谷歌提出「卷积+注意力」新模型,超越ResNet最强变体!
大神Quoc Le参与研究。
Transformer跨界计算机视觉虽然已取得了一些不错的成绩,但大部分情况下,它还是落后于最先进的卷积网络。
现在,谷歌提出了一个叫做CoAtNets的模型,看名字你也发现了,这是一个Convolution + Attention的组合模型。

该模型实现了ImageNet数据集86.0%的top-1精度,而在使用JFT数据集的情况下实现了89.77%的精度,性能优于现有的所有卷积网络和Transformer!

卷积结合自注意,更强的泛化能力和更高的模型容量
他们是如何决定将卷积网络和Transformer结合起来造一个新模型呢?
首先,研究人员发现,卷积网络和Transformer在机器学习的两个基本方面——泛化和模型容量上各具优势。
由于卷积层有较强的归纳偏置(inductive bias),所以卷积网络模型具有更好的泛化能力和更快的收敛速度,而拥有注意机制的Transformer则有更高的模型容量,可以从大数据集中受益。
那将卷积层和注意层相结合起来,不就可以同时获得更好的泛化能力和更大的模型容量吗!
那好,关键问题来了:如何有效地将它们结合起来,并在准确性和效率之间实现更好的平衡?

研究人员又发现,常见的深度卷积(depthwise convolution)只需简单的相对注意就可以合并进注意力层!
因此,他们将CoAtNets的实现分为两步:
1、将卷积和自注意结合在一个基本计算块中;
2、将不同类型的计算块垂直堆叠在一起(垂直布局设计),形成完整的网络。
具体实现
首先,由于Transformer和MBConv中的FFN模块都采用了“反向瓶颈”的设计,加上深度卷积和自我注意都可以用预定义的感受野中的加权和来表示,CoAtNets主要采用MBConv卷积块。
具体来说,卷积依赖于一个固定核从局部感受野收集信息:
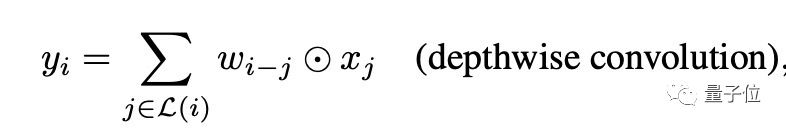
相比之下,自注意允许感受野成为整个空间位置,并基于对(xi,xj)之间的重归一化成对相似性来计算权重:
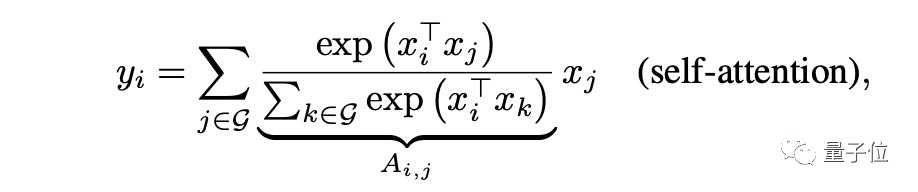
将它们以最佳形式结合之前,研究人员比较了一下两者各自的理想特性。
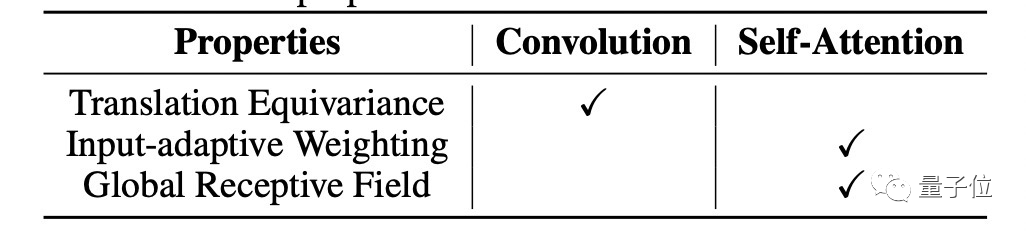
一个结合深度卷积和自注意的理想模型需要具备以上3个特性,而研究人员的实现方法很简单:在Softmax归一化前或后,将全局静态卷积核与自适应注意矩阵求和。

