
我玩《王者荣耀》、斗地主、打麻将,但我是正经搞AI的北大教授
她从生物特征识别转而研究游戏AI,认为“游戏AI是智能该有的样子”
金磊 梦晨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
一位导师下载好了《王者荣耀》,还鼓励她的博士生们去玩一玩。
真的很难想象,这种“名场面”就真真儿的发生在了国内顶级学府——北京大学。
……
这位导师叫李文新,是北大信息科学技术学院的一名教授。

△
李文新教授
但她和学生们打《王者荣耀》可是真的正儿八经的,因为李文新的研究方向,正是游戏AI:
其实“游戏”这个词,并不应该是刻板印象中的手游、端游等等,我们对它的理解是更泛化的。
“游戏”是对“现实”的抽象和模仿。我们期望在游戏中获得与现实接近的快乐成功体验,却又避免现实中由于失误和出错带来的真实损失。
因此游戏是一个非常好的试错和迭代成长的虚拟环境。将现实问题环境虚拟成游戏,在游戏中通过大量试错纠错来迭代优化问题解决方案,是一种重要的教育手段和研究手段。
甚至在李文新的眼里,游戏AI才是真正的人工智能。
(不禁令人想起最近大火的《失控玩家》了)

△
《失控玩家》剧照
游戏AI到底拥有何种魅力,能让李文新如此痴迷?
在游戏里搞AI
先来看看李文新带着博士们,是怎么打的《王者荣耀》。
他们要做的,其实就是在限定的时间和资源内,训练出一个最优决策模型,并把它部署到游戏AI对战服务器平台上。
这就像是一个“炼丹”的过程,让他们的智能体通过训练,练就各种“功法”,然后去和别人家的智能体过招。
例如在之前的一场比赛中,《王者荣耀》英雄间的博弈是这样的:
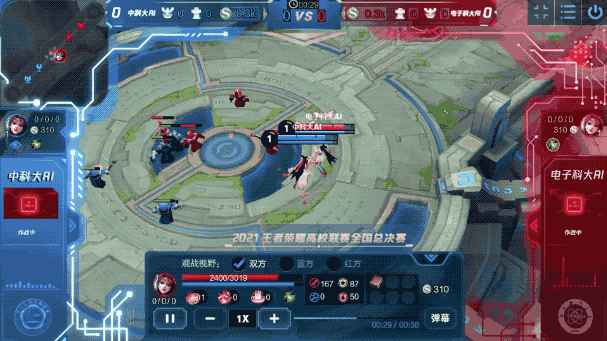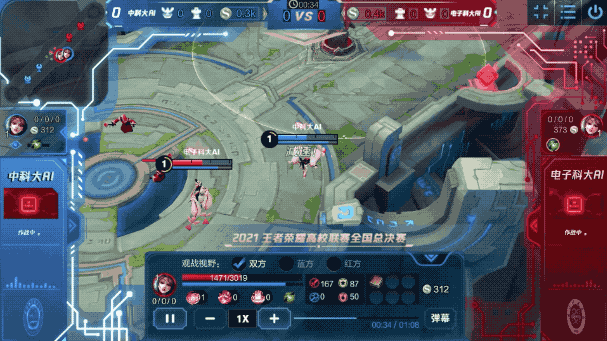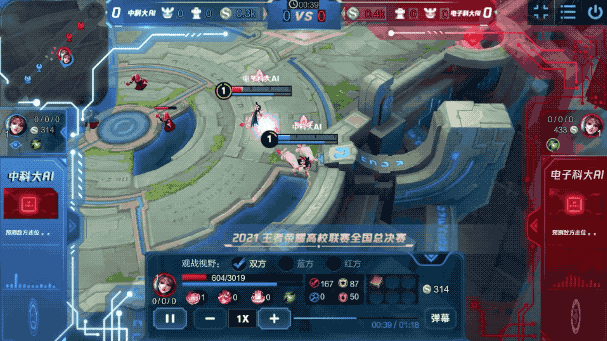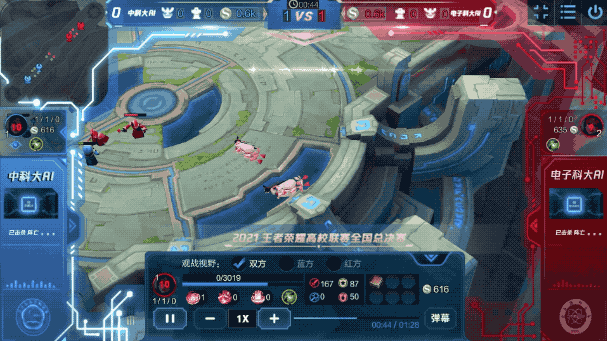
虽说都只是智能体,但在这波battle中,它们很好地发挥了自身的“基本功”:
作战中
预测敌方走位
释放技能连招
已击杀,阵亡
而在每个“基本功”背后,都是智能体审时度势后的最佳决策。
这就是李文新团队最近在打的“游戏”。
而更具体一点来说,就是在特定的环境中,对多智能体之间的博弈策略展开研究。
它有几个难点:
-
第一是智能体的每一个决策都有非常多动作可以选择(决策空间大,不能逐一枚举尝试);
-
第二是决策的成败与否不仅与自己的选择有关,还与对手的决策有关,所以需要对敌人做预测(同时决策问题,存在循环克制的策略);
-
第三是作战环境和敌人的某些信息是未知的(非完全信息,需要对未知信息进行探测和猜测);
-
第四是游戏从开始到最终是一个比较长的决策过程,需要权衡长期收益和短期收益,并且需要形成一些组合套路(阵法);
