
苹果让Transformer抛弃注意力机制,一切只为效率,项目已开源丨华人一作
“Attention Is Not All You Need”,苹果对Transformer如是说
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
2017年,一句Attention Is All You Need引爆了整个NLP圈,甚至在近些年还有踢馆计算机视觉领域的趋势。
所有的这一切,都来源于这篇论文中的Transformer模型所采用的注意力(Attention)机制。
但现在,你能想象一个不再需要注意力的Transformer吗?
 △“Attention Is All You Need作者:拳头硬了”
△“Attention Is All You Need作者:拳头硬了”
今天就来一起看看这项来自苹果的研究:无注意力Transformer。

为什么要“抛弃”注意力?
自注意力机制的应用,使得Transformer突破了RNN不能并行计算的限制,并大大提高了捕捉长期依赖关系的能力。
但与此同时,这种机制也意味着需要额外执行具有时间和空间复杂性的注意力操作,这就为操作带来了二次成本。
因此在大规模的语义环境里,Transformer的效率就显得不高。
而这种无注意力Transformer(AFT)则消除了点积自注意力(dot-product self attention)的需要,展现出了出色的效率。
 △对比现有的Transformer变体,AFT的时间复杂度是最低的
△对比现有的Transformer变体,AFT的时间复杂度是最低的
算法设计
这项研究的全名为Attention Free Transformer,它类似于标准的点积注意力算法,同样由查询向量Q,被查向量K,内容向量V相互作用而成。
但不同的是,AFT中的K和V首先与一组学习得到的位置偏差(position bias)结合,然后再进行同位元素对应相乘(element-wise multiplication)。

这一新操作的内存复杂度、文本规模、特征维度都是线性的,这就使输入大小和模型尺寸互相兼容。
同时,研究者还在AFT的基础上提出了几种模型变体。
比如,将一张在ImagenetNet验证集上进行预训练的Vit图(由12层组成,每层有6个头,空间大小为14×14)可视化后,最终产生了一组尺寸为12×6×27×27的注意力图。
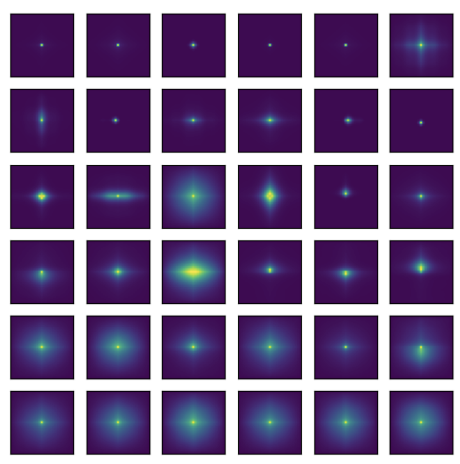
观察图可以看到,标准Transformer表现出了比较强烈的局部模式,这就激发了AFT的一种变体:AFT-local。
AFT-local在保持全局连通性的同时利用了局部性概念,将学习到的位置偏差固定在一个局部区域中。
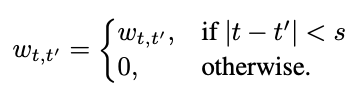
在将空间权值共享(卷积)的理念也纳入考虑后,研究者还得到了另一种变体:AFT-conv。
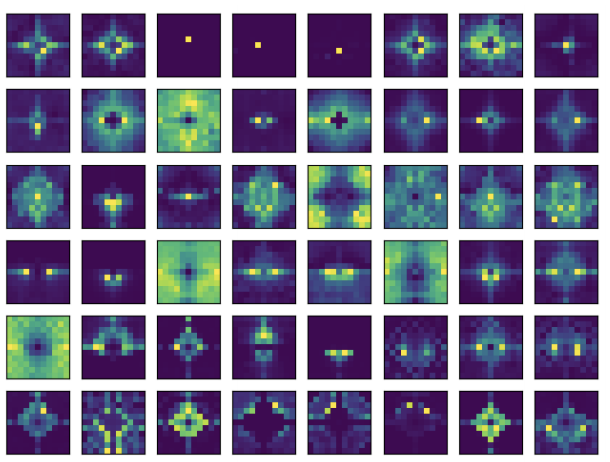
在将K的维度与头(head)个数联系起来后,就能使AFT-conv可依赖于深度可分离卷积、全局池化和元素操作来实现。
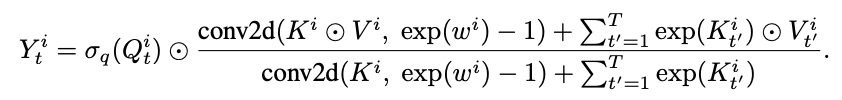
表现如何?
在图像自回归建模(Image Autoregressive Modeling)上,每个字符的比特数(bpc)越低越好。在这一点上,AFT做到了SOTA。
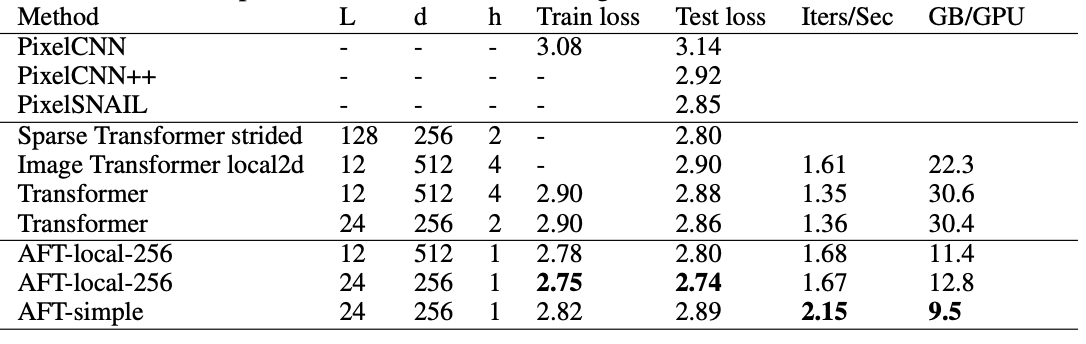
而对于老本行语言建模(Language Modeling)问题,研究者则基于Enwik8进行字符级语言建模。
而结果是,AFT仅仅消耗了1/3的内存,就提供了提供了44%的速度提升,且在bpc上与完整的Transformer的距离只相差0.024,在参数、速度、内存和性能方面均取得了最佳平衡。
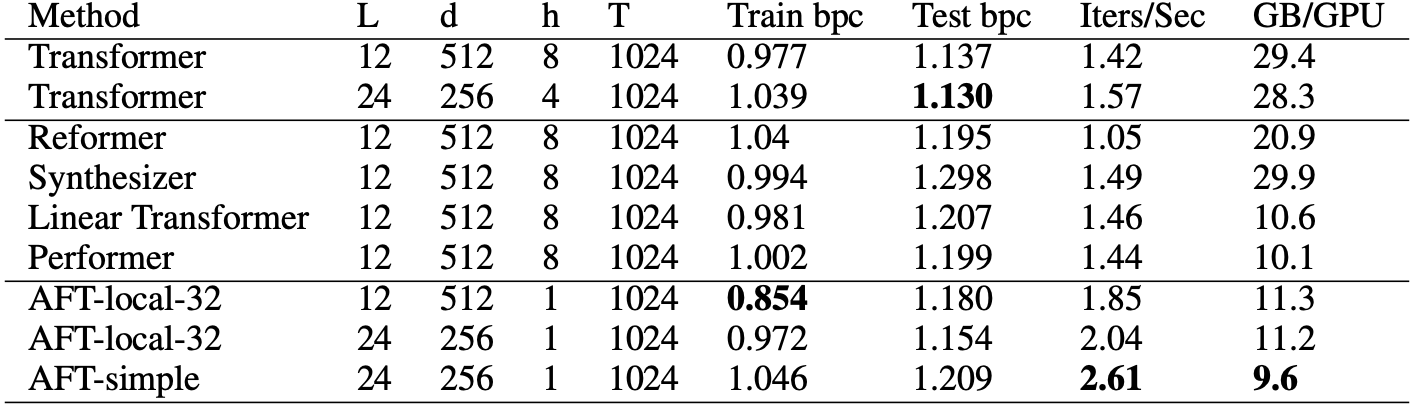
研究者也将AFT测试了图像分类( Image Classification)的任务。