将卷积和注意力结合起来之后,就可以开始堆叠整个网络。
全局上下文在空间大小(spatial size)方面具有二次复杂性,如果直接将上述公式中的相对注意应用到原始图像输入,会因为普通尺寸图像中过多的像素,导致计算速度过慢。
因此,要构建一个在实际操作中可行的模型,研究人员选择在feature map达到可管理水平后,进行一些下采样以减小空间大小,再使用全局相对注意。
其中下采样可以像ViT那样用具有积极步幅(stride,例如16×16)的 convolution stem或像ConvNets里具有渐进池的多级网络来实现。
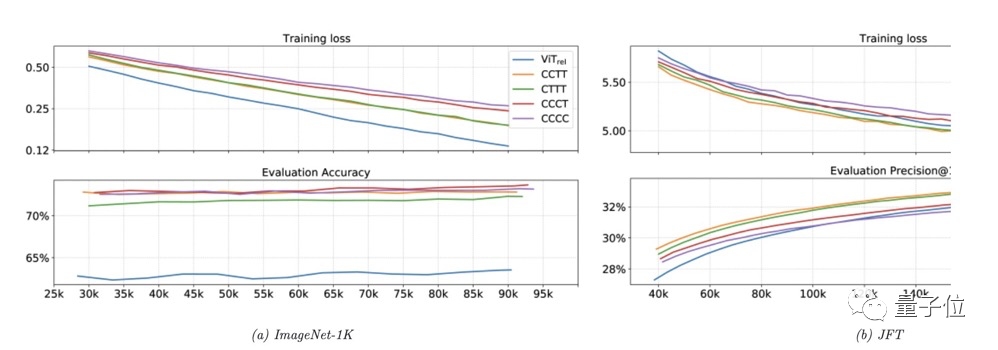
研究人员按照上面两种方法堆叠出5个变体:C-C-C-C、C-C-C-T、C-C-T-T和C-T-T-T以及ViTᵣₑₗ,其中C和T分别表示卷积和Transformer。
为了作出选择,他们进行了对照实验,选出了泛化能力和模型容量最好的两个:C-C-T-T和C-T-T-T,优中选优,最终选择了迁移性能更好的C-C-T-T。
至此,完整的CoAtNets模型就实现了。
NO.1的top-1精度
其实,将卷积和自注意相结合用于计算机视觉的想法并不新鲜,但此前的一些方法通常会带来额外的计算成本等问题。
而他们的相对注意实例化是深度卷积和基于内容的注意力的自然结合,加上优中选优的垂直布局设计,新模型CoAtNets造成的额外成本最小。
下面就来看具体的实验数据:
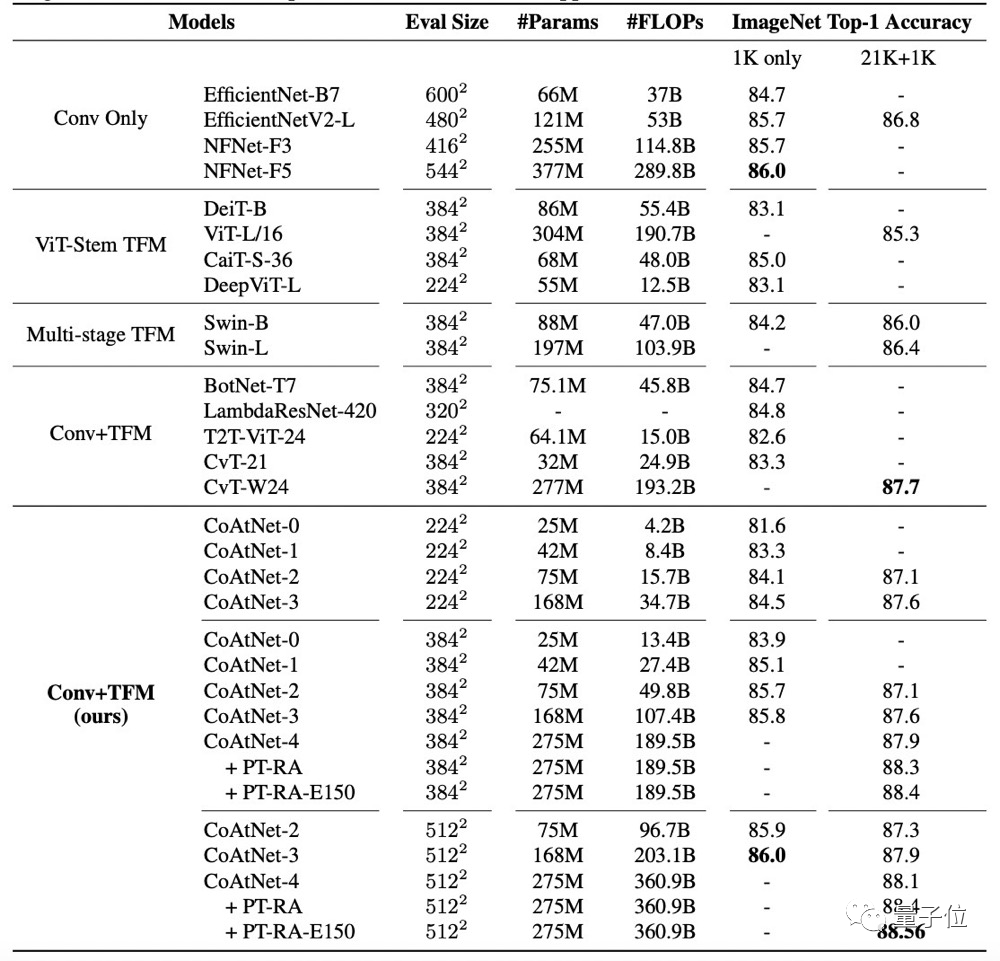
仅使用ImageNet-1K数据集的实验结果表明:CoAtNet不仅优于ViT变体,还能匹敌最佳的仅卷积结构(EfficientNet-V2和nfnet)。
从上表和下图还可以看出:使用ImageNet-21K进行预训练,CoAtNet的优势变得更加明显,大大优于以前的所有模型。
