
全球顶级语音技术比赛中获双料冠军,这家中国公司靠什么?
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
一场关键比赛,刚刚在全球顶级语音会议INTERSPEECH 2021上决出胜负。
腾讯、西工大、CMU等国内外机构是这场对决的主办方,两项比赛内容是语音行业的前沿研究,针对真实视频会议场景。
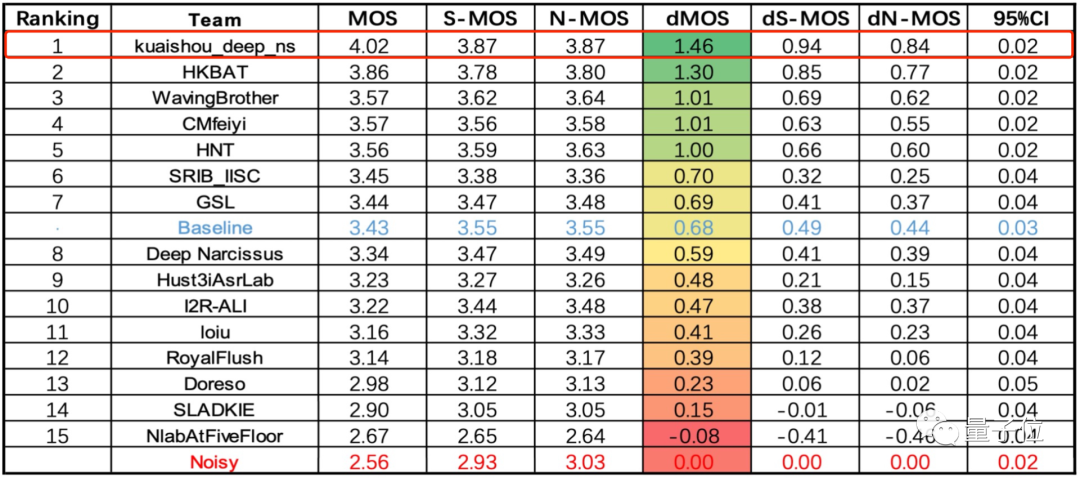
△单麦克风阵列多通道语音增强任务(dMOS越高越好)
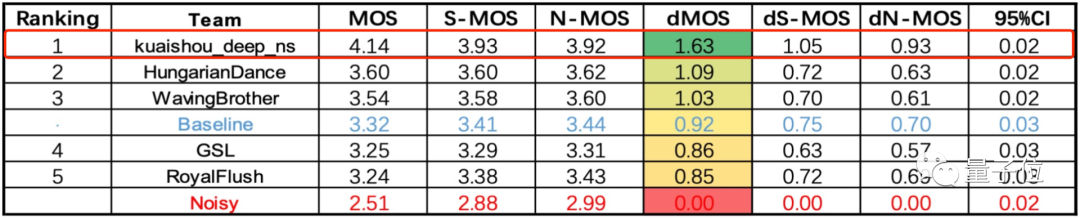
△多分布式麦克风阵列多通道语音增强任务(dMOS越高越好)
来自中国、美国、新加坡等16个国家和地区的实力队伍参赛,其中有像浙大、北航这样的顶尖高校,也有像中科院声学所这样的专业研究机构。
最终kuaishou_deep_ns团队包揽榜首,这支团队来自快手。
两项任务的第二名,分别是来自浙江大学和海康威视研究院联合团队,以及中国科学院大学、中科院声学所、北京航空航天大学、北京语言大学、西北工业大学联合团队。
快手团队在这场比赛中所使用的技术,已经以2篇论文的形式被INTERSPEECH 2021收录。
快手究竟在「远场多通道语音增强技术」上做出了什么突破?
