用上GAN的推荐算法成精了,看完视频马上刷出相关文章丨KDD 2021
微信已经用上了
萧箫 整理自 KDD 2021
量子位 报道 | 公众号 QbitAI
这年头,推荐算法真是越来越智能了。
举个栗子,当你热衷于东京奥运会并且刷了不少剪辑视频,APP就会根据你的品味为你推荐文章、游戏或是同款周边。

没错,推荐算法早已不局限于一个场景,而是在视频、文章、小程序等各种场景中“打通任督二脉”,也就是多领域推荐算法。
但事实上,这类算法并不如想象中容易驾驭,关键在于如何抓住不同领域中,关于目标领域的有效特征。
为了让推荐算法更了解你,腾讯微信的看一看团队,针对多领域推荐任务提出了一个全新的模型,融合了生成对抗网络GAN、ELECTRA、知识表示学习等思路,学习不同领域之间的特征转移,极大地提升了多领域推荐算法的效果,论文已被KDD 2021收录。
8月18日,数据挖掘领域国际最高级别会议KDD 2021会议在线上举行,微信看一看团队的Xiaobo Hao,针对这篇名为「Adversarial Feature Translation for Multi-domain Recommendation」的论文,进行了详细解析和分享。

我们对论文解析进行了相关总结,一起来看看。
多领域推荐难在哪
推荐系统已经融入生活的方方面面,为我们提供个性化的信息获取及娱乐。
在马太效应的影响下,Google、WeChat、Twitter等平台应运而生。它们往往拥有各种(推荐)服务,能够为用户推荐多样化的物品(如文章、视频、小程序等),满足用户需求。
用户在不同推荐服务上的行为(在用户允许下),会通过用户的共享账号产生关联。
这些行为,能在目标领域行为之外提供更多信息,帮助推荐系统更加全面地了解用户,辅助提升各领域推荐效果。
多领域推荐 (Multi-domain recommendation,MDR)任务就是基于用户在多个领域的行为和特征,来同时优化多个领域的推荐效果,关键在于如何抓住不同领域中的目标领域特化的特征。
一个直观的方法,是将用户的多领域行为当作额外的输入特征,直接输入给ranking模型,但这种方法没有针对领域间的特征交互进行优化建模。
另一个方法,是近期基于多任务学习(Multi-task learning,MTL)的一些思路,将一个领域的推荐当作一个任务进行处理,取得了不错的效果。
然而,多领域推荐效果仍然严重地受限于其固有的稀疏性问题,具体体现在两个方面:其一,user-item点击行为的稀疏性(这个是推荐系统本身拥有的稀疏性问题);其二,跨领域特征交互的稀疏性(这是多领域推荐特有的稀疏性问题)。
AFT模型要解决什么?
为了解决这两个问题,使模型能够同时提升多领域推荐效果,论文提出了一个名为Adversarial Feature Translation(AFT)的模型,基于生成对抗网络(GAN)学习不同领域之间的特征转移(feature translation)。
首先,在multi-domain generator中,论文先提出了一个domain-specific masked encoder,用以强调跨领域的特征交互建模,再基于transformer层以及domain-specific attention层聚合这些跨领域交互后的特征,学习用户在目标领域下的表示,以生成虚假的物品候选(fake clicked items)输入到判别器中。
在multi-domain discriminator中,受到知识表示学习(KRL)中的基于三元组的建模方法(如TransE)的启发,论文构建了一个两阶段特征转移(two-step feature translation)模型,对领域、物品和用户不同粒度/不同领域的偏好进行可解释的建模。
团队在Netflix和微信多领域推荐数据集上进行了测试后,发现模型在离线和在线实验的多个结果上都获得了显著的提升,论文也进行了充分的消融实验和模型分析,以验证模型各个模块的有效性。
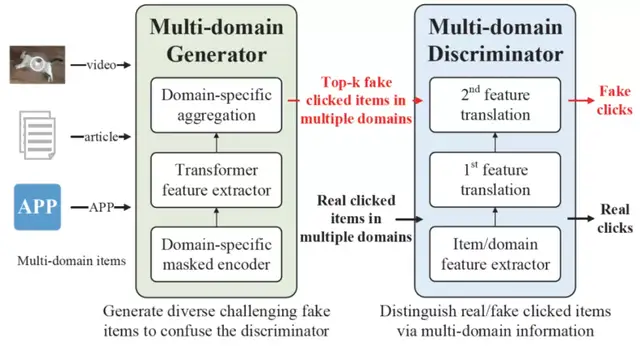
△图1:多领域推荐及AFT模型框架图
具体来说,如上图1,AFT包括domain-specific masked encoder以及two-step feature translation,着重关注跨领域、多粒度的特征交互建模。
在生成器 (generator)部分,论文先设计了一个domain-specific masked encoder,通过mask掉目标领域的历史行为特征(historical behaviors),来加强“其它领域历史行为特征”和“目标领域点击行为”之间的交互特征权重,以驱使AFT模型学习基于其它领域特征进行的目标领域推荐;
再用Transformer层和Domain-specific aggregation来抽取目标领域相关的用户特征,以生成top-k虚假点击的物品(fake clicked items)。这些虚假点击的物品将被输入判别器,迷惑判别器的判断,在对抗中相互提升所有领域的推荐能力。
在判别器 (discriminator)部分,论文受知识表示学习模型(KRL)启发,希望显式地对用户、物品和领域进行建模。
其中,先用Transformer从多领域特征中分别抽取用户的细粒度item和粗粒度domain的偏好特征,分别标记为user item-level preference和user domain-level preference;
再构造第一个三元组(user item-level preference,user domain-level preference,user general preference),进行第一次特征转移,学习用户通用领域的偏好特征(user general preference)。第一个三元组的物理含义是,对于(Hamlet,writer,Shakespeare)三元组关系,有Hamlet+writer=Shakespeare(以KRL中的经典模型TransE为例)。
在多领域推荐中,用户不同粒度的偏好相加(item-level preference+ domain-level preference),就约等于用户通用领域的偏好(user general preference),因此这一步能得到用户通用领域的偏好。
