
ICLR 2022论文双盲通过却被爆抄袭:数据算法全部照搬,第二页几乎空白
论文质量差到网友以为是钓鱼
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
最近,一篇已经通过ICLR 2022双盲评审的论文被曝“严重剽窃”!
还是算法直接截图粘贴,图表颜色都不改一下的那种!
就像是这样,直接把ICLR 2020上的一篇论文的算法部分截图,然后粘贴到自己的论文里:
(而原论文的算法部分可复制,也更加清晰)

还有架构图部分,除了标注了“引用”的那句话,其余的从架构图本身到图表下的说明,都与EMNLP 2020的一篇论文分毫不差:
不仅是算法和架构图,摘要、正文、实验结果部分也存在着大量的Ctrl+C内容。
现在,这篇论文已经被项目主席以“严重剽窃”为由直接Desk Reject:
而点进作者的个人资料链接,能看到他的大部分工作内容都与网络安全相关,并没有发表过任何机器学习领域的论文。
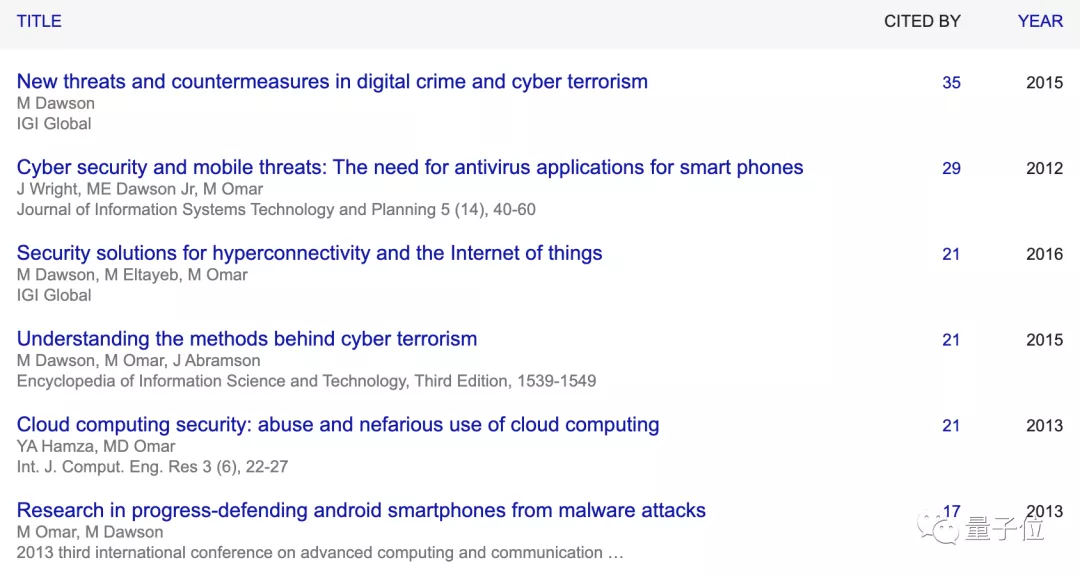
但他抄袭的两篇论文,偏偏都来自于机器学习领域的顶会:


跨界抄袭、低得可笑的论文质量、草率而毫不掩饰的剽窃行为,种种现象甚至都让网友怀疑:
这简直就像是同行评议人的“虚拟测试”……作者不会真觉得别人发现不了他的抄袭吧?

「忠实原著」的论文
接下来,就让我们顺着ICLR项目主席列出的五条抄袭的证据,来看看这篇论文。
五条证据分别指出的分别是图表和算法几个部分。
但实际上,涉事论文从摘要就已经开始了它的表演。
在论文摘要中,作者提出了一种新的对抗性文本生成模型Text-Gen,能够生成更有意义和多样性的对抗性文本:
但如果和ICLR 2020里的这篇提出了CAT-Gen模型的论文摘要做个在线文本对比……
好家伙,你搁这儿找不同呢?
摘要过后,马上就是这样一页:
(持续往下拉,没错,大片空白的第二页)

