中国如何赢得新一轮超算竞赛?关键在向数据密集型超算转变
国际超算竞争今年到了关键节点
梦晨 明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在超级计算机排名这场国际竞争上,今年明年到了关键节点。
各国摩拳擦掌准备多年的“E级超算”(每秒超过一百亿亿次浮点运算),都将集中在2021-2022年计划完成部署。
你可能还记得“神威·太湖之光”这个名字,我国这台超算在2016年登上国际排名第一。
仅仅两年后,美国的顶点(Summit)超算就迎头赶上,用每秒20亿亿次浮点运算的峰值速度超过神威的每秒12.5亿亿次。
再过两年,日本的富岳(Fugaku)以每秒50亿亿次(0.5E)的峰值速度再创纪录。
△图源:YouTube@What Da Stat
虽然富岳现在依然盘踞榜首,但被某台E级机超越也不会很远。
(E级机中的E指Exa,是比P(Peta)大一级的单位。)

美国正在准备中的E级超算至少有3台,美国能源部为此投入超过18亿美元。
计划今年就要部署的Frontier,峰值速度预计1.5E;2022年Aurora随后跟上,目标速度1E;2023年还有一台El Capitan,最初计划1.5E但建设过程中增加到了2E。
这还只是美国政府部门主导的项目,如果算上企业,特斯拉在建的Dojo超算目标速度也是1E。
我国正在进行的E级超算项目也有3个。
天河三号、神威E级和曙光E级的原型机都在2018-2019年研制成功,现在正紧锣密鼓地建设完全体。
此外,日本、俄罗斯也都启动了各自的E级机计划,欧盟在新建和改造超算上也投入了80亿欧元。
谁能率先拥有E级机成为大国超算竞赛的下一个关键点,国际超算排行榜“TOP500”每年6月和11月公布两次,谁会赢下这一盘也许很快就会揭晓。
究竟是什么让各国在算力比拼上不断加码?
当超算遇上数据
要回答这个问题,需要从两方面来看。
一方面是尖端科技发展的需要。
超级计算机之所以叫“超级”,是因为强大的算力能把不可能变为可能,把不实用变为实用。
如果你感觉现在天气预报比小时候要准多了,就得益于算力的提升。
过去由于算力不够只能对天气现象做出模糊的定位,那时候经常听到电视里的说法是“局部地区有雨”,到现在手机上都能随时查看精准的未来两小时降雨云图。
