
鱼羊 发自 副驾寺
智能车参考 报道 | 公众号 AI4Auto
通常,自动驾驶汽车通过单目摄像头看到的世界长这个样子:

马路上的其他车辆、物体,都被统一建模成一个个立方体,具体的结构细节则被忽略。
想要更精准地勾勒出车辆的真实形态,当然也不是不行,但那就需要用上激光雷达、双目相机等更加昂贵的传感器。
不过现在,一项最新研究赋予了单目摄像头新的能力——
是的,仅凭单目相机,就能实时感知物体的3D形状,进而提高3D目标检测性能。
这项研究来自百度,论文已经入选ICCV 2021。
考虑2D/3D形状感知约束的3D检测框架
具体如何实现?
大体上可以分为三步:
- 首先,引入CAD模型,在CAD模型上预先定义几个不同的3D关键点。
- 然后利用深度学习网络,来建立3D关键点和它们在图像上的2D投影之间的关联。
- 最后,利用这样的对应关系为每个目标物体建立2D/3D约束。
整体的网络架构如上图所示,8个分支头分别对应中心点分类、中心点偏移、2D关键点、3D坐标、关键点置信度、物体方向、维度,以及3D检测置信度得分。所有回归信息最后都会被用来恢复物体在摄像机坐标中的3D边界框。
而为了自动生成2D/3D关键点的真实标注,研究人员还提出了一种自动模型拟合方法。也就是根据摄像头观测到的2D图像,自动拟合不同的3D物体模型和物体掩码。
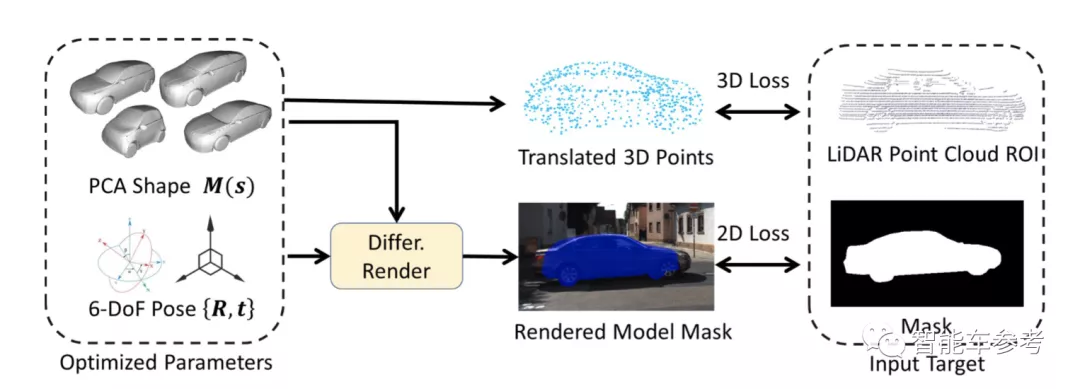
具体而言,该方法是基于不同种类的车辆CAD模型,以及KITTI数据集中的3D物体样本实现的。