开头所展示的流程图和算法也就是项目主席列出的第一条和第五条:
图像100%复制粘贴还注明了引用;
来自其他论文的算法截图则根本就没有注明。
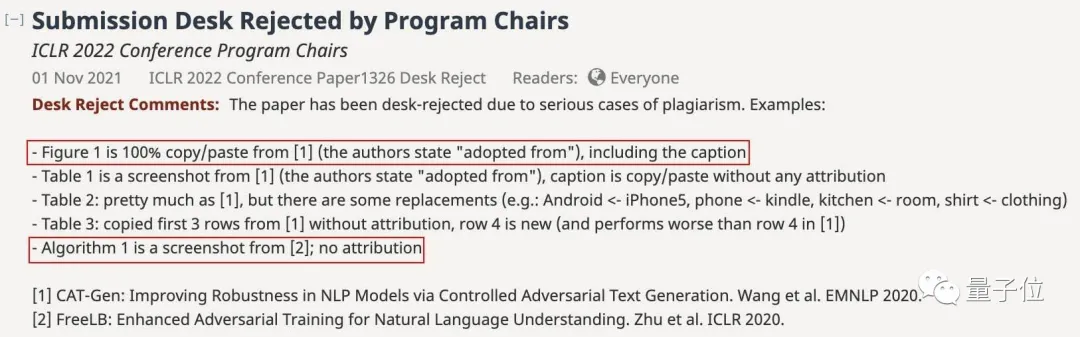
而剩下的三条展示实验结果的表格也是如法炮制,要么是无引用的直接截图粘贴:

要么就是将原表格中的Android、phone、kitchen、shirt等名词“别出心裁”地换成了iPhone5、kindle、room、clothing……
还有“良心发现”修改了数据的Table 3,却被评委无情吐槽:
你这数据还没原文的好,不如不改……
一月多度的「学术不端」
抄袭者marwan omar来自美国佛罗里达州的圣里奥大学(Saint Leo University),主要研究网络安全、智能手机安全、虚拟化等领域。
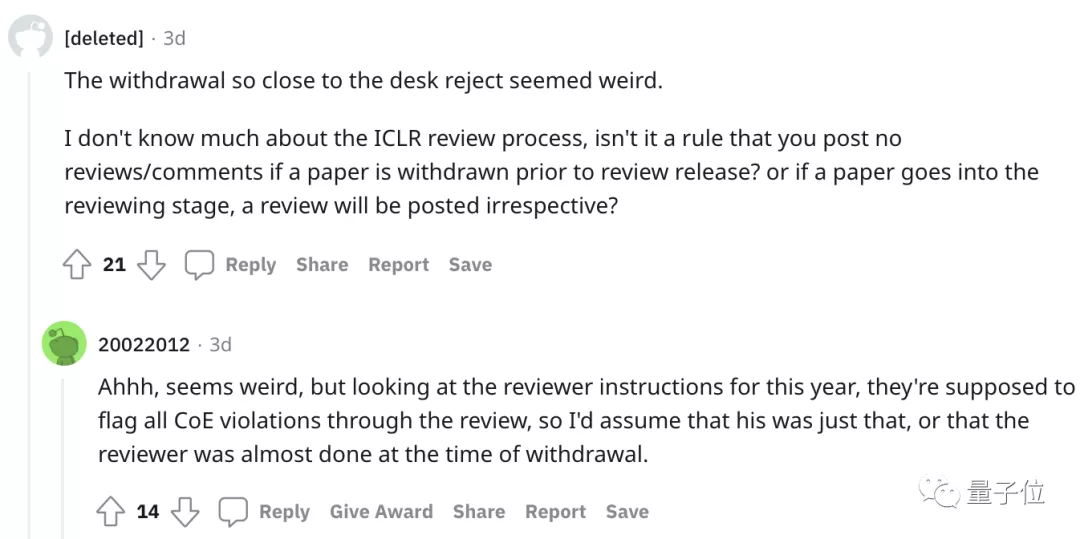
而其实在被项目主席直接怼脸拒稿之前,作者团队已经在10月29日确认撤稿:
这也让有些网友表示疑惑:为什么已经确认撤稿之后还会发布审查评论?
下方有人猜测:
看ICLR今年的评审指南,他们提到会通过评审标记所有违反规则的行为,所以可能只有这篇“严重剽窃”的论文是这样。
或者评审在作者撤稿的时候已经差不多完成了。
当然,如此跨界的抄袭也引来了不少网友真情实感地怀疑:这该不会是钓鱼吧?
如果没有被发现,事后就可以发篇《我在机器学习顶会上投了篇废话连篇的论文,而同行评审居然没有发现》的博客!