算力的发展把天气预报准确率从过去的21.8%提高到了现在的90%,日常情况下天气预报不准似乎无关紧要,但近年来极端天气现象频发,准确预测台风暴雨可是能拯救许多生命。
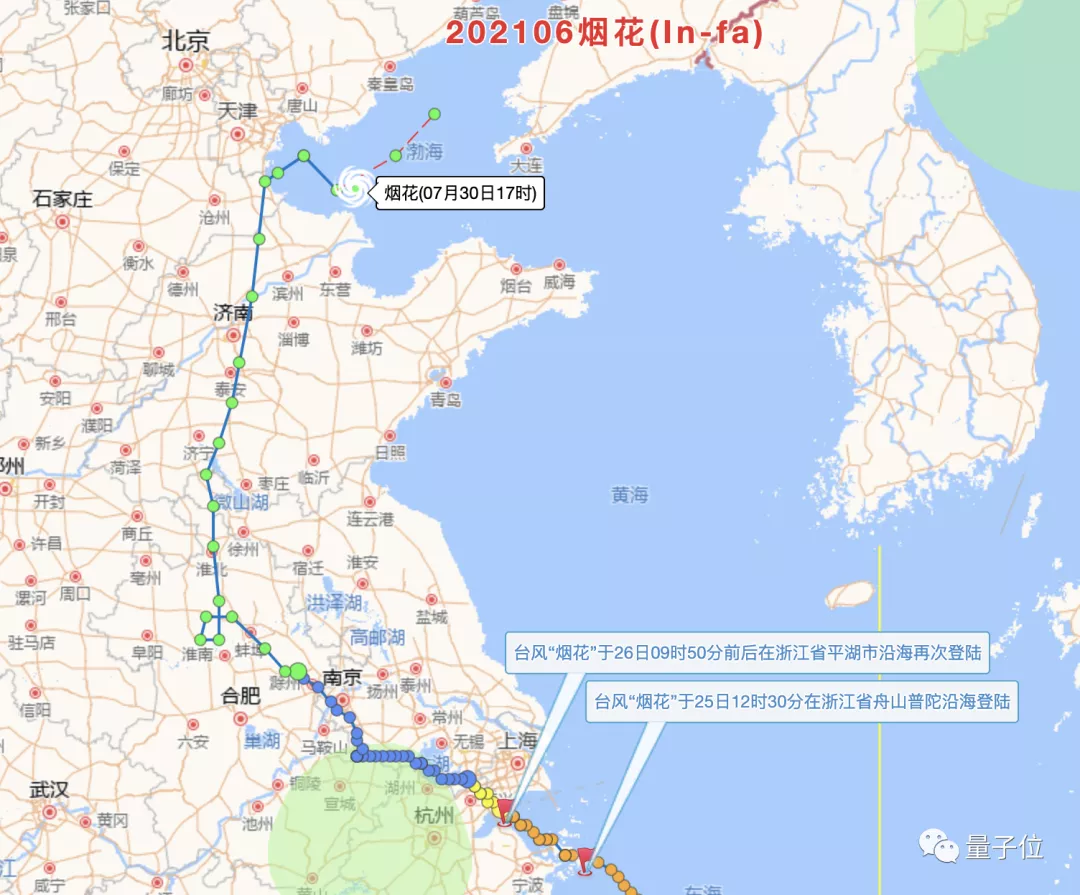
同样与拯救生命相关的还有生物医药领域,算力这些年的发展把基因测序的时长从13年缩短到1天,新药研发鉴定的周期从5000天缩短到了100天。
眼下为了让疫苗研发速度赢过病毒的变异速度,各国也纷纷动用了超算的力量。
此外,在天体物理、地震预测、石油勘探、国防军事、新材料发现等领域也都需要强大的算力支持。
另一方面,新闻中总能听到的“产业数字化转型”,其实就是说算力已经深入到经济运行和人们生活的方方面面。
今年宝马与英伟达合作,把整个生产流程在数字世界中重建,通过仿真模拟进行优化,把生产效率提高了30%。
这项技术叫“数字孪生”,也就是把现实世界产生的历史运行数据、传感器收集数据、统计数据等统统搬到数字世界里去,尽可能还原一个现实世界的副本。

据权威市场研究公司IDC预测,到2022年75%的企业将把智能自动化嵌入到技术和流程开发中。2024年,AI将成为所有企业不可或缺的组成部分。
从现实世界镜像到数字世界的数据将会爆发式增长,甚至可以说未来智能产业的运转速率取决于数据分析的速率。
随产业数字化带来的,是数据构成上的变化。根据IDC预测,到2025年80%的数据将是非结构化数据。
非结构化数据很好理解,像分散在互联网上的文章、文档、图片、音频视频等,只要不是用行和列组成的二维表结构表达的都算非结构化数据。
中科院院士陈国良认为,如果说数据是数字世界的新石油,那么非结构化数据更难处理,就像石油中最难开采的页岩油。
处理庞杂的非结构化数据就需要新技术,这种新技术叫做面向海量数据的高性能数据分析(HPDA,High Perfermance Data Analytics)。
简单来说,实现HPDA需要把超算、AI算法、大数据三者结合起来。
这样的超算也可以称为数据密集型超算,也就是用超算的并行处理能力运行强大的AI算法,从海量数据中提取出价值。
根据全球高性能计算市场研究机构Hyperion Research预测,未来数据密集型超算市场份额会数倍于传统超算的增长速率。
到2024年,高性能计算市场更是将有超过40%来自数据密集型超算。
这也让人不免期待,未来我们会在哪些场景中看到数据密集型超算的身影呢?
数据密集型超算用在哪?
