏夹团队选择信任阳振坤和他的团队,让他们放手一搏。
最终,凭借着分布式系统的优势,收藏夹在“换骨”之后安全度过了当年的双11。
虽说首战告捷,也算是打出了一点名气,但不敢换数据库这事,依旧还没有得到解决。
于是,当时任职阿里巴巴CTO的王坚做出了一个重要决定——把OceanBase调入支付宝。
但在支付宝,毕竟涉及到的是金钱相关的问题,绝不容出任何差池。
虽然阳振坤团队喊出“要替换掉Oracle”的口号,但同时也直接被质疑:
你怎么保障一分钱都丢不了?
对此,阳振坤采用了“副本”的策略(上文中提到的能力之一)。
而当时的蚂蚁集团CTO鲁肃,将当年双11的1%的流量交给了OceanBase。
但有意思的事情发生了。
在双11之前的压力测试过程中,身负99%流量的Oracle一蹶不振,bug层出不穷。
每次超过90%这个门槛,就会出现问题;但OceanBase在自己“一亩三分地”的表现却出奇的稳。
于是,鲁肃也算是背水一战,决定让OceanBase负责的流量,从1%升到了10%。
最终,OceanBase没有辜负厚望,顺利帮助支付宝度过了当年的双11。
而截至当时,OceanBase的版本才迭代到0.5。
就这样,OceanBase用一次又一次的行动,证明了自己的价值,证明了分布式数据库的正确性。
时至今日,OceanBase已经进入第12个年头了,阳振坤当年喊出的口号也已成真:
支付宝所有数据库,均已替换成OceanBase!
……
若是从OceanBase的发展历程来看,大致可以把它分为三个阶段:
- 1.0时代 (2010-2014):是“坚定走向分布式架构”的时代,包括发布了新一代分布式引擎、实现海量存储低成本、处理准内存引擎高性能业务。
- 2.0时代 (2016-2019):是“原生分布式数据库”的时代,实现了永远在线,突破容量限制无限扩展,突破地域限制单机到城市级容灾能力。
- 3.0时代 (2020-2021):是“混合引擎、混合部署”时代,内核架构全面升级,打破边界,同时支持TP和AP、混合云部署。
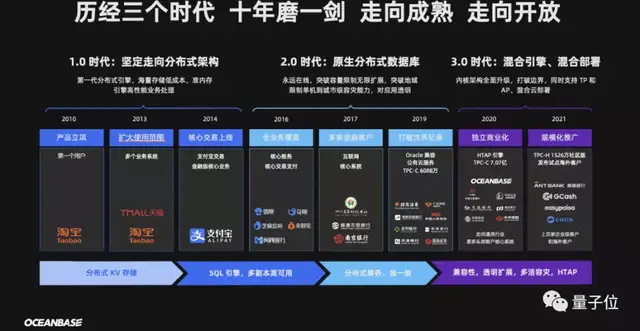
而到了现在,OceanBase要做的还有“走出去”。
第一层,是走出阿里巴巴,而且是最具挑战、最具难度的金融业务。
例如,OceanBase通过它高可用的架构,已经帮助一些银行的核心系统,实现两地三中心容灾。
不仅实现了跨地域无损容灾,还提升了快速适配开发的能力。

第二层,是走出国内。
毕竟在数据库界有句话,叫做“能处理金融行业的数据库,其它场景都能处理”。
OceanBase确实也做到了如此,已经涉足国内多个行业,帮助提升数据库质量,完成数据化转型。
而目前OceanBase也在把目标慢慢向国外发展,在更大的舞台、更强劲的对手较量。
最后一层,是走向开放。
截止到上个月末,OceanBase开源版本已经发布了140余天。
就在这短短的时日里,它的开源社区已经累计了21000多用户,斩获4200+ Star。
不仅兼容MySQL,还提供越发开放的接口、部署工具、迁移工具和数据库运维工具供使用。
同时在人才培养方面,与高校合作开设课程、出教材、办比赛,还完成了1000多的人才认证。
……
这,就是国产数据库OceanBase的故事。
那么最后,站在这样的一个时间点,又该如何重估它呢?
套用主播们经常用的一句话,或许就是——国货之光吧。
- 巧妙!一个传统技术让国产视觉基础模型直接上大分2025-05-23
- 华为:让DeepSeek的“专家们”动起来,推理延迟降10%!2025-05-20
- 一场对话,我们细扒了下文心大模型背后的技术2025-05-22
- 京东Joy Inside首家合作!元萝卜AI下棋机器人五合一版重磅发布2025-05-22