经典分割模型U-Net,跨界语音增强领域
先来看看,这两项任务的考查目标「远场多通道语音增强技术」是什么。
语音增强技术,指在含噪语音中,对噪声信号进行抑制、降低,尽可能提取纯净的原始语音信号。
如果场景中只有一个麦克风(单通道),将难以解决在会议室、智能家居、智能座舱等场景下出现的远场问题。
远场,指说话人距离麦克风较远的场景。
主要存在三个难点:信噪比低、房间混响(在封闭、室内场景下,声波在传播时不断被墙壁反射、吸收和衰减)、多人说话场景
因此,通常采用多通道(多个麦克风组成的阵列)技术,来获取更多不同方向信号的幅度和相位信息,进一步解决远场问题,就是这场挑战赛的目标。
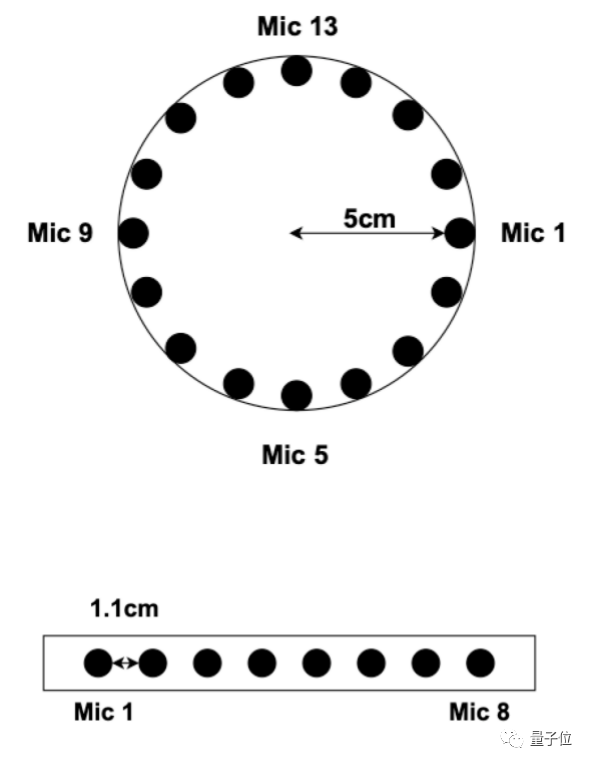
△圆阵和线阵的采集方案
多通道包括单个、多个分布式麦克风阵列两种类型,因此这场挑战赛也由两项任务组成,分别考查这两种多通道类型的远场语音增强技术。
传统基于信号的多通道算法,往往噪声抑制能力有限。这次的比赛中,快手团队决定从一个新角度出发解决远场问题:将深度学习技术和多通道算法进行融合。
经过筛选后,团队最终敲定了U-Net模型架构,这是一个图像分割领域的经典模型,在医疗图像和遥感领域的应用效果非常好。
U-Net模型以其结构左右完全对称、非常像“U”而得名,与FCN相似,同样为encoder-decoder架构,最初被用于图像压缩和图像去噪中。
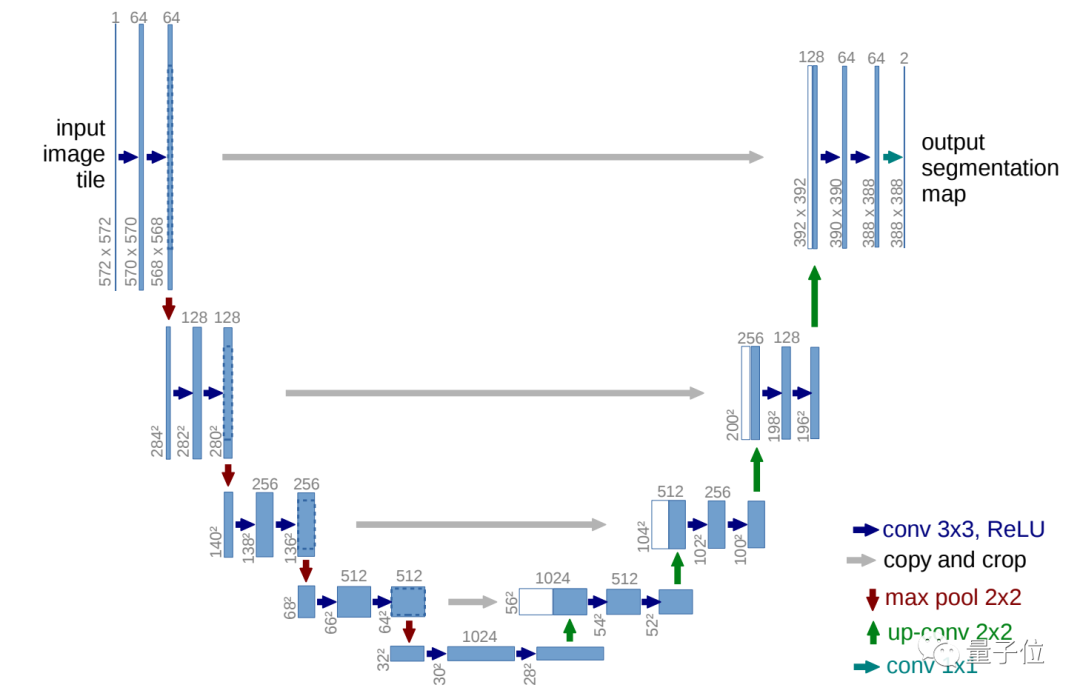
由于下采样和上采样均进行了4次,同时相比于FCN多了skip-connection(跳层连接)结构,因此U-Net能很好地提取高级语义信息和低级特征。
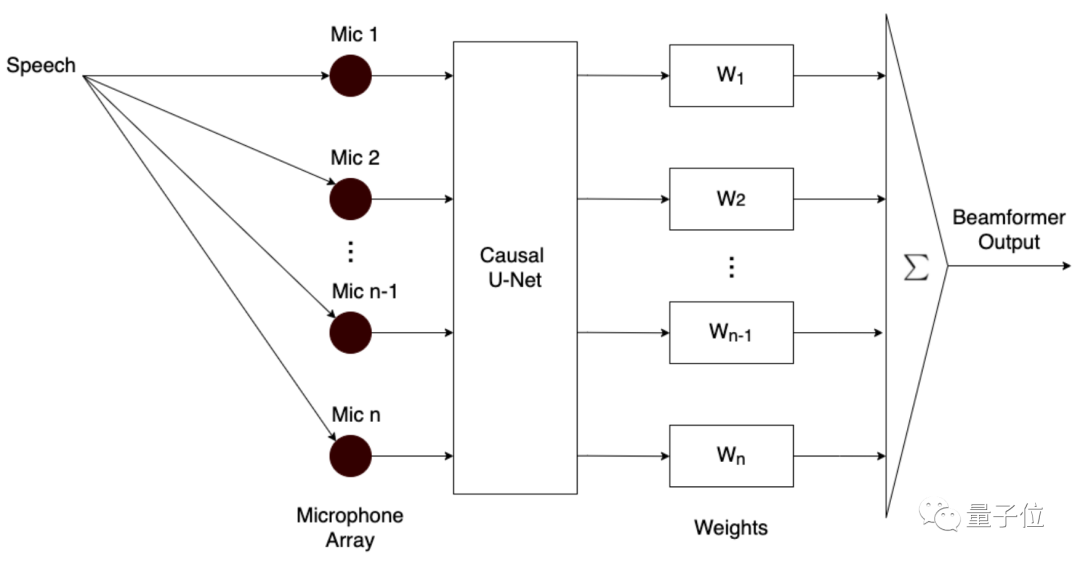
但团队却将U-Net用在了语音增强领域中,基于因果U-Net提出了一种多输入多输出算法模型。
因果U-Net的卷积结构采用了因果卷积(causal convolutions),目的是考虑实时问题(语音数据处理需要考虑实时性)。
事实上,将深度学习技术用于多通道模型,仍属于前沿研究,相关论文非常少。这也成为了团队设计模型时的一大难题。