这个问题其实应该反过来看,正是应用场景对算力需求的变化驱动着超算朝数据密集化方向发展。
一台超算从规划到建设再到投入使用需要好几年,所以最初就要面向未来可能的应用来设计。
比如生物医药领域,今年发生的一件大事是DeepMind开源了全新的蛋白质结构预测模型AlphaFold2,并把人类98.5%的蛋白质结构全都被预测了一遍。
而在这之前科学家们数十年的努力,只覆盖了人类蛋白质序列中17%的氨基酸残基。
在基因测序上,最早的人类基因组计划耗资30亿美元历时13年终于在2003年完成。
到如今面向个人消费者的全基因组测序服务只需要几小时,价格也降至100美元。
这让2007年仅为800万美元的全球基因测序市场规模,有望在2021年达到350亿美元。
这两个方向上的进展为加速新药研发提供了基础,再往后发展就需要将蛋白质结构数据、基因图谱数据结合上AI分析的文献、临床档案等非结构化数据进行化合物筛选、发掘药物靶点。
正需要高精度科学计算算力和精度需求不高但数据量庞大的AI推理、训练的算力相结合,才能真正做到缩短新药研发周期,降低药物研发成本。
再比如脑科学领域,对神经系统的研究除了医学上的作用,也是对大脑认知原理的探索,对类脑人工智能技术和相关器件的研发也有启示意义。
脑科学研究对传统超算系统提出的最直接挑战就是数据规模庞大。
人脑大约有1000亿个神经元,把神经元之间的映射全存成数据,需要的容量要达到EB级(一EB等于一百万TB)。
在这么大规模数据上做检索响应时间高达100小时,如果脑科学想取得突破性进展,也需要未来超算在数据存储架构上完成突破。
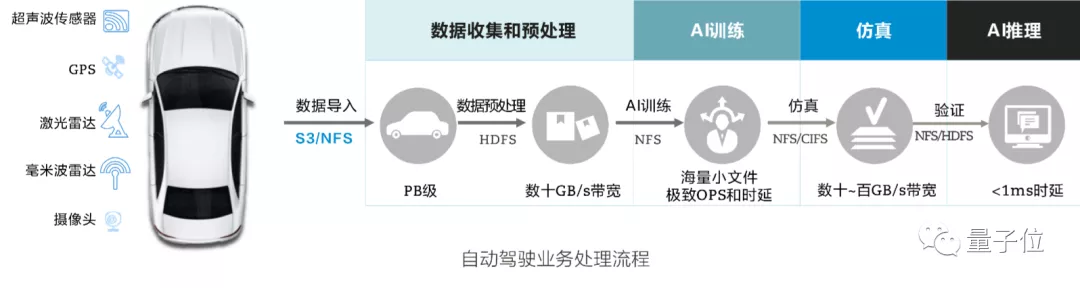
同样需要处理EB级数据的是时下火热的自动驾驶行业。
根据美国兰德公司的研究,自动驾驶算法想要达到人类司机水平至少需要累计177亿公里的驾驶数据来完善算法。
如果配置一支100辆自动驾驶测试车的车队,每天24小时不停歇路测,平均时速40公里来计算,需要500多年的时间才能完成目标里程。
先不提达到人类水平这么远的事,按照现在最受认可的SAE自动驾驶分级标准,达到L3级别也要2000万公里路测历程,对应的数据体量达到1-2EB。
自动驾驶行业还有一个难点是不同环节要求的数据协议不同。
数据导入时需要的是S3/NFS格式,数据预处理需要HDFS格式,AI训练又需要NFS格式,后面还有仿真、模型验证….
结果是,数据转换格式和来回拷贝的时间比处理分析时间还多一倍,这要求未来的数据密集型超算还要解决数据协议互通的问题。‘
从微观的分子化合物、神经细胞到中观的车辆、道路,再把视角拉大,研究宏观的地球、宇宙同样需要数据密集型超算。
能源勘探、气象预测、卫星遥感、天文观测的数据储存规模也在几十到几百PB,根据各自的特点还分别对超算的传输速度、是否需要AI接口、数据管理等问题提出不同的要求。
数据密集型超算该怎么建才能适应尽可能多的应用场景要求,就成了关键问题。
数据密集型超算该怎么建?
