北大95后「AI萝莉」回来了,一次中8篇顶会论文的她,现在达摩院开源7大NLP模型
“论文大户”来到工业界,她发现复杂的技巧并不实用,简单有效的模型才是最赞的。
梦晨 博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
曾有一位北大硕士生,在校期间一次性在国际顶会ACL中标8篇论文,其中2篇一作,还登上了知乎热搜。
在那次热搜之后,这位“论文大户”似乎逐渐销声匿迹。
今天,她带着阿里达摩院深度语言模型体系AliceMind回来了。
这位被外界称为“AI萝莉”的罗福莉,就负责这次AliceMind中7个模型的开源。

她的经历说起来有点“传奇”。
上大学之前没怎么接触过电脑,却误打误撞进了北师大计算机专业。
刚入学时因没有基础成绩垫底,靠着努力跃升到前一、二名。
大三时进入北大语言计算实验室实习,选择了NLP作为自己的科研方向,在3个月内自学Python并投出一篇顶会论文(非一作)。
保研进入北大,硕士两年间在国际顶会上发表了超过20篇论文。
但她出人意料地没有选择继续读博,而是在2020年毕业之后就加入了阿里达摩院,想做点实在的研究。
进入工业界这两年,她发的论文明显减少了。
在读书的时候,周围的评价机制都是非常在意你的论文数量。但是到工业界,我现在已经不追求数量了,主要是追求做这个工作是不是真的有落地价值,是不是在这个领域有一些影响力。
她在达摩院主导开发了跨语言预训练模型VECO,成为AliceMind八大模型之一。这次AliceMind集体开源,她挑起了大梁。

简单的才是最赞的
罗福莉在业界工作这一年,与在学术界时相比心态上有了很大的转变:
在学校的时候总是追求提出一个很复杂的模型,大家看不懂,论文评审人也看不懂,但是到工业界的时候就会发现一眼就能看懂并且还有效的模型才是最赞的。
这也是她所在的达摩院深度语言模型团队的思路,他们打造的AliceMind八大模型先后登顶了GLUE、CLUE、XTREME、VQA Challenge、DocVQA、MS MARCO六大NLP权威榜单。
AliceMind中Alice的含义其实很简单,就是Alibaba’s Collection of Encoder-decoders。
其中的模型也像这个名字一样朴实,都是从实际业务需要出发,在Encoder-decoder的基础上进行创新和改进。
通用语言模型StructBERT,在BERT的基础上增加了词级别和句级别的两个新目标函数,相当于让AI掌握了“汉字序顺不响影读阅”这个能力。
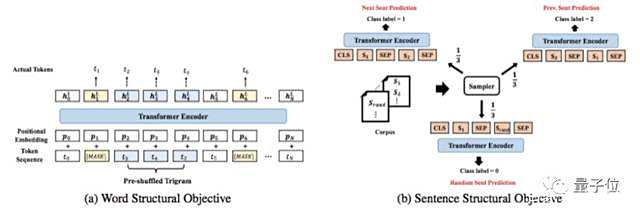
这是因为团队在阿里的业务中发现,用户在电商、娱乐产品等轻松地使用场景时,经常出现语法、语序不正确等现象。