最终AFT的变体AFT-full在更好的内存占用和相似的速度下,取得了与基线Transformer DeiT相当的性能。
而在参数数量相似或更少的情况下,AFT-conv的准确率更高。
与Lambda网络相比,所有的AFT变体都达到了相当或更好的精度,且速度相当,内存占用更小。
“所以我们到底需要什么?”
对于这一丢弃了注意力机制的Transformer,有人表示深度学习研究果然就是个圈,指不定过几年KNN也能再次伟大。
也有人对这种“Not Need”之风发出灵魂拷问:所以你们到底需要什么?

△“不需要卷积,不需要注意力……啥你都不需要”
最终,机器学习的研究者们决定用魔法打败魔法:

一作为华人学者
这篇论文的一作翟双飞曾在IBM Research实习过9个月,2017年6月加入苹果,并在其机器学习研究部门任职至今。
他本科就读于中国科学技术大学的电子工程与信息科学学院,并于2017年在宾汉姆顿大学获得了计算机科学博士学位。
下载地址:
https://github.com/rish-16/aft-pytorch
论文地址:
https://arxiv.org/abs/2105.14103
参考链接:
https://www.reddit.com/r/MachineLearning/comments/npmq5j/r_an_attention_free_transformer/
- 有道智能学习灯发布,通过“桌面学习分析引擎”实现全球最快指尖查词2022-04-08
- 科学证明:狗勾真的懂你有多累,听到声音0.25秒后就知道你是谁,对人比对狗更亲近2022-04-14
- 在M1芯片上跑原生Linux:编译速度比macOS还快40%2022-04-05
- 小学生们在B站讲算法,网友:我只会阿巴阿巴2022-03-28