诚然,超算在基因测序、自动驾驶、脑科学等场景上已展现出巨大潜力。
各个大国都想抢先于人去挖掘这块新土壤,由此也就产生了当下超算竞争日趋白热化的局面。
面对这样的形势,我们如何做才能抢占先机呢?
由中国计算机学会高性能计算专业委员会、国内各高校和超算中心、华为联合编写的《数据密集型超算技术白皮书》已经给出了一些切实可行的建议。
《白皮书》认为,想要打赢这场算力上的“军备赛”,眼下我们应当从超算架构、网络传输、能耗等方面入手。
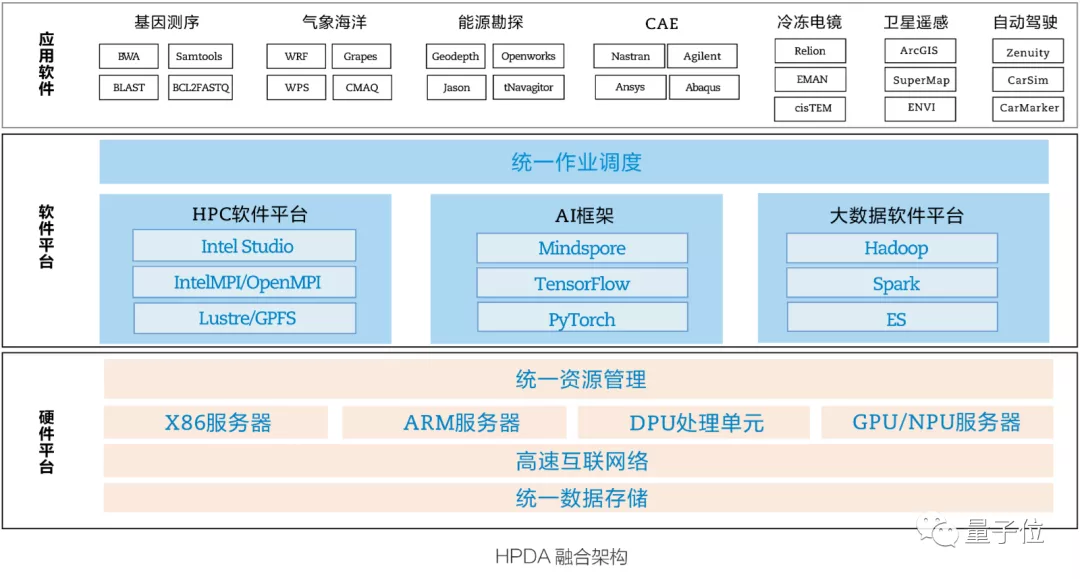
采用异构融合的新型 HPDA 架构
首先,超算要考虑的核心问题还是算力的来源,这就要从处理器芯片说起。
如今的超算中心是把CPU、GPU、FPGA等硬件结合,让不同的计算单元来负责不同的计算任务,从而提高计算速度和处理能力。
但随之而来也会产生一个问题,就是资源、数据、应用上的孤岛现象,导致资源重复建设、闲置,造成能耗居高不下的问题。
所以,未来的超算中心,要把原来“散兵作战”的计算单元,再“大一统”起来。
让它们在发挥各自强项、快速完成任务的同时,还能听从调遣,最大化利用计算资源,并尽可能完成更多不同的任务。
这也就是《白皮书》中提到的——异构融合架构。
具体来看,就是要做到三个层面的统一:硬件上统一资源管理、统一数据存储;软件上统一资源调度。
打造存算分离的统一数据存储底座
数据密集型超算以数据为中心,所以在计算单元之外,存储系统对超算运转速度也有巨大影响。