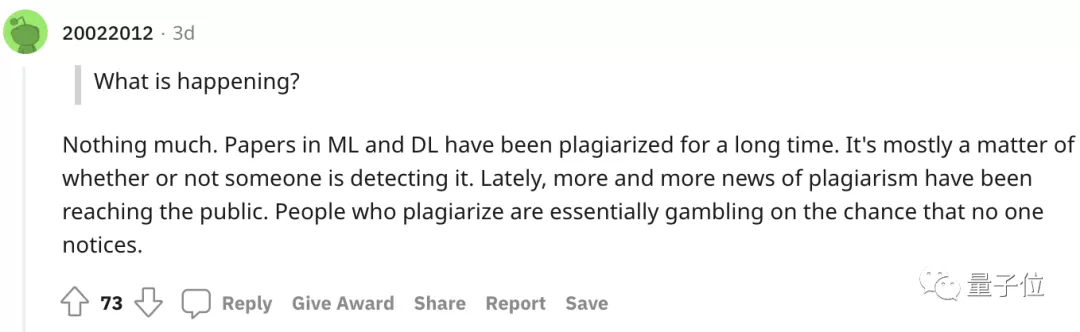
还有人表示见怪不怪:ML领域的论文本来就长期被剽窃,区别只是有没有被发现而已。
现在已经有越来越多的剽窃新闻被披露,而那些抄袭者只是想赌一把自己不会被发现。
现在想来,最近的「学术不端」事件确实有种一月N度的倾向。
仅说国内,北理工副教授张华平在11月1日就刚刚曝出,他带的学生的硕士学位论文被南方某985高校学生陈某抄袭。
一两个月之前,还有北理工硕士“原文照搬”NeurIPS论文,港科大硕士抄袭ICML论文。
以及8月份曝出的SCI期刊上的大量辣眼学术名词,目的就是为了规避抄袭检查:
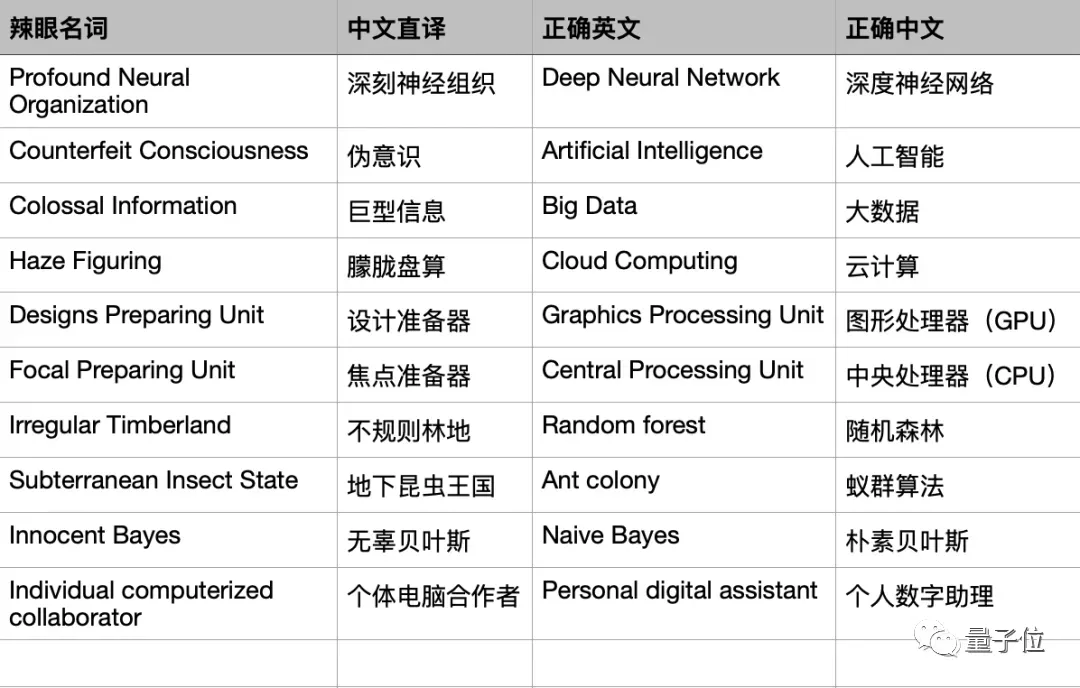
只能说,不到今年的最后一刻,谁也不知道「2021年学术不端大盘点」中,又能多出哪些素材。
官方通报:
https://openreview.net/forum?id=EO4VJGAllb¬eId=Ks7TmTUsyXa
参考链接:
https://www.reddit.com/r/MachineLearning/comments/qkb6ga/plagiarism_case_detected_iclr_2022_newsdiscussion/
- 有道智能学习灯发布,通过“桌面学习分析引擎”实现全球最快指尖查词2022-04-08
- 科学证明:狗勾真的懂你有多累,听到声音0.25秒后就知道你是谁,对人比对狗更亲近2022-04-14
- 在M1芯片上跑原生Linux:编译速度比macOS还快40%2022-04-05
- 小学生们在B站讲算法,网友:我只会阿巴阿巴2022-03-28










