视频台词现在不用背也不用配,连对口型都免了
图像质量比其他方法更高
月石一 发自 凹非寺
量子位 报道 | 公众号 QbitAI
现在,给视频人物“喂”一段音频,他就能自己对口型了,就像这样:
原声其实是出自这里:
这是一种利用音频生成视频人物口型的新方法,出自慕尼黑工业大学Wojciech Zielonka的硕士论文。
用这种新方法对口型,只需2-3分钟就能够训练目标角色,生成的视频保留了目标角色的说话风格;
并且不受语音来源、人脸模型和表情的限制。
新方法与Neural Voice Puppetry、Wav2Lip、Wav2Lip GAN的生成效果,对比起来是这样的:

在保持较低唇部误差的同时,生成图像质量高于其他方法。
原理简介
具体来说,作者提出了一个新的框架,它由音频特征提取、投影网络、变形网络、颜色网络、组成网络几个部分组成。
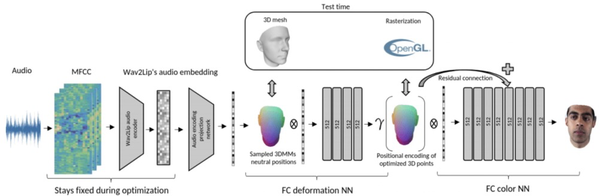
首先,将输入音频转换为MFCC(梅尔频率倒谱系数),并进行特征提取。
利用投影网络进行近似转换,将提取的特征嵌入到不同的低维空间。
为了顺利生成视频,研究人员还引入了一维卷积网络和一个衰减模块,以保持时间上的连贯性。
在变形网络中,作者使用了三维可变形人脸模型(3DMM),这是一种基于一组人脸形状和纹理的统计模型,将人脸表示为固定的点数。
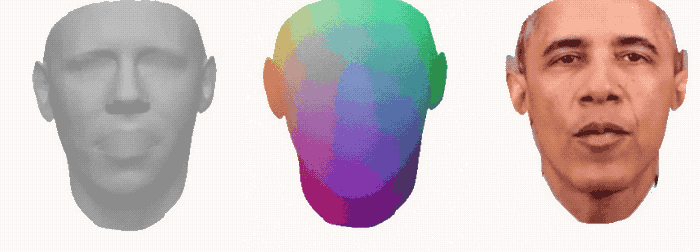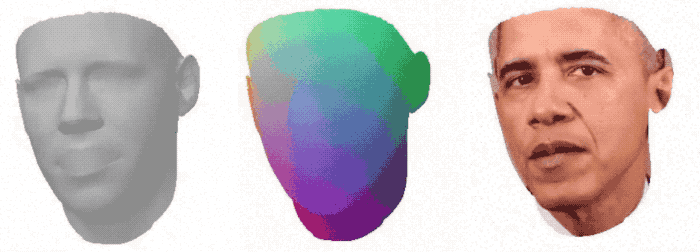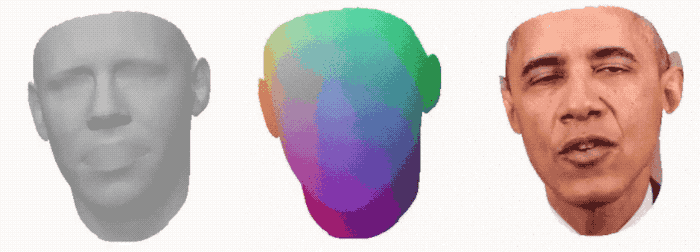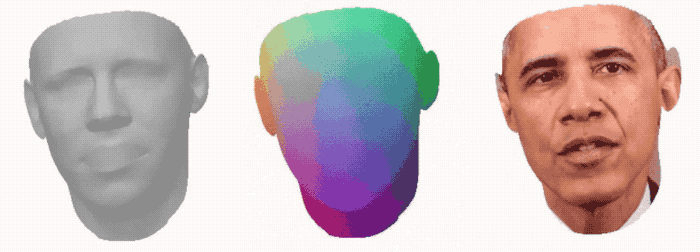
将3DMM的网格输入变形网络,该网络能通过音频信号产生优化的3D形状。
再将其栅格化传递给色彩网络,每个三维点经过位置编码,并与音频嵌入相关联,最终通过色彩网络输出图像。
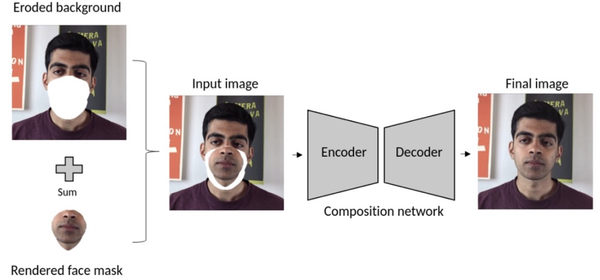
最后,用2D膨胀卷积网络建立的组成网络,将渲染的人脸被无缝地嵌入到背景中。
可以看到从3D形状到最终合成输出的效果:

这项研究采用了最小绝对值偏差(L1)和感知损失(VGG)这两个损失函数的组合。
先利用L1损失网络找到粗略图像,然后在训练过程中,通过VGG损失进行完善并学习细节。
性能如何?
研究人员使用数据集对模型进行了测试,数据集中共有6个人物。
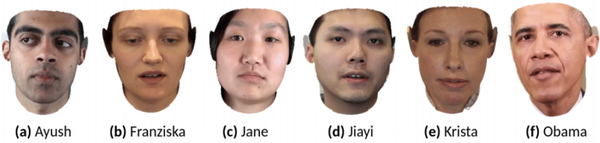
其中,模型用于Krista和Obama时效果更好,生成图像与ground truth最为接近。