HPDA把HPC、大数据、AI融合,使得它的计算方式会和传统超算有所不同。
以发现新材料来举例,传统超算通过HPC仿真计算来发现新材料,HPDA则会用机器学习来实现,涉及AI模型的训练和推理。
这二者之间最大的差别就是,AI运算非常依赖数据。
具体工作过程中,大量计算时间都会消耗在等待数据从存储系统中读出或写入上。
如果沿用传统超算的存储系统,许多昂贵的计算节点都会处于空闲状态,造成资源利用不足的问题。
所以就要重新规划存储系统和计算系统。
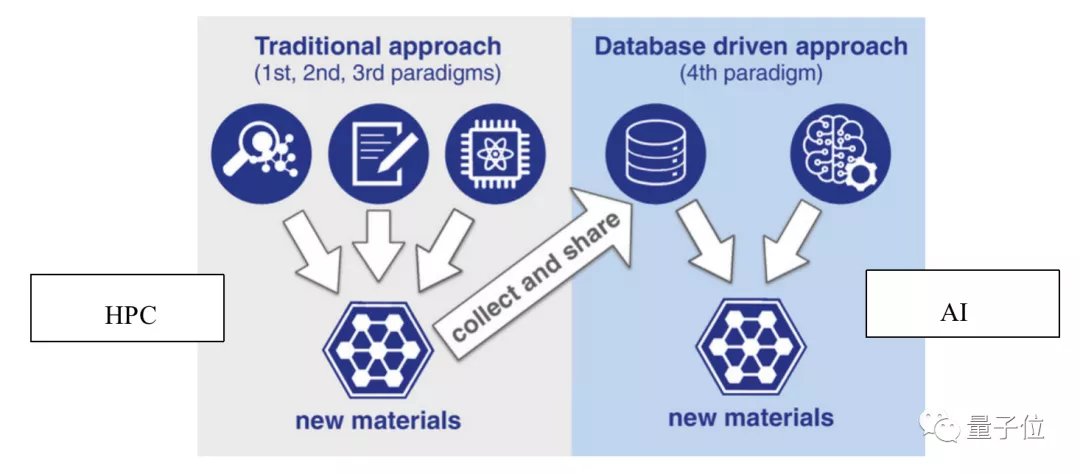
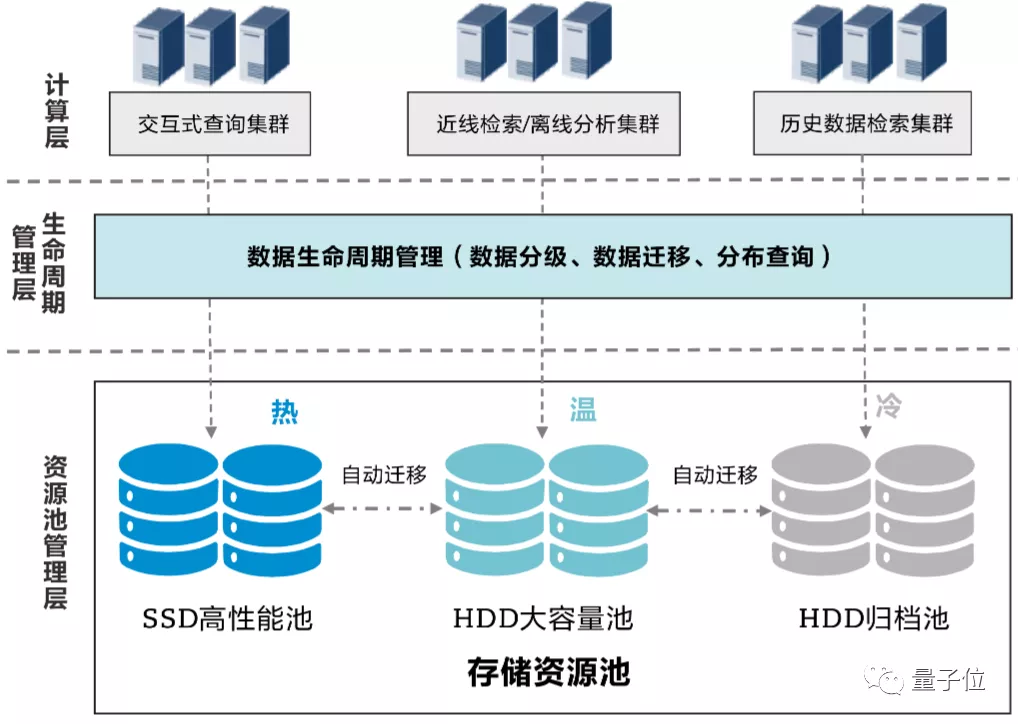
《白皮书》对此提出了存算分离的概念。
也就是让所有计算节点都共享一个存储,并且让不同数据(文档、表格、图片等)之间可以互通、互访。
这样一来,超算执行不同任务时,计算节点从这个大的存储底座中找到需要的数据即可。
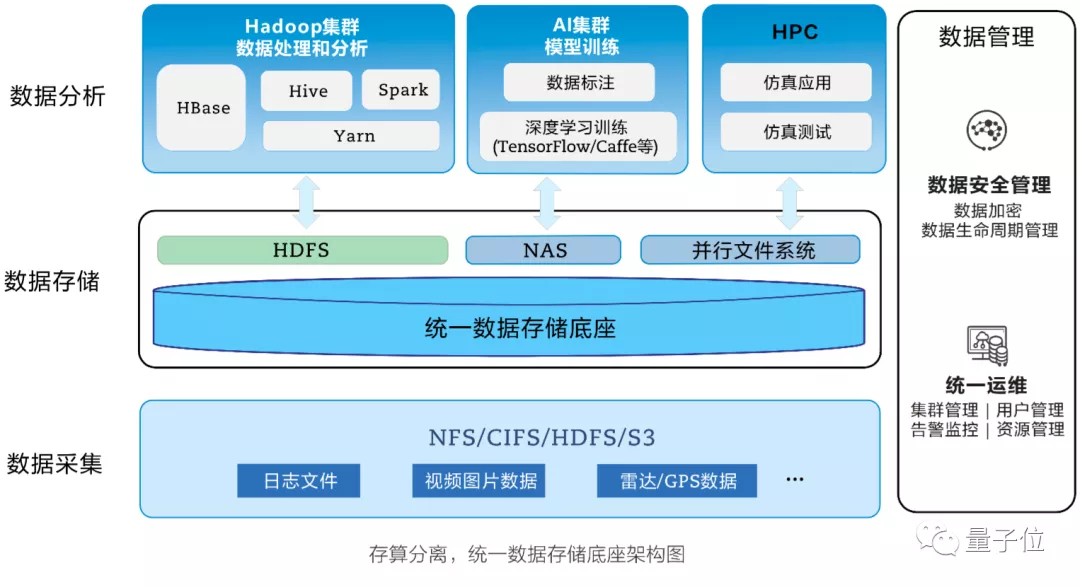
在此基础上,还要让数据可以按照需求自由流动,让热数据、温数据、冷数据能够智能分级。
也就是将高价值的文件放置在高可用性、高性能的存储设备上,低价值的文件放置在成本较低的、性能和可用性规格较低的设备上。
当然,还要达到合理的存算比。
一直以来我国超算中心建设都存在重算力、轻存储的问题。
在我国,存力(存储容量PB)与算力(计算算力PFLOSPS)的比例为1:2,相应的投资比例为1:3。这两个数据,美国已经达到1:1。
