明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
AMD造势已久、面向高性能计算的MI200,终于来了!
在拿下元宇宙大客户Meta后,AMD乘势而上官宣一系列新芯片,其中就包括这张不断有消息曝出的计算加速卡。

它采用6nm工艺,拥有580亿个晶体管、超过14000个内核、128GB的HBM2e显存,FP32性能达到95 TFLOPs 。
官方表示,它可以加速机器学习等任务,对标英伟达A100。
没错,是要和老黄抢盘中餐的节奏。
并且该芯片之后还将被用于美国橡树岭国家实验室的超算系统中。
所以,MI200性能到底如何呢?
FP64性能是A100的4.9倍
本次发布的MI200系列中,包含Instinct MI250X和Instinct MI250两款芯片。
与120个计算单元(CU)、7689个内核的MI100相比,其性能有了大幅提升。
- MI250X有220个计算单元 (CU) 和14080个内核。
- MI250则有208个计算单元 (CU) 和13312个内核。
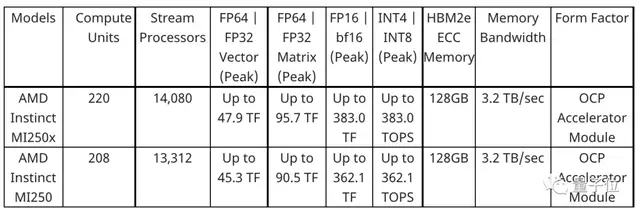
它们采用了全新的CDNA™ 2 架构,可加速FP64和FP32矩阵运算,与上一代MI100相比,FP64理论峰值性能最多可高出4倍。
2.5D Elevated Fanout Bridge(EFB)封装技术让MI200在内核数上较上一代增加了1.8倍,内存带宽增加了2.7倍,聚合理论峰值内存带宽也高达每秒3.2TB。
与此同时,第三代AMD Infinity Fabric™ 技术可管理8条Infinity Fabric链路,让MI200计算节点可与第三代霄龙(EPYC)处理器或其他GPU相连,从而实现统一的CPU/GPU一致性、并最大限度地提升系统吞吐量。

既然说对标英伟达A100,那具体表现如何呢?
制作工艺上,A100采用7nm制程,集成超过540亿个晶体管,显存为80GB。
MI200系列则采用6nm工艺,拥有580亿个晶体管,显存达到了128GB。
性能对比中,MI200的FP64性能是A100的4.9倍。

在处理加速任务中,AMD也对MI200系列和A100进行了对比:
以处理分子动力任务为例,MI250的性能表现是A100的2.2倍。

在其他几项任务中,MI250的表现也都优于A100(具体数据可参看文末参考链接4)
AMD愈加抢眼
此次除了发布MI200之外,AMD还发布了首款采用3D V-Cache 技术的服务器处理器产品——EPYC Milan-X。
这款芯片之后将被用于微软的Azure云计算服务。

而在产品之外,AMD近期的财务表现也非常抢眼。
先与Meta达成合作,后又发布系列新芯片,让AMD的股价也在这周第一个交易日大涨10%以上。
上个月发布的Q3财报中显示,AMD营收同比增长54%,较老对手英特尔表现亮眼,也让不少人更加看好AMD。
这一次,AMD的这次动作更是瞄准英伟达的王炸A100发布对标产品。
而且网友表示,与Meta合作意味着AMD的卡将来可能可以移植Pytorch,英伟达在机器学习上的垄断地位或许会被撼动。

参考链接:
[1]https://ir.amd.com/news-events/press-releases/detail/1032/new-amd-instinct-mi200-series-accelerators-bring
[2]https://www.reuters.com/technology/amd-lands-meta-customer-takes-aim-nvidia-with-new-supercomputing-chips-2021-11-08/
[3]https://www.tomshardware.com/news/amd-instinct-mi200-chiplet-datacenter-gpu
[4]https://www.amd.com/en/graphics/server-accelerators-benchmarks