这就需要让语言模型在面对语序错乱、语法不规范的词句时,仍能准确理解并给出正确的表达和回应。
AliceMind刚刚还再次登顶了多模态权威榜单VQA Challenge 2021。
VQA Challenge的比赛任务类似看图问答,给定一张图像和关于图像的自然语言问题,AI需要提供准确的自然语言答案。
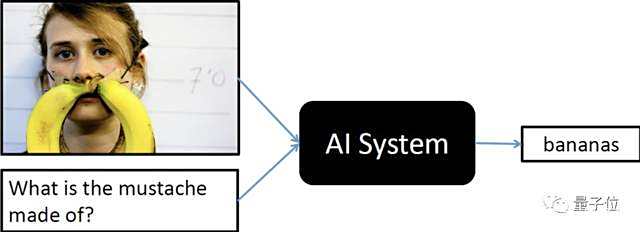
对此,AliceMind的多模态模型StructVBERT,在通用模型StructBERT的基础上,同时引入文本和图像模态。
利用更高效的视觉特征和创新的交叉注意力机制,在统一的多模态语义空间进行联合建模。
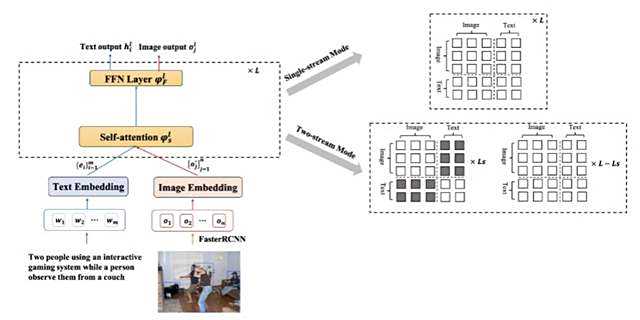
除了跨模态,罗福莉主导的跨语言模型VECO也被顶会ACL2021录用。
VECO中也引入了交叉注意力机制,改变了以往跨语言信息在隐藏层中自动建模的不稳定性,而是“显式”地完成。
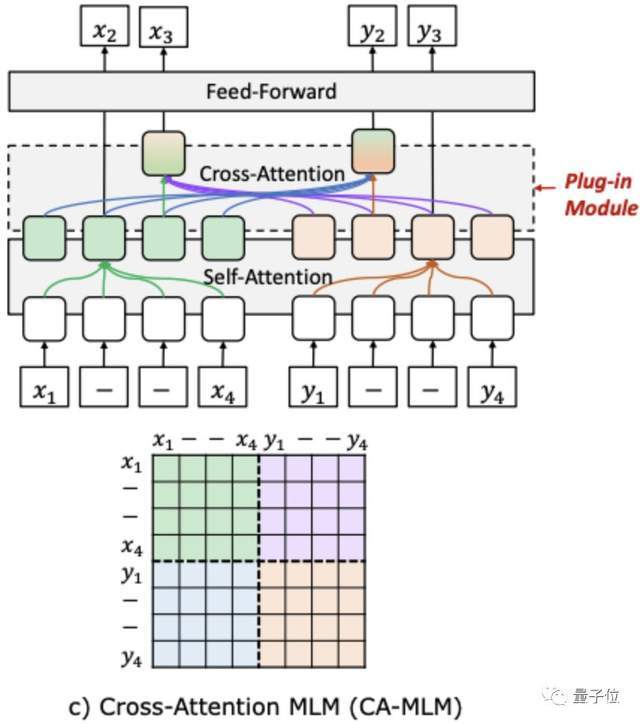
VECO的另一项创新是在预训练的过程中,充分学习用于语言理解(NLU)和生成(NLG)任务,并让二者互相学习提高彼此。
如今罗福莉再回顾VECO这个工作,也有一些感慨:
如果是两年前还在学校的我,会觉得这好简单,我可以加上很多的花式技巧。但是到了工业界要考虑到架构在不同业务场景下的通用性,只好牺牲一些复杂有趣的模型设计。
AliceMind中的生成式语言模型PALM,则是将预训练目标从重构输入文本,改成了预测后续文本。
这样一个改动就促使模型对输入文本进行更深入地理解,在问答生成、文本复述、回复生成、文本摘要等任务上都取得了更好的效果。
还有结构化语言模型StructuralLM、机器阅读理解模型UED和知识驱动的语言模型LatticeBERT,都在各自的领域取得了明显地优势。
除了此次开源的7个模型,AliceMind中还包括了超大规模中文理解和生成统一模型PLUG。
AliceMind中的模型,看起来有一个共同特点,就是擅长”跨界“。
从跨语言、跨模态到语言理解和生成的统一,都是基于Transformer架构将不同地输入在一个更大的编码空间上统一建模。
罗福莉补充道:
AliceMind的这种将Transformer作为统一模型架构的解决方案已经比较成熟,但要做到更好“跨界”,接下来努力的方向是解决不同类型或粒度输入的深度融合和匹配问题。
从基础模型扩展出能力多样的模型,再把它们在实际业务中结合使用,让AliceMind成了业界能力最全面的深度语言模型体系。
那么AliceMind都用到了哪些地方?