-
第五是多智能体之间存在合作关系,让智能体学会合作和布阵,依旧是这个领域的前沿难题。
总之每一次决策都会对全局产生非常复杂的影响,是有种“牵一发而动全身”的感觉了。
……
但除了像《王者荣耀》这种MOBA游戏之外,李文新团队更痴迷的其实是中国传统游戏:
斗地主和国标麻将。
例如斗地主是这样的:

打麻将是这样的:
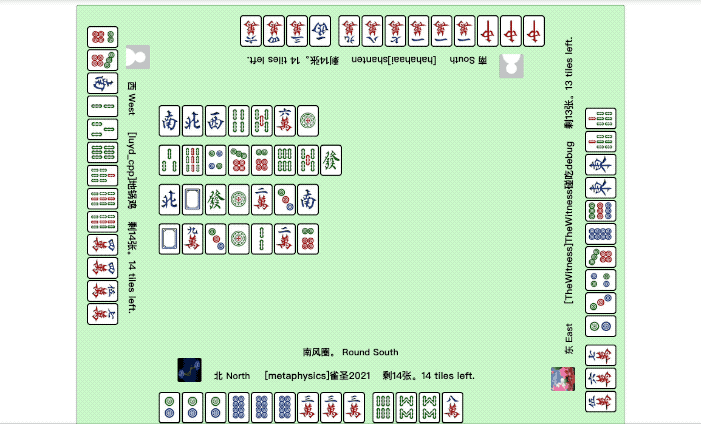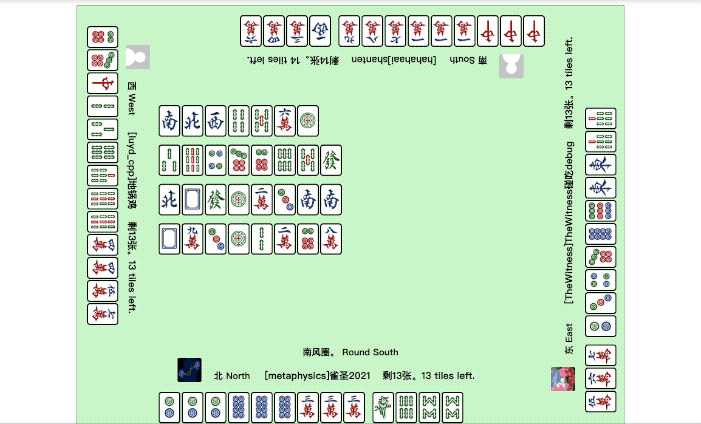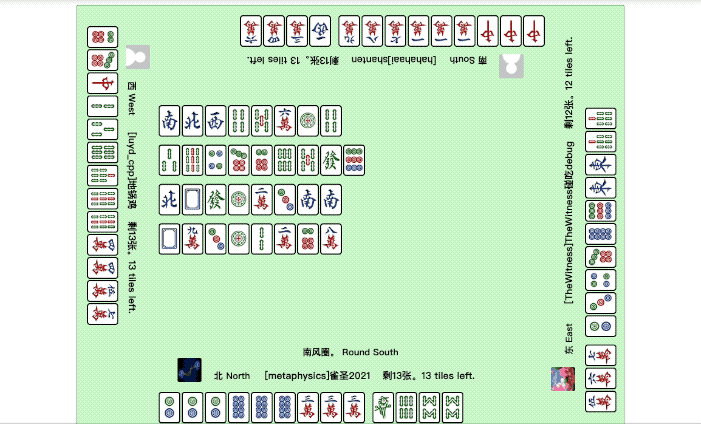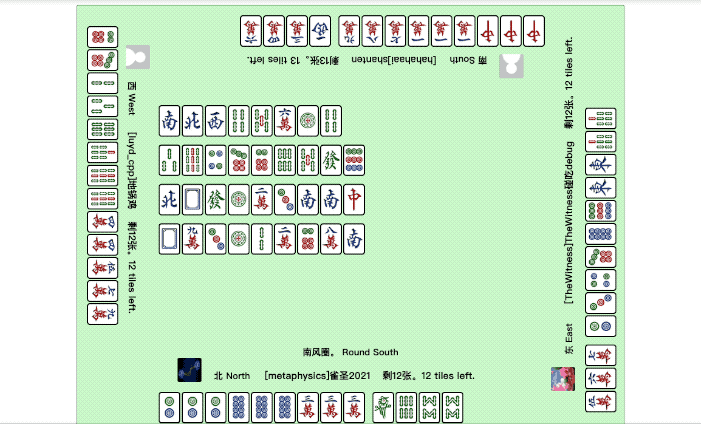
这场面,看着是不是挺像在线小游戏的?
不不不,仔细看下图中的这些“玩家”,其实它们都不是人,而是一个个训练好的智能体。
而且讲真,让AI打咱们这些个“祖传”游戏,难度可是要比《围棋》高得多。
因为从博弈论的角度来看,斗地主和打麻将是属于非完全信息多人博弈。
简单来说,就是游戏中有多个玩家,每个“玩家”都看不到其他人的手牌,并且初始手牌和牌堆是随机发放的。
随机发牌带来的难度在于很难事前准备针对特定牌局的策略。
在非完美信息游戏中,由于信息是不完全、非对称的(例如扑克和麻将中对手的手牌和游戏剩余的底牌都是未知的),因此对于参与者来说许多不同的游戏状态看起来是无法区分的。
例如在扑克游戏中,自己拿了两张 K,对方拿了不同的牌对应不同的状态;但是从自己的视角看,这些状态其实是不可区分的。
我们把每组这种无法区分的游戏状态称为一个信息集。
除了信息集的数量,还有一个重要的指标:信息集的平均大小,即在信息集中平均有多少不可区分的游戏状态。
在斗地主和麻将等非完美信息游戏中,斗地主的信息集数量是1053~1083,信息集大小是1023,麻将的则是10121和1048。
李文新还介绍到,像斗地主和麻将,还会涉及到动态结盟的问题。
这样一来,对AI的挑战性就更高了。
在1997年IBM的“深蓝”战胜了国际象棋大师卡斯帕罗夫,它使用的算法是基于启发式搜索的,人类象棋大师的经验被编写在了程序代码中。
2016年“AlphaGo”战胜了围棋大师李世石,它使用的算法是基于蒙特卡洛树搜索、监督学习(深度学习)和强化学习的。
在监督学习中,AI模仿了人类顶尖棋手的下棋方法,但只靠模仿人类是无法超越人类的。
强化学习则是让AI在与AI自己的千百万次对弈中不断自我成长,进而超越了人类棋手。自此强化学习方法成为游戏AI算法研究的主流方法。
简单来说,强化学习的过程可以概括为:智能体与环境的交互,环境根据智能体的行为给予其不同程度的奖励(惩罚),智能体因为想要最大化自己的累计收益,所以会根据环境对不同行为的反馈来重塑自己的行为(学习)。