然后,论文再次构建第二个三元组(user general preference, target domain information, user domain-specific preference),进行第二次特征转移。第二个三元组的物理含义是,用户的通用领域偏好+目标领域的特征=用户在目标领域的偏好(user domain-specific preference)。
论文基于成熟的知识表示学习模型ConvE进行两层特征转移(two-step feature translation)后,得到了用户在目标领域上的表示,并用于推荐。
那么,AFT模型到底有什么优势?
其一,AFT的GAN框架在domain-specific masked encoder的帮助下,提供了充足且高质量的多领域推荐负例,缓解了数据稀疏和过拟合的问题;
其二,生成器中的domain-specific masked encoder能加强模型的跨领域特征交互,而这正是多领域推荐的核心要素;
其三,判别器中的two-step feature translation提供了一种大胆的、显式化可解释的建模用户、物品和领域的方式,对多领域推荐提供了更深层次的理解。
团队将AFT模型和多个有竞争力的baseline模型进行了离线和线上对比。结果显示,AFT模型在多个领域上全面显著地超出所有baseline。此外,团队还进行了详尽的消融实验和模型分析实验,用以加深对AFT各个模块和参数的理解。
目前,AFT模型已经在用了——被部署于微信看一看的多领域推荐场景,正服务于千万用户。论文本身的贡献如下:
- 针对多领域推荐问题,提出了一个全新的AFT框架,首次在多领域推荐中引入了对抗下的特征转移。
- 提出了一种GAN框架下的domain-specific masked encoder,能够针对跨领域特征交互进行特化加强。
- 设计了一种两阶段特征转移策略,尝试使用结构化知识表示学习的建模方式,学习用户多粒度多领域偏好、物品和领域之间的可解释的转移关系。
- AFT在离线和线上实验中均取得显著的提升效果,并已经被部署于微信看一看系统。
AFT模型具体长啥样
上文提到,AFT模型基于GAN训练框架,主要分为生成器和判别器两个部分。
如下图2,生成器输入用户多领域行为特征,并基于domain-specific masked encoder、Transformer层和Domain-specific attention,抽取目标领域相关的用户特征,用于生成top-k虚假点击的物品(fake clicked items)。判别器则基于两阶段特征转移,获得用户向量,然后预测真实/虚假点击物品的得分。
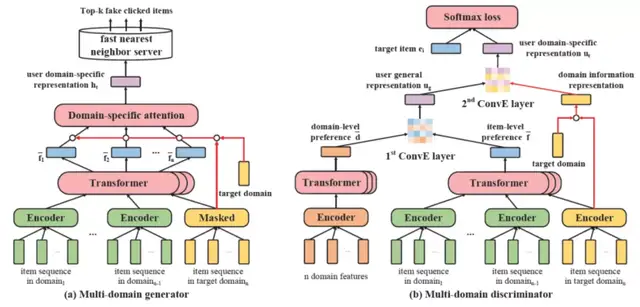
△图2:AFT具体模型,包括(a)多领域生成器和(b)多领域判别器
我们具体来看。
多领域生成器
多领域生成器旨在为用户生成每个领域上的fake clicked items,其输入是某个用户在所有n个领域上的行为序列X={X_1, …, X_n},其中X_t是第t个领域上的行为序列特征矩阵。
不失一般性,论文假设生成器正在生成目标领域d_t上用户可能点击的物品,首先使用domain-specific masked encoder处理目标领域序列X_t,随机对目标领域d_t中的行为进行mask,如下式:
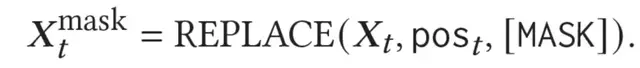
公式表示序列中pos_t这些位置上的行为被[mask]的token替代,使得domain-specific masked encoder强制生成器在生成目标领域的候选物品时,会更多地考虑其它领域的用户行为。
这样虽然会丢失关键的目标领域的历史行为,导致生成器更难生成最合适的fake clicked items,但也会加强跨领域历史行为和点击的特征交互,有助于多领域推荐,特别是稀疏行为的领域上的推荐效果,瑕不掩瑜。
随后,论文使用average pooling分别聚合各个领域上(mask后)的行为序列,并基于Transformer和domain-specific attention,得到用户在目标领域上的表示h_t如下:
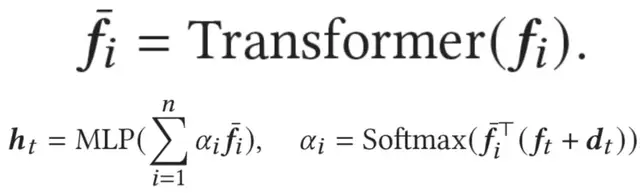
对每个候选物品e_i,生成器计算的点击概率p为:
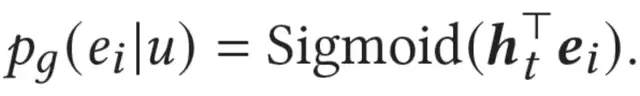
论文基于生成概率p,选择目标领域上的top k的近邻物品(剔除训练集中的真实正例),作为生成器生成的负例输入判别器。
多领域判别器
在判别器中,论文首先基于Transformer特征抽取器,获取用户在细粒度的具体行为(item)上和在粗粒度的领域(domain)上的特征表示:
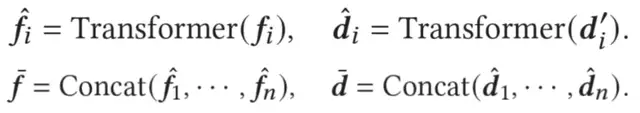
随后,团队基于知识表示学习中三元组的学习范式,设计了一个两阶段的特征转移:先基于用户在多领域的细粒度和粗粒度上的偏好,得到用户整体偏好;然后基于用户整体偏好和目标领域信息,得到用户在目标领域上的偏好。
传统的知识表示学习方法(如TransE)显式建模三元组关系。上文提到,对于(Hamlet, writer, Shakespeare)这个三元组关系,TransE认为:Hamlet+writer=Shakespeare。
因此,用户细粒度的偏好加上用于粗粒度的偏好,应该等于用户通用领域上的全局偏好(user general preference)。基于ConvE模型(因为他能够挖掘element-wise的特征交互),对于三元组(e_h, r, e_t)有:
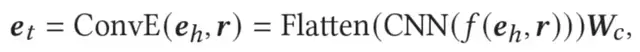
类似地,在第一次特征转移中,构造了一个三元组(user item-level preference, user domain-level preference, user general preference),计算用户通用领域上的全局偏好u_g如下:

在得到user general preference后,又构建了第二个三元组(user general preference, target domain information, user domain-specific preference),并进行第二次特征转移。这个三元组的物理含义是,用户的通用领域偏好加上目标领域的特征,约等于用户在目标领域的偏好(user domain-specific preference),有:

其中,目标领域特征综合考虑了领域向量和行为向量。与生成器类似,团队基于用户在d_t的特征表示u_t,计算物品e_i的点击概率p如下:

生成器&判别器优化
模型判别器的优化如下:

生成器则是基于REINFORCE强化学习进行优化:
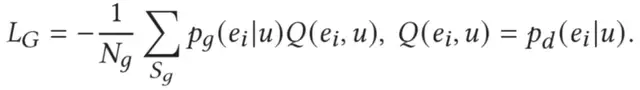
团队还提出一项MMD loss,目的是让生成器产生的物品和真实物品不完全一致(否则会干扰判别器的训练),具体如下:
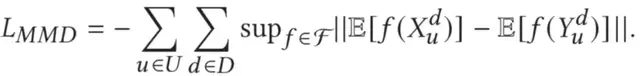
MMD loss基于推荐系统的特质设计:在推荐系统中,绝大多数物品其实并未被曝光,团队假设所有未被用户点击的物品均为负例;和点击物品特别相似的fake clicked items,也有很大概率同样被用户点击(例如不同自媒体号发表的同一主题的新闻/视频等),这也是推荐系统item-CF的本质。
因此,团队选择加入MMD loss,使得GAN能够生成更加多样化的、相似但又不完全一样的物品作为判别器的负例。
最后,综合三项loss获得最终AFT的loss,如下:

AFT模型的判别器被部署于线上,更多模型和线上细节可参考论文第三和第四部分。
实验结果
团队在公开数据集和微信看一看数据集上进行了实验,结果表明,模型在多领域推荐上获得了显著提升:
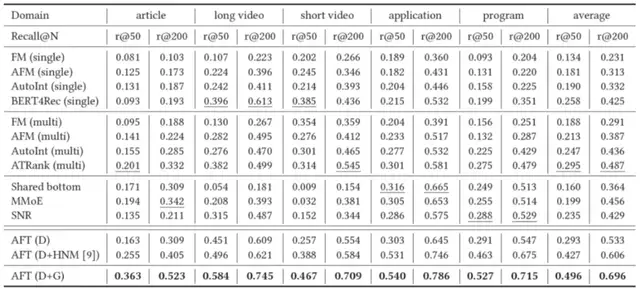
△图3:AFT离线结果
此外,论文也在微信看一看多个线上推荐场景进行了A/B实验,也同样获得了显著的提升:
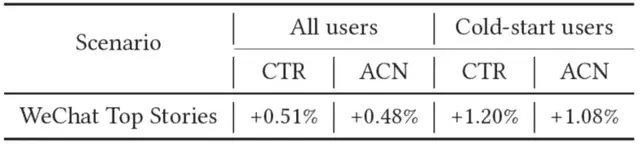
△图4:AFT线上实验结果
消融实验也证明了模型各个模块的有效性:
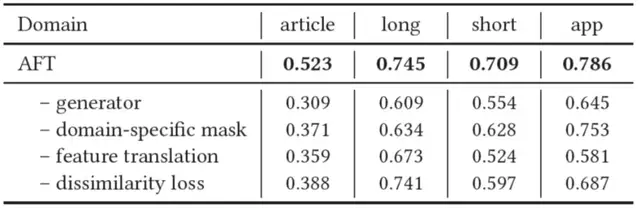
△图5:AFT消融实验
最后,论文也进行了详尽的模型参数分析,探索了不同mask ratio和fake clicked item number对模型效果的影响:
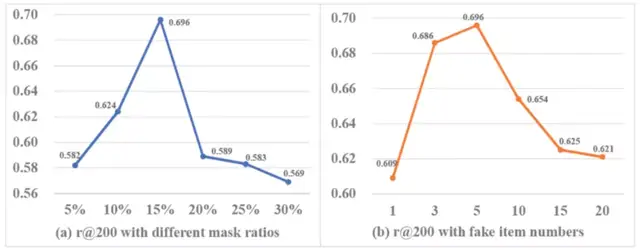
△图6:AFT参数实验
模型已用到微信里
整体来说,这篇论文针对多领域推荐任务,提出了一个对抗特征转移的AFT模型。它基于domain-specific masked encoder加强了跨领域特征交互,设计了一种two-step feature translation,能够显式可解释地对多领域下用户不同粒度的偏好、物品和领域进行建模。
目前,AFT模型已部署于微信看一看多领域推荐模块中,我们日常用微信看一看时,就会用到这个模型。
对于未来,团队表示十分看好基于对抗和知识表示学习的跨领域特征交互思路,计划展开进一步探索。
参考文献:
[1]Bordes A, Usunier N, Garcia-Duran A, et al. Translating embeddings for modeling multi-relational data[C]//Neural Information Processing Systems (NIPS). 2013: 1-9.
[2]Covington P, Adams J, Sargin E. Deep neural networks for youtube recommendations[C]//Proceedings of the 10th ACM conference on recommender systems. 2016: 191-198.
[3]Dettmers T, Minervini P, Stenetorp P, et al. Convolutional 2d knowledge graph embeddings[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2018, 32(1).
[4]Dziugaite G K, Roy D M, Ghahramani Z. Training generative neural networks via maximum mean discrepancy optimization[J]. arXiv preprint arXiv:1505.03906, 2015.
[5]He R, Kang W C, McAuley J. Translation-based recommendation[C]//Proceedings of the eleventh ACM conference on recommender systems. 2017: 161-169.
[6]Huang J T, Sharma A, Sun S, et al. Embedding-based retrieval in facebook search[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 2553-2561.
[7]Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1930-1939.
[8]Song W, Shi C, Xiao Z, et al. Autoint: Automatic feature interaction learning via self-attentive neural networks[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1161-1170.
[9]Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer[C]//Proceedings of the 28th ACM international conference on information and knowledge management. 2019: 1441-1450.
[10]Wang J, Yu L, Zhang W, et al. Irgan: A minimax game for unifying generative and discriminative information retrieval models[C]//Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval. 2017: 515-524.
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07