落地是个系统化的工程
AliceMind已经上线到阿里内部的NLP平台,可以提供给不同部门的业务使用。
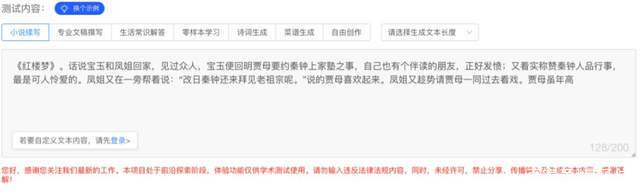
在官方网站上也提供了Demo,比如这个基于PLUG模型的语言生成模块。
输入红楼梦选段:
就能生成一段续写:
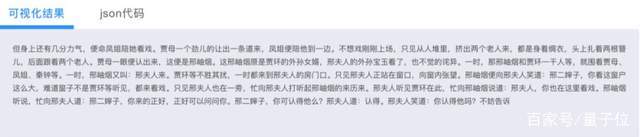
而像这样可供大家试玩的Demo还有几十个。
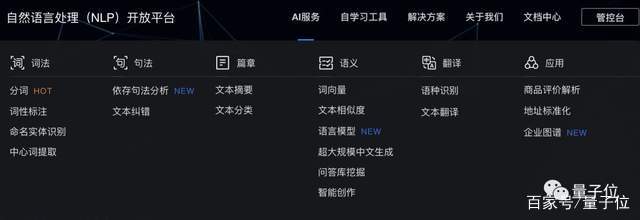
不过这些官网上的服务并非都是由AliceMind提供技术支持,很多都只是这一体系启发下的小模型。
那么这次开源的几大核心目前都在哪里打工呢?
应用最广泛的,就是电商。
尤其是阿里巴巴拥有跨境电商业务的部门,就是多语言模型VECO的直接受益者。
VECO是AliceMind体系中的8大模型之一,用于多语言理解和跨语种的文本嵌入、分类,掌握了100多种语言。
阿里内部基于AliceMind的翻译平台日调用量约10亿次,创造了数亿美元的国际跨境贸易和其他国际业务商业价值。
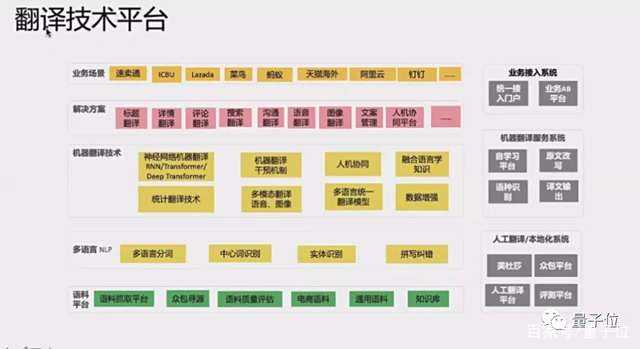
就像达摩院深度语言模型团队负责人黄松芳所说“语言模型落地是个系统化的工程”:
语言模型从训练、微调到蒸馏、压缩,到整个部署上线都在平台上面完成,上线之后跟业务方的系统连在一起,能够直接嵌到他们的业务逻辑、业务系统里面去。
我们更熟悉的淘宝拍照识图、天猫精灵智能音箱中也有AliceMind的贡献。
目前,AliceMind已经在阿里内部数十个核心业务落地,日均调用50亿次,活跃场景超过200个。
在阿里之外,医疗领域尤其是癌症治疗上,AliceMind同样出力不少。
作为一个具有自主学习能力的深度学习语言模型体系,AliceMind应用在搜索引擎上时会有一个重排机制。
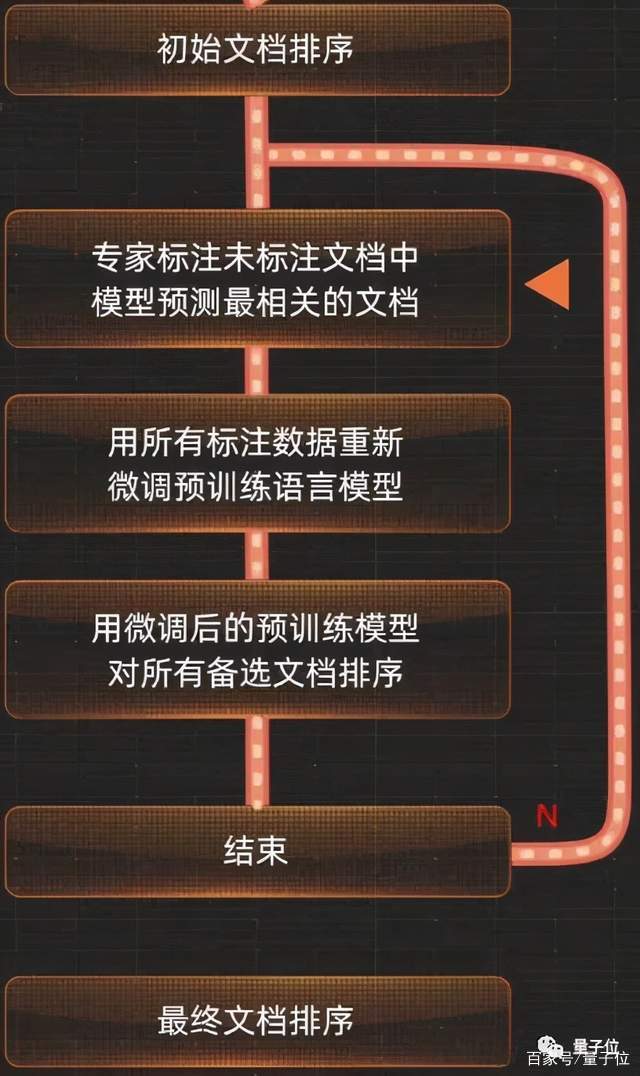
以具体某一类医学文献为目标,AliceMind在粗排先捞了一批相关文本后,还会再次结合文章类型、引用图谱等信息,进行不断地重排。
同时将抽取获得的信息与已知的结构化知识做融合,构建知识体系,最终得到最高质量的临床文献。
在最近16支世界知名团队参加的精准医学国际评测中,凭借这一精准医学搜索引擎,阿里团队在两项临床证据质量评估上均取得第一:

这样高精度的专业医学搜索引擎能够在疾病治疗时,为临床医生做提供高质量的临床决策辅助。
法律领域也有AliceMind的出没。
浙江省高级人民法院就与达摩院合作,实现了从立案到裁判文书生成的全流程智能化审判系统。
而在这一试点单位中,AI对法官工作量的分担使当庭宣判率提升至90%,结案时间也从平均40天缩短到50分钟。