使用强化学习的方法来训练智能体时,我们并不直接告诉智能体应该如何做,而是在环境中合理设置奖惩机制,使得智能体因为想要获得最大累积收益而“主动地”调整自身行为,进而达到主动学习的目的。
像家长在孩子做好事情时会给予奖励,做错事会给予惩罚,以使孩子朝着家长期望的方向发展,就是一个强化学习中通过调整环境奖励机制促使智能体朝着预定方向进化的例子。
这种通过调整环境的奖励机制来指引智能体的进化方向的方法可以有效地将人类经验融入到机器学习过程中去,因为奖励机制的制定可以是人为的。
如何更好地利用强化学习方法训练非完全信息多人博弈游戏AI,是否有比强化学习更好的方法使智能体习得多人合作的策略,目前仍是游戏AI领域的难点问题。
李文新团队的工作还不止于此,他们为了能让更多人参与到游戏AI的研究中,还特意打造了AI对战平台——Botzone。
在这个AI平台上,用户可以提交自己的智能体程序进行AI之间的对战,也可以亲自作为玩家参与到与AI的对决中。
刚才展示的斗地主、国标麻将的例子,就是在Botzone中的较量。
而除了这两款游戏,Botzone还提供了坦克大战、扫雷、俄罗斯方块和它们的各种变体。
李文新还在北大开了一门《游戏中的AI算法》选修课,作业是设计打各种游戏的AI,受到同学们的欢迎。
……
不难看出,李文新是一个资深游戏迷了。
但令人意外的是,在游戏AI这个领域,她却属于“转型选手”。
半路“出家”到游戏AI
如此“爱玩”的李文新教授,其实是最近几年才把研究方向转到游戏AI上的。
她早些年主要研究生物特征识别,是国际上最早从事自动化掌纹识别的研究者之一,后来还扩展到更难识别、也更不容易伪造的指静脉识别。
说到这里李教授还透露了一个小秘密,2009到2014年间,北大课外锻炼考勤使用的指静脉识别系统就是她们团队做的。
那为何不沿着这个方向继续做下去?
李教授的回答稍微有点“凡尔赛”:她觉得自己在生物特征识别上的研究算是成功了,可以告一段落了。
故事是这样的。
随着她带的学生陆续毕业,其中两位博士创业开了家公司,在教育考试,银行,社保医保等领域都接了大项目,把团队的科研成果实际落地了。
李文新教授认为学术界的使命就是开辟一个新的领域,具体到应用中怎么降低成本、产生效益那是工业界该考虑的事。
所以她做为一个学者现在该做的是去寻找下一个领域。
生物特征识别其实是她在香港理工大学读博士时导师的研究方向。更早时候她在北大读硕士时,导师带着她研究的是地理信息系统。
前两个研究方向等于都是导师帮她选择的,而这一次转型,她想自己去寻找新的挑战。
那又是为什么选到了游戏AI这个方向?
虽然李文新教授自己从小也对棋牌类和体育运动类的游戏很感兴趣,但与游戏AI结缘的故事要从2002年开始,她组织北大学生参加ACM主办的国际大学生程序设计竞赛(ACM/ICPC)说起。
当时除了正赛还会在旁边开设一个分赛场,与正赛里的高难度算法题不同,分赛场的项目往往带有对抗性质,比如机器人足球赛。