且最好的CoAtNet变体实现了88.56%的top-1精度,而与之匹敌的ViT-H/14则需要在23倍大的JFT数据集上预先训练2.3倍规模的ViT才能达到88.55%的成绩。
这标志着CoAtNet模型数据效率和计算效率的显著提高。
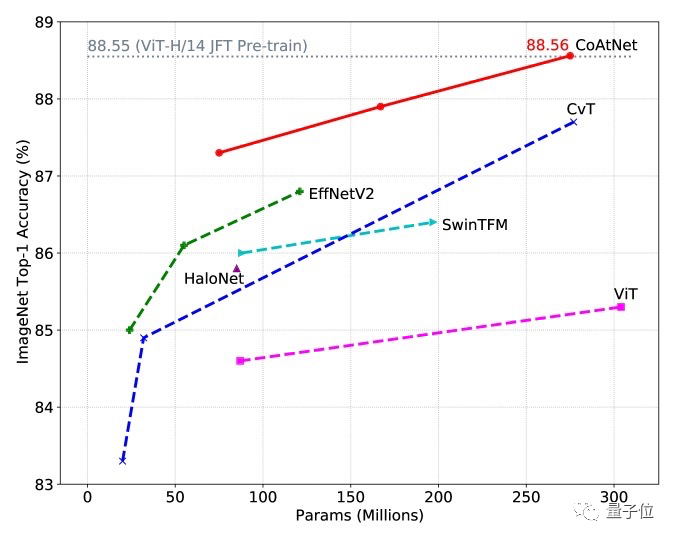
△ ImageNet-21K ⇒ImageNet-1K 的参数精度
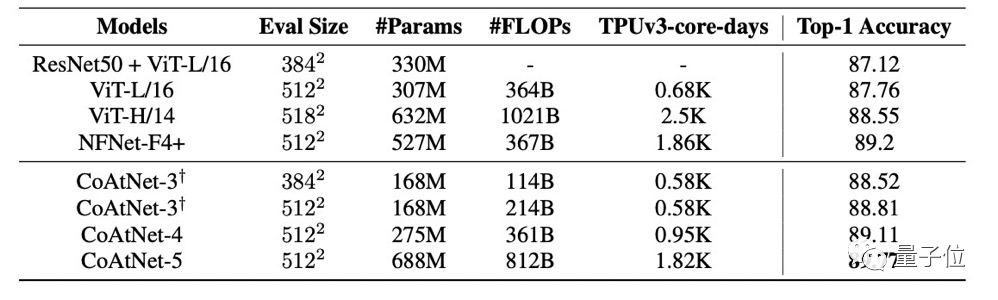
最后,研究人员用JFT进一步评估了大规模数据集下的CoAtNet,发现它达到89.77%精度,超过ResNet最强变体NFNet-F4+排名第一,同时在TPU训练时间和参数计数方面提高了2倍效率。
作者介绍
论文的四位作者全部来自谷歌大脑。

Dai Zihang,本科清华大学工商管理专业,硕士卡内基梅隆大学计算机专业,博士卡内基梅隆大学计算机和哲学双学位。

刘寒骁,同为清华本科,卡内基梅隆大学计算机博士,谷歌大脑高级研究科学家,曾在DeepMind研究神经架构搜索。

Quoc Le,这位大佬应该很多人都知道,斯坦福大学计算机科学博士毕业,吴恩达的学生,谷歌大脑的创始成员和 AutoML 的缔造者之一。

Tan Mingxing ,北京大学博士毕业、康奈尔大学博士后。
论文地址:https://arxiv.org/abs/2106.04803
- 北大开源最强aiXcoder-7B代码大模型!聚焦真实开发场景,专为企业私有部署设计2024-04-09
- 刚刚,图灵奖揭晓!史上首位数学和计算机最高奖“双料王”出现了2024-04-10
- 8.3K Stars!《多模态大语言模型综述》重大升级2024-04-10
- 谷歌最强大模型免费开放了!长音频理解功能独一份,100万上下文敞开用2024-04-10