如果按照现在的超算中心建设模式推行,几年后我们势必会出现存储量短缺的危机。所以接下来,我们还有重视存力上的规划。
推进全光化多网融合高速互联网络构建
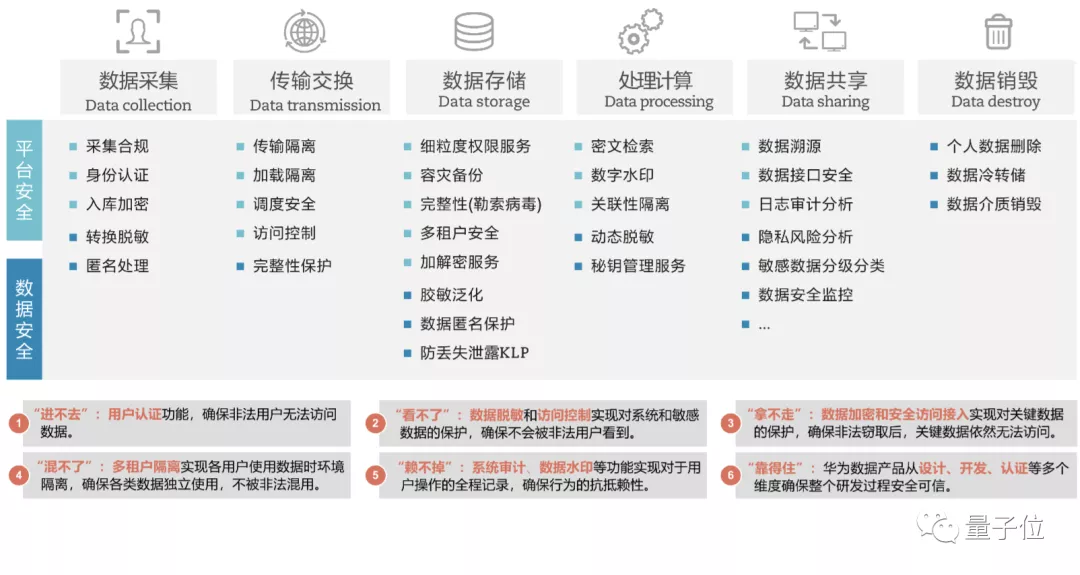
随着处理数据越来越多、种类更为丰富,传输上的高带宽、高IOPS和低时延需要得到很好保障。
同时也要注意全周期的数据安全。
事实上,超算中心能够快速计算、推理,也离不开设备之间的高速互连。
想要达到更好的效果,需要从元件材料和传输技术两个方面入手。
材料上,光子集成产品在尺寸、功耗、成本、可靠性方面优势明显,是未来光器件主流发展方向。
所以我们要大力推进“光进铜退”,用光子技术来构建高速互连的网络。

技术上,要让超算中心中的多网络进行融合。
超算中心中,往往有计算网络、数据网络、存储网络、监控网络等多套网络,在构建、运维、功耗上都会有很高的成本。
因此,如何让它们之间融合、降低成本,是未来数据密集型超算中心需要思考的问题。
使用低碳高效绿色节能的工程工艺
最后,我们还要考虑超算中心运行过程中的具体问题。
比如能耗。
随着芯片、系统、光器件等组成在性能上的不断提升,超算对能耗的需求在日益增大。
比如在系统层面,当前100P系统的能耗大约在20MW左右,单机柜能耗达到100KW,系统能效比大约为数十GFlops/W。
如果在节能上始终没有革命性的新技术出现,未来E级以上系统的这些指标都将变得难以承受。