2005年的ICPC亚洲区预选赛在李教授的推动下正是在北京大学举办,当年对抗赛的项目是“坦克大战”。
在一定规则下,每个参赛队伍为坦克制定一套策略,然后上场对战,输了的还可以现场修改代码继续参加下一轮。
在一届届这样的比赛中她还观察到一个特别的现象,对抗赛上胜出的学校往往不是正赛上的传统强校。
似乎与解算法题相比,为游戏制定策略有着不一样的难度和挑战。
用李教授自己的话说,从这些对抗赛上她第一次“看见”了游戏AI。
后来,她自己在教学中也尝试加入对抗要素,想引发更多学生对AI的兴趣。
再后来,就是像她带领团队为ICPC正赛开发的在线程序评测系统POJ一样,也为游戏AI开发一个Botzone测评和对战平台。
在AI测试评估这件事上李文新教授的一个观点是:
但凡进入一个研究领域,第一步总是先要有个测试平台,才能为后续研究的迭代找到优化方向。
此时,游戏AI还没有成为她的主业,不过她越来越觉得与给一个特定的视觉或语言任务建模相比,游戏是动态的博弈,充满了变化和挑战。
到了生物特征识别上的研究告一段落后,她觉得不如就找这个自己喜欢又有挑战的方向来做。
因为搞科研必须是自己喜欢才会有激情,才能做到废寝忘食,研究才能深入。
2016-2017年,李文新教授开始坚定的转向研究游戏AI领域。
这个时间也正好赶上AlphaGo、AlphaZero连续打败人类,掀起了一阵AI热潮。
现在李文新教授带的博士生里,就有一位是喜欢下围棋、读本科时对AlphaGo深感震撼而选择了这个方向的。

以AlphaGo为代表的强化学习技术是当前游戏AI研究的主流方法,不过李文新教授的研究并不仅限于这里。
具体内容还包括游戏AI的复杂度分析、游戏AI对战能力和学习能力的评测方法、游戏AI的学习成本分析、游戏AI的模仿和倾向性聚类,甚至游戏对局的自动解说、新模式游戏设计等等。
当初的Botzone对战平台也发展成了知名的多智能体博弈系统,有8万多个AI在上面总共进行过3900多万次对局。
Botzone上产生的大量对战数据也成了游戏AI进一步研究的宝贵资料。
并且这些数据是开放下载的,让全国各地的大学生,还有一些中学生团队都可以在Botzone上面学习和比赛。
这些年的研究和教学经历让李文新教授越来越觉得“游戏AI是人工智能该有的样子”。
“游戏AI,是真的人工智能”
游戏AI应当是AI主流方式之一。
这是李文新对游戏AI的评价。
其实细想一下,这并不难理解。
游戏AI研究的是面对一个场景如何决策的问题,在现实世界里,如何决策体现了人类的高级智能。
我们只需要将现实世界建模成游戏环境,就可以在游戏环境中寻找解决现实世界问题的方法,之后把找到的解决方法还原到现实世界中去解决真实的问题。
这是一种非常经济而有效的方法。
更重要的是,由于强化学习的方法可以使AI在环境中自我成长,很可能获得超越人类的决策智能,这时人类很可能要反过来向AI学习了。