而Ayush的误差较高,作者表示,这可能是受到训练视频质量的影响。
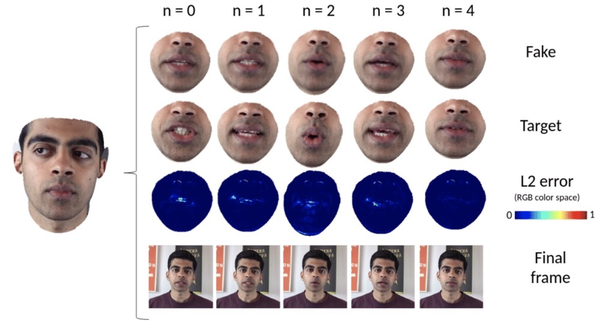
作者还对色彩网络的性能进行了评估,结果显示,即使3D形状在随机帧之间没有很大变化,色彩网络也能作出正确的预测。

论文中还给出了与其他方法的定量对比情况,整个数据集的图像质量误差如下:
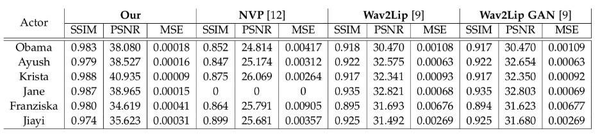
在图像质量的3个指标中,新方法都优于其他方法。
不过新方法也不是一直可靠,比如在合成时,也可能会产生位移误差,出现双下巴等。
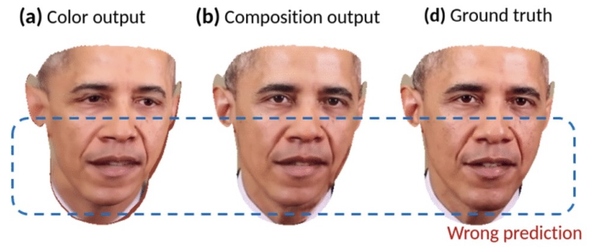
此外,它还存在一定的局限性。
由于3DMM并没有明确地对牙齿建模,目前的方法是将两个嘴唇封闭起来。因此,顶点的数量并没有改变,特征基数仍然成立。
拥有详细的牙齿几何形状,可以更好地捕捉说话时的面部运动,当然这在很大程度上取决于人们的说话风格。
此外,一个更大的局限是,在场景或演员变化时,就需要重新训练模型,并且只支持英语音频。
网友热议
作者把效果视频发在了Reddit上,引起了网友们的热议。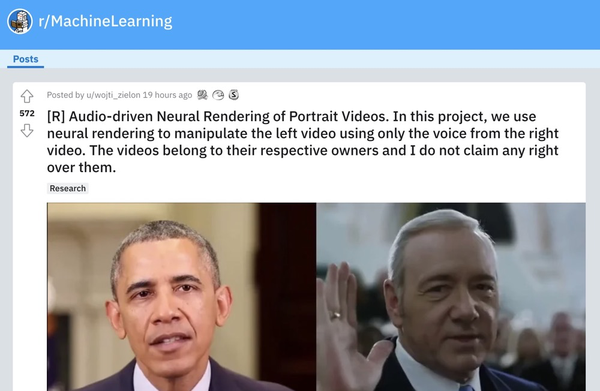
不少网友发现,视频人物的唇部动作,似乎效果不佳。

除了“美国”之外,他的口型看起来对不上。

更多的网友对于这项技术的应用,提出了质疑。
这与在奥巴马静音的视频上播放音频有何不同?

就像这位网友所说,类似这样的人脸生成技术,很多都被用于造假,因此一直存在着伦理争议。
网友们也为此感到担忧:
有时我会想到这些技术是如何被滥用的,这让我对未来感到有点难过。
我们需要虚假视频检测器,不知道这场战斗还要走多远。
拥有权利的同时,也被赋予了重大的责任!

如果这类应用盛行起来,人们也许不会相信视频了。

不过也有网友提到:
好在,就目前来说,检测比生成要要容易得多,效果也更好。

对于这项研究,作者表示,
它具有商业前景。比如,在未来,演员可以出售自己的(视频)化身。
仅需语音操纵,就能够制作电影或游戏,还可以使用根据文本生成的语音。
你希望这样的技术用在电影和游戏里吗?
参考链接:
[1]https://www.dropbox.com/s/o0hk73j1dmelcny/ThesisTUM.pdf?dl=0
[2]https://zielon.github.io/face-neural-rendering/
[3]https://www.reddit.com/r/MachineLearning/comments/ntiv0z/r_audiodriven_neural_rendering_of_portrait_videos/
- 魔改宜家灯泡当主机,玩转《毁灭战士》无压力!网友:远超我家第一台电脑2021-06-17
- 苹果为了不让AirTag被用来跟踪,将推出一个安卓应用2021-06-17
- 中国程序员开发的远程桌面火了!Mac可用,只有9MB,支持自建中继器2021-06-17
- 亚马逊员工流动率150%,每8个月相当于“大换血”,网友:贝佐斯不知足2021-06-16