对此,《白皮书》提出要降低电源使用效率、提升设备能源利用效率。
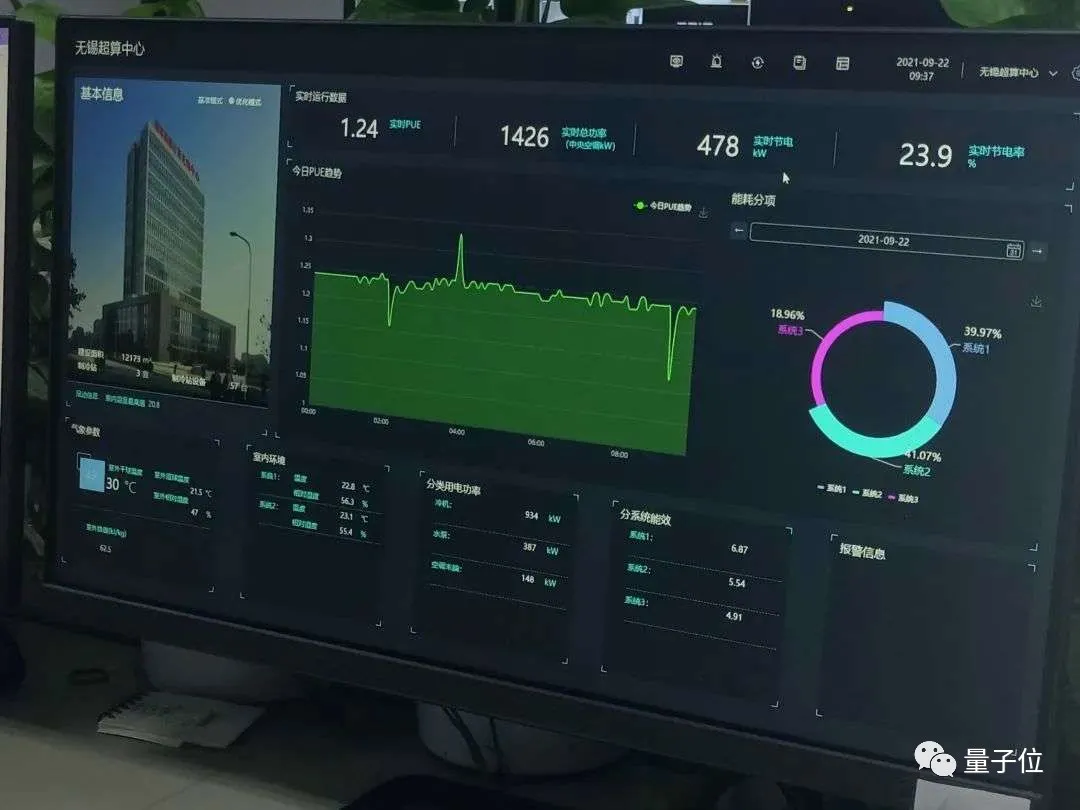
一方面是降低中心PUE。
PUE值(Power Usage Effectiveness,电源使用效率)是国际上比较通行的数据中心电力使用效率的衡量指标。
PUE值越接近于1,表示一个数据中心的绿色化程度越高。
我国国家超级计算无锡中心在建设之初的PUE值为1.3左右,如今年平均PUE值降至1.22。
两年时间减少约700万度耗电量,节约了400多万元电费。
另一方面是要提升IT设备的能源利用效率。
比如使用SSD闪存盘。
最常用的高性能SAS机械硬盘组成的存储系统典型功耗约10.6W/TB。
而SSD闪存盘组成的存储系统典型功耗仅约5.3W/TB,可降低约50%能耗。
因此,数据密集型超算中心要求全闪存存储占比50%,来极大促进超算中心的绿色发展。
构筑易用的国产应用平台支撑环境生态
如此高端的设备、先进的系统、强大的算力,你或许会觉得超算离我们遥不可及。
但事实上,超算的本质还是要解决更多难题,不仅是科研方面,还有普通生活领域的。
在过去5-6年中,高性能计算和AI在各种企业中的应用已经不再稀奇了。
这要归功于软件容器化技术。
只要容器化技术提前将超算运行环境封装好,实现应用和底层硬件的解耦,即便是不懂专业计算机的普通企业用户也能使用HPC。
而放眼未来,在构建良好超算生态上,我们还要让更多人能够参与到开发中来。
