
UC伯克利博士尤洋回国创业,曾破ImageNet纪录!已获超千万融资
创新工场真格基金合投
明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
曾刷新ImageNet纪录的尤洋,回国创业了!

尤洋,何许人也?
他是LAMB优化器的提出者,曾成功将预训练一遍BERT的时间,从原本的三天三夜一举缩短到一个多小时。
作为一个通用的神经网络优化器,LAMB优化器无论是大批量还是小批量的网络都可以使用,也无需在学习率之外调试超参数。
据英伟达官方GitHub显示,LAMB比Adam优化器可以快出整整72倍。
微软的DeepSpeed,用的也是LAMB方法。
而这是尤洋在谷歌实习时作为论文一作提出的。
现在,他已经在UC伯克利获得了博士学位,带着LAMB方法回国,创立了潞晨科技。
公司主营业务包括分布式软件系统、大规模人工智能平台以及企业级云计算解决方案。
base北京中关村,目前已经获得由创新工场和真格基金合投的超千万元种子轮融资。
要高效率,也要低能耗
作为高性能计算领域的优秀青年学者,尤洋回国将在这一领域继续深耕。
事实上,高性能计算已经成为眼下前沿AI发展的必然选择。
随着AI模型的参数量越来越大,所需的算力也就越来越高,训练一次模型的时间也就变得十分漫长。
为此,科技巨头们纷纷部署了自己的集群和超算。
比如Google的TPU Pod,微软为OpenAI打造的1万GPU集群,英伟达的SuperPOD,以及特斯拉的Dojo计算机。

△谷歌数据中心
但是单纯地堆硬件,并不能解决所有问题。
一方面,当硬件数量达到一定量后,堆机器无法带来效率上的提升;
另一方面,中小企业往往没有足够的资金支持如此大规模的硬件部署。
因此,优化技术成为了绝佳选择。
潞晨科技就是旨在打造一个高效率低耗能的分布式人工智能系统。
它可以帮助企业在最大化提升人工智能部署效率的同时,还能将部署成本最小化。
而且潞晨打造的系统是一个通用系统,对大部分超大模型都有效。
就目前的Transformer应用而言,该系统在同样的硬件上相对业界最好的系统,可以提升2.32倍的效率。
而且随着机器数量的增长,这套系统的优势会越来越大。