研究人员指出,实际上,3D形状标注的过程可以看作一个优化问题,其目的是计算出最佳参数组合,来适应AI通过“视觉观察”得到的结果(如2D物体掩码、3D边界框、3D点云等)。
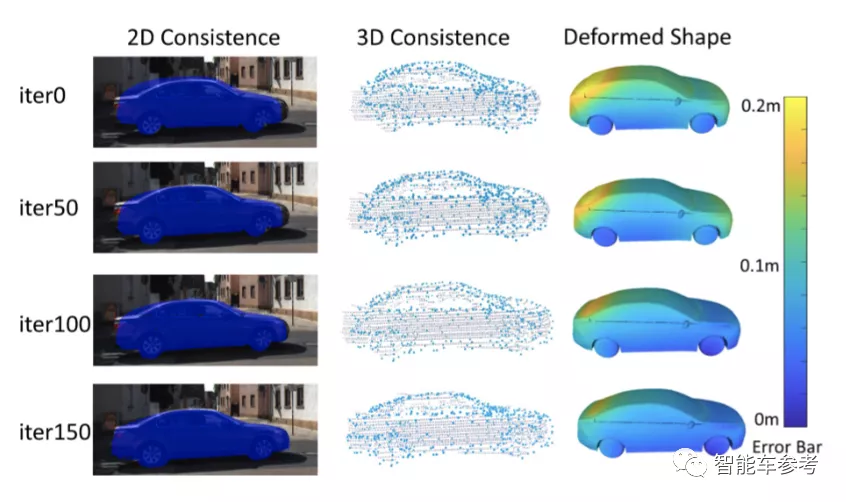
实验结果
研究人员在KITTI 3D目标检测基准上测试了这一新方法的性能。
KITTI 3D目标检测基准包含7481张训练图像、7518张测试图像,以及对应的点云,总共包括80256个标记对象。
在这项研究中,由于测试集的真实数据不可用,研究人员将训练数据分为训练集(3712个样本)和验证集(3769个样本),用以完善模型。
另外,用以测试的模型是在2块英伟达V100上训练完成的,批量大小设为16。
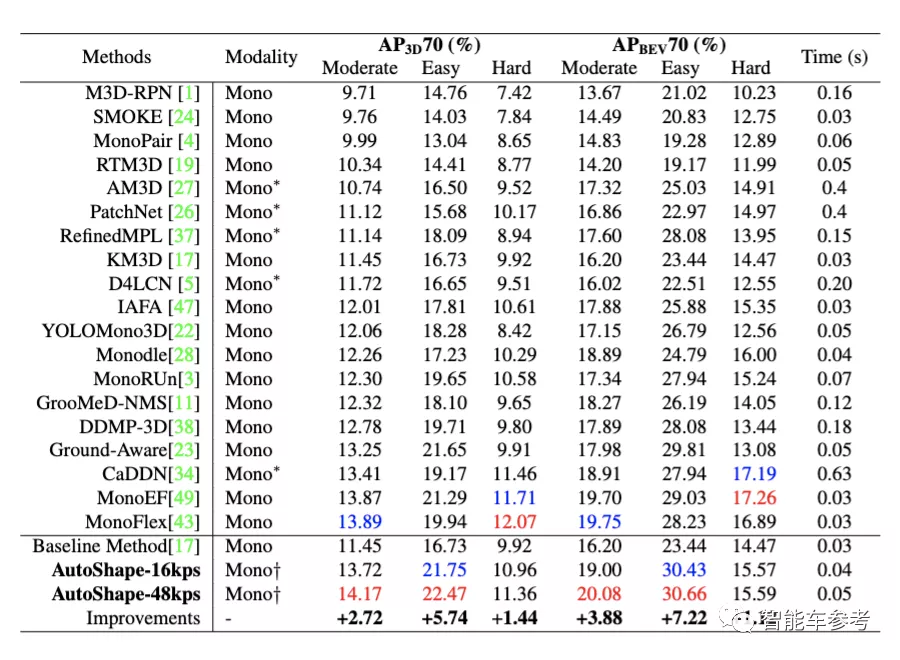
△红色代表最佳结果,蓝色代表次佳结果
可以看到,在全部6个任务中,采用了48个关键点的AutoShape方法取得了4项第一。而采用16个关键点的AutoShape速度更快,准确性损失也并不大。

此外,从上图中可以看出,模型预测的3D形状与真实物体一致性较高。
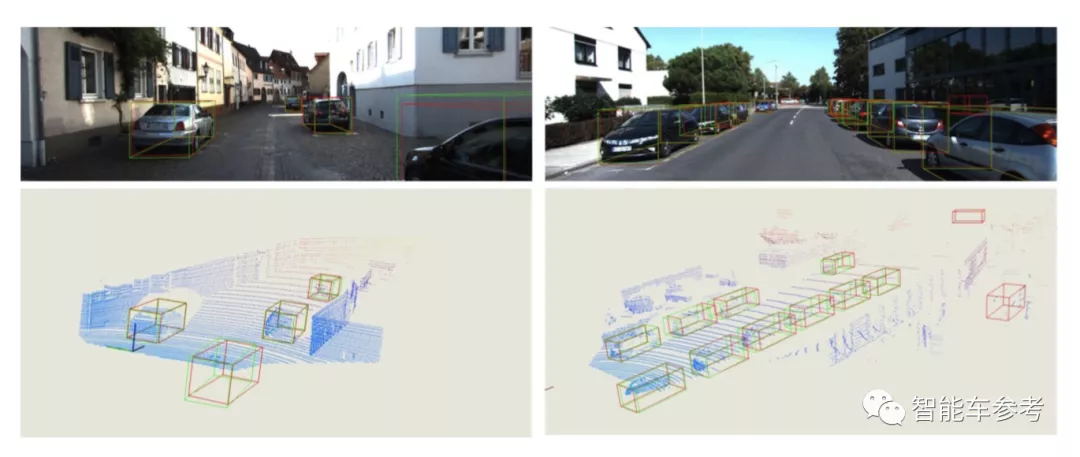
即使是画面中位置较远的车辆、被截断/遮挡的物体,其位置也能被准确检测到。
总而言之,相比于其他现有方法,AutoShape更准确,并且推理速度更快,可以达到25FPS的处理速度,也就是说可以实现实时检测的效果。
论文地址:
https://arxiv.org/abs/2108.11127
项目地址:
https://github.com/zongdai/AutoShape