现在,基于AliceMind的AliNLP平台日均累计调用量超过数万亿次,每天有超过每天有超过1000个业务方使用。
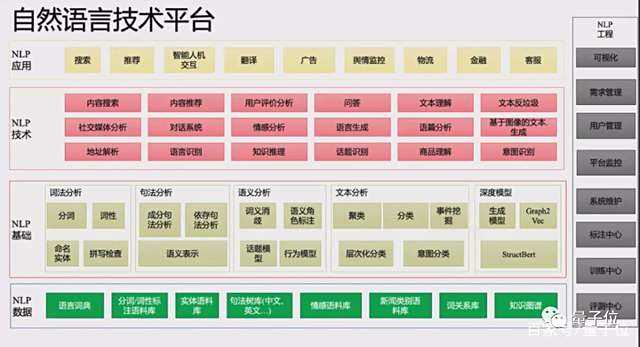
电商、教育、医疗、能源,通信、法律、内容搜索、城市大脑……越来越多的领域在AliceMind的加入下变得更加便利,更加智能。
开源之后要做什么?
现在,预训练语言模型目前在NLP领域以及整个学习界都非常热门,超大规模参数的模型已成为一种趋势。
对此,达摩院深度语言模型团队的负责人,也是AliceMind的总负责人黄松芳表示:
我们这边其实不会一味地追求大,而是非常强调它的落地。
一个语言模型从研究开发到投入实际应用,不是一家企业就能做到的。
还需要整个社区的开发者都参与,才有可能将学术论文中的公式算法用到大家的生活便利上。
达摩院希望通过开源,能降低业界研究和创新应用的门槛,使语言AI进入大工业时代。
下一步,AliceMind打算与语言学、神经科学等跨学科的单位加强合作,将语言AI扩展到更大的应用中。
开源地址:
https://github.com/alibaba/AliceMind
AliceMind官网:
https://nlp.aliyun.com/portal#/alice
相关论文:
通用预训练模型StructBERT:
https://arxiv.org/abs/1908.04577
多语言预训练模型VECO:
https://arxiv.org/abs/2010.16046
生成式预训练模型PALM:
https://arxiv.org/abs/2004.07159
多模态预训练模型E2E-VLP:
https://arxiv.org/abs/2106.01804
结构化预训练模型StructuralLM:
https://arxiv.org/abs/2105.11210
阅读理解模型:
https://ojs.aaai.org/index.php/AAAI/article/view/16584
融合知识的预训练模型Lattice-BERT:
https://arxiv.org/abs/2104.07204
参考链接:
[1]https://mp.weixin.qq.com/s/LTVVOOhezUN96MRLrqKCAQ
[2]https://mp.weixin.qq.com/s/PW0wZbts6ZpbKZSHyp8aVw
- 有道智能学习灯发布,通过“桌面学习分析引擎”实现全球最快指尖查词2022-04-08
- 科学证明:狗勾真的懂你有多累,听到声音0.25秒后就知道你是谁,对人比对狗更亲近2022-04-14
- 在M1芯片上跑原生Linux:编译速度比macOS还快40%2022-04-05
- 小学生们在B站讲算法,网友:我只会阿巴阿巴2022-03-28