考虑到现在的AI模型其实是往多维度发展的,尤洋在打造这套系统时还选择了动态模型并行技术。
这不仅能够适应现在模型的发展模式,还能极大提升计算效率。
那么,到底什么是AI模型的多维度发展呢?
比如,BERT是基于Transformer Encoder,GPT-3是基于Transformer Decoder,Switch Transformer和清华智源是基于混合专家系统。
同样,超算系统、联邦学习、跨云计算等硬件配置也会将系统复杂化。
这两者之间的自适应配置,将对整个训练系统的性能起着决定性影响。
为此,尤洋他们实现了2维网格参数划分、3维立体参数划分、以及2.5维通信最小化参数划分,极大提升了计算效率。
同时,他们还进行了逐序列划分数据,这可用于处理未来的大图片、视频、长文本、长时间医疗监控数据等方面的问题。
除了提升效率,尤洋他们还着重考虑了能耗问题。
事实上,能耗很可能会成为未来人工智能应用上的一个瓶颈。
根据Emma Strubell等人的研究,从纽约到旧金山每位旅客乘坐飞机产生二氧化碳排放量1,984 lbs。
然而,训练一个2亿参数的模型需要的能耗,就能达到626,155 lbs。
显而易见,低能耗计算十分必要。
尤洋他们在研究中发现,在不改变硬件设置的情况下,能耗主要来自于数据移动。
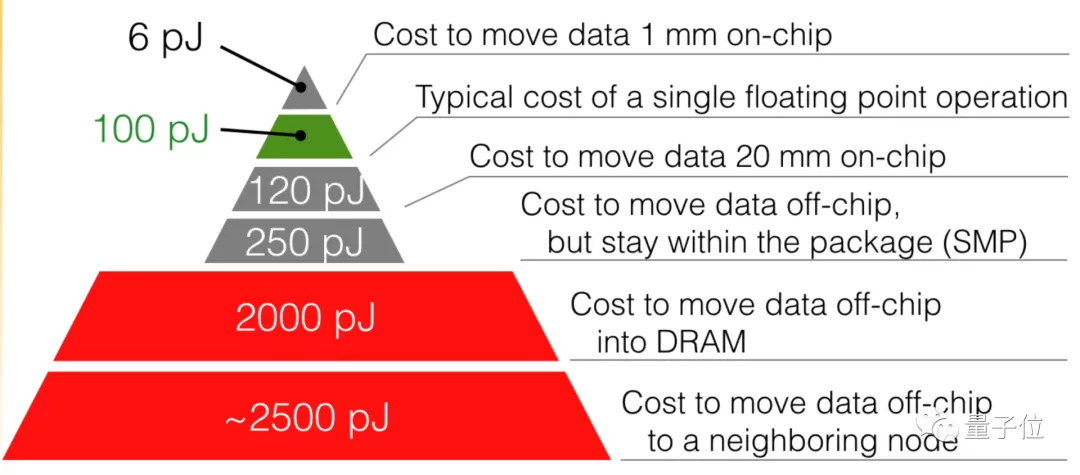
数据移动包括集群内服务器之间的通讯、GPU与CPU之间的通讯、CPU与磁盘的通讯等等。
为此,他们还实现了一套基于通讯避免算法的系统。可以在不增加计算量的情况下有效减少数据移动量,从而减少能耗。
核心技术
据尤洋介绍,以上他们打造的通用系统,依旧离不开LAMB方法。
LAMB的全称是Layer-wise Adaptive Moments optimizer for Batch training,和大家熟悉的SGD、Adam属于同类,都是机器学习模型的优化器(optimizer)。

之前我们也提到,LAMB无论是大批量还是小批量的网络都可以使用,也无需在学习率之外调试超参数。
靠着这一特点,此前尤洋等人将批大小由512扩展到了65536。
这也是第一次有研究用2000以上的超大批量来训练BERT。
带来的提升就是迭代次数会大大降低。
这让BERT-Large模型原本需要1000000次迭代才能完成预训练过程,有了LAMB加持用上大批量,只需要进行8599次迭代,这大幅缩短了预训练时间。
此外,尤洋等人最近提出的在线演化调度程序ONES,也是这套通用系统调用的一部分。
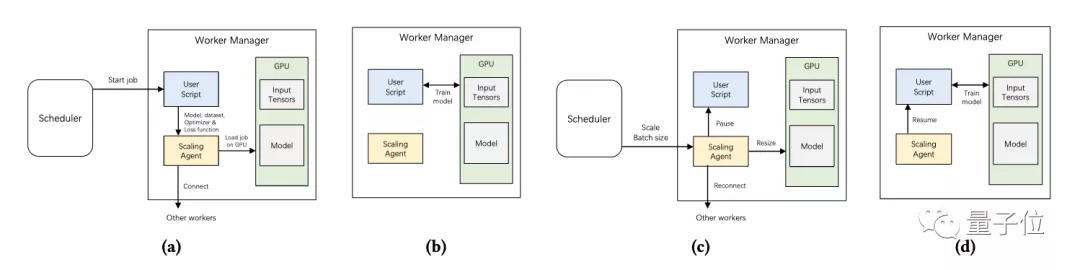
它可以根据批大小自动管理每个job,从而将GPU的利用率最大化。还能通过演化算法,不断优化调度决策。
评估结果表明,ONES与当前最先进的方法相比,在平均JCT(job completion time)上能够缩短45.6%的时间,优于现有的深度学习调度算法。
据悉,尤洋团队已经与多家企业展开合作。
他们表示,公司的战略是“先造锤子,再找钉子”。创业初期希望打造一个通用系统,1年内完成系统优化,用于中小型企业。
清华学子归国创业
说起尤洋,就不得不说一说他的“学霸史”了。