经过反复测试验证后,团队发现,如果将模型的输出和经典的波束形成相结合,就能获得1+1>2的效果。
同时,在整体设计的基础上,串联一个后处理滤波器,对基于深度学习模型生成的语音信号进行二次降噪,让语音音质更加清晰。
事实证明,这一“跨界”模型的效果确实不错,原本广泛用于图像分割领域的经典模型,现在在语音增强领域也能取得不错的效果。
最终,快手团队研发的多输入多输出模型支持8通道语音增强技术,同时具有可扩展性(能扩展不同的通道数量)。
不过,模型创新设计还只是比赛中的一环。
用数据还原真实场景,让听觉“无障碍”成为可能
事实上,在语音增强比赛中,数据合成又成为了另一挑战。
举办方只会给出纯净的单人语音和噪声数据,但在最终的场景考核中,所有语音信号却都来自真实场景。
也就是说,在最终比赛时,模型会遇到各种远场情况、不同房间尺寸、不同麦克风放置地点和各种噪声强度等不同类型的数据,但训练数据却完全要靠团队自行设计。
这就需要参赛者合理考虑各类数据的占比,尽可能使模拟出来的数据更贴近真实情况。

不仅如此,由于此前深度学习在语音增强方向的研究大多基于单通道模型,因此团队自行设计的数据,还得进一步考虑多通道的情况。
也就是说,需要对同一场景下、不同麦克风(通道)收到的信号数据进行模拟,用于多通道模型的训练。
尽可能还原真实场景的合成数据,加上自己研发的基于深度学习的多通道模型,让快手团队最终在这场语音增强比赛上获得两项任务的第一。
但这场语音增强比赛,背后的意义不仅在于角逐出模型的第一。
虽然「远场多通道语音增强技术」确实尚处于前沿研究阶段,但它未来的应用场景也已经得以预见。
其一,多人会议,而且是异地两部门之间的那种多人视频会议。

常见的线上视频会议中,基本上每个人都需要佩戴一副耳机,才能实现多人视频会议,这也是目前大多数视频会议APP所能实现的功能。
但未来可能只需要一块屏幕,加上多通道语音技术就能在两个异地部门、或是两群人之间实现实时视频沟通。
即使坐在屏幕最远端的人,也能听见视频对面每个人的声音,就像在一个办公室沟通那样顺利。
其二,让XR技术的实现,在语音处理领域成为可能。