要针对行业内普遍存在的问题大力开发,为用户提供简单、易懂的可视化操作界面。
同时要解决新架构带来的开发难的问题。异构编程架构应该基于现有的经典并发模型,针对程序并行和数据并行,为用户提供方便快捷的工具。
此外,还要搭建智能化管理运维平台,用AI等技术让IT设施变得越来越智能。

以上就是《白皮书》中对数据密集型超算技术的建设标准提出的几点建议。
《白皮书》的最后一部分还对我国数据密集型超算的未来发展做了展望。
我国应尽快制定明确的发展目标和规划、出台相关指导意见,尽快制定数据密集型超算测评标准,并大力推进产学研合作。
如今我国超算发展正式迈入爆发期,在今年世界500强超级计算机名单中,中国超算中心部署量居世界第一。
在数据密集型成为重点趋势、超算产业迎来新一轮爆发的今天,中国超算已经走出一条属于自己的道路了吗?
获取白皮书:
https://e.huawei.com/cn/material/storage/1f2563c5282d44b3a8d26a97d14be65e
- 手机实现GPT级智能,比MoE更极致的稀疏技术:省内存效果不减|对话面壁&清华肖朝军2025-04-12
- 7B小模型写好学术论文,新框架告别AI引用幻觉,实测100%学生认可引用质量2025-04-11
- 字节新推理模型逆袭DeepSeek,200B参数战胜671B,豆包史诗级加强?2025-04-11
- Llama 4发布36小时差评如潮!匿名员工爆料拒绝署名技术报告2025-04-07