尤洋曾以第一名的成绩保送清华计算机系硕士。
后来在申请博士时,他从UC伯克利、CMU、芝加哥大学、UIUC、佐治亚理工、西北大学六所名校的全奖offer中,选择了UC伯克利。
读博期间,尤洋先后在Google Brain、英特尔实验室、微软研究院、英伟达、IBM沃森研究中心等知名企业、研究院实习,实习期间为TensorFlow、英伟达GPU上部署caffe、英特尔CPU部署caffe等大型知名开源项目作出了贡献。

△实习期间尤洋曾去老黄家开party
博士毕业时,尤洋还获得了颁发给UC伯克利优秀毕业生的Lotfi A. Zadeh Prize,并被提名为ACM Doctoral Dissertation Award候选人(81名博士毕业生中选2人)。
毕业后,他加入新加坡国立大学计算机系,担任校长青年教授 (Presidential Young Professor)。
在学术研究上,尤洋也同样战绩斐然。
他曾以一作的身份获得2015年国际并行与分布式处理大会(IPDPS)的最佳论文和2018年国际并行处理大会(ICPP)最佳论文奖。
其发表论文《Imagenet training in minutes》所提出的方法刷新了ImageNet训练速度的世界纪录。
2021年,他还被选入福布斯30岁以下精英榜 (亚洲)。
事实上,潞晨团队可不止尤洋一位大神。
其团队核心成员来自美国加州大学伯克利分校、斯坦福大学、清华大学、北京大学、新加坡国立大学、新加坡南洋理工大学等国内外知名高校。
核心团队在高性能计算、人工智能、分布式系统方面已有十余年的技术积累,并在国际顶级学术刊物或会议发表论文30余篇。
此外,还有美国科学院院士,工程院院士James Demmel教授担任团队顾问。
Demmel教授是加州大学伯克利分校前EECS院长兼计算机系主任、中关村战略科学家、ACM/IEEE Fellow,现任加州大学伯克利分校杰出教授。

目前,潞晨科技还在广纳英才。招聘全职/实习软件工程师,全职/实习人工智能工程师。
岗位职责主要有:
- 开发分布式人工智系统并部署到大规模集群或云端。
- 从具体的场景和问题出发,研发和优化算法系统,产出解决方案应用到场景中。
- 参与人工智能技术与现有工具的融合设计和优化,提高产品性能。
- 撰写高质量的科技论文,有机会担任重要论文的第一作者 (未来换工作或升学的重要加分项)。
任职要求为:
- 精通TensorFlow, PyTorch, Ray, DeepSpeed, NVIDIA Megatron,熟悉上述系统的内部运行机制。
- 熟悉各类优化算法与模型架构,熟悉python或C++的优化算法库,包括各类基于梯度的经典算法与经典模型 (BERT, GPT-3, Switch Transformer, ViT, MLP-Mixer)。
- 有较强的编程能力和工程实现能力。获得过编程竞赛奖或发表过高质量论文的优先录用。
- 211、985、海外知名高校本科以上学位(或在读),计算机科学、软件工程,电子信息,自动化,数学,物理或其它人工智能相关专业。
如果想入职潞晨,不知道现在恶补还来得及吗?
简历投递邮箱:
luchen.tech@gmail.com
- 大模型竞技场再被锤!Llama4私下测试27个版本,只取最佳成绩2025-05-02
- 微软CEO和奥特曼失了和,OpenAI被“断粮”2025-05-02
- 多邻国全面AI First!AI能胜任的工作,都不会再新招人2025-04-30
- 中关村科金喻友平: 平台+应用+服务是企业大模型落地的最佳路径2025-04-28