游戏环境是人类定义的,所以游戏的难度和参数是自主可控的,有非常大的弹性,这就使得游戏成为人工智能技术最好的试验场。
提高游戏的难度,就可以使得最新的硬件和各种最新算法有了用武之地。
像“深蓝”,使用了并行计算机和并行程序设计技术;AlphaGo使用了TPU及深度学习和强化学习技术。借助游戏提供的高难度决策问题,硬件和软件技术在解决难题过程中都有了突破性提升。
当一个问题过于困难时,我们也可以降低游戏的难度,使原本困难的问题得到部分解决,进而再逐步提升难度,递进式解决困难问题。
想想我们玩儿过的电子游戏:赛车、CS、DOTA、我的世界、星际争霸……,不是真实,胜似真实。
我们在其中的体验、感受、决策也可以迁移到现实世界中。
如果在星际争霸中几个AI学会了合作布阵,那同样的方法可用于真实世界的机器人对抗。
如果一个AI在游戏里会开赛车,而游戏环境尽量逼近真实,那这个AI就能成为自动驾驶技术的起点。

其实游戏离现实并不遥远,它无需绑缚在传统产业上也能体现其价值。
游戏本身就是一个前景巨大的产业,在解决了衣食住行这些人类最基本的需求之后,精神需求就被提上日程。
和读一本书、看一场电影相比,打一场游戏也并不低级。恰恰相反,在游戏中我们可能会更多用脑,完全主动地参与。
就像有些书是禁书,有些电影少儿不宜一样,游戏的内容也需要监督和把控。
在游戏产业中,不只游戏AI会用到人工智能技术,游戏的生产、运维中,也是处处都会涉及到AI技术。可以说人工智能技术在游戏产业中大有可为。
在被问到是否赞同“下一个AI里程碑可能会在复杂策略游戏中诞生”时,李文新表示她是非常认同的。因为现在越来越多的研究者正在兴趣盎然地研究这一问题。
不过,在她的眼里,游戏AI还有更深一层的意义:
游戏AI是活在游戏里的“人”,人也是活在人生的大戏中,两者可以互相启发。
……
最后,如果想要更加深入地走进李文新教授的游戏AI世界,敬请关注今年由CNCC举办的计算机大会。
本届大会中,李文新教授将会围绕《游戏AI算法与平台》展开讨论。

— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
第三届MEET大会启动,邀你见证智能科技新未来


量子位 QbitAI · 头条号签约作者
վ’ᴗ’ ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~
- 脑机接口走向现实,11张PPT看懂中国脑机接口产业现状|量子位智库2021-08-10
- 张朝阳开课手推E=mc²,李永乐现场狂做笔记2022-03-11
- 阿里数学竞赛可以报名了!奖金增加到400万元,题目面向大众公开征集2022-03-14
- 英伟达遭黑客最后通牒:今天必须开源GPU驱动,否则公布1TB机密数据2022-03-05