5G+AI的组合,让XR中的图像实时传输技术成为现实,但语音实时交互却仍然存在不少困难,其中远场是不可避开的一个技术难点。
如果远场多通道语音增强技术进一步得到发展,或许将来XR也能真正实现语音上“声临其境”的交互效果。
想象一下,如果将来XR能应用到直播中(例如户外直播),或许我们也能实时进入到直播环境中,足不出户感受世界的美景。
作为音视频行业的引领者,快手已经在探索这样的多通道语音增强技术落地场景。
将来,像多人会议、XR、直播场景互动这些设想中的“无障碍”听觉技术,说不定哪天就会成为产品,落入寻常百姓家。
夺冠背后,快手的技术基因
在这次的语音增强比赛上获得第一,背后是一整个快手的音频处理算法团队在做技术支撑。
参赛团队中,也有不少成员来自清北、西工大等985高校。
据团队成员表示,实现这个模型,团队用了将近一个月的时间,期间在模型设计和数据处理上遇到了不少难关,但最终团队都将它们逐一攻破。
但相比于一味追求降噪效果,团队成员的模型设计也考虑了实时通信的需求。
毕竟远场通信的一大特点就是实时性,如果模型设计得太大,忽略了可实现性的话,也会失去落地应用的价值。
这也是快手“技术无差别”的基因之一,让技术更贴近实际生活,尽可能造福每一圈层的人群。

事实上,除了语音增强技术以外,快手在回声消除技术上也深耕已久。
同样是在INTERSPEECH 2021的AEC Challenge(Acoustic Echo Cancellation Challenge)回声消除比赛上,快手就以4.77的分数取得了双讲回声消除的单项世界冠军,领先于中科院、字节跳动、阿里巴巴等诸多参赛团队。
而在技术落地方面,同样是在今年5月,快手还上线了基于深度学习的实时变声直播,成为行业中首个上线相关技术的公司。
未来,快手还将继续在音视频行业中,凭借技术实力,带给我们更多的惊喜。
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
点这里👇关注我,记得标星哦~

量子位
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07





