
不用GPU,稀疏化也能加速你的YOLOv3深度学习模型
水木番 发自 凹非寺
量子位 报道 | 公众号 QbitAI
你还在为神经网络模型里的冗余信息烦恼吗?
或者手上只有CPU,对一些只能用昂贵的GPU建立的深度学习模型“望眼欲穿”吗?
最近,创业公司Neural Magic带来了一种名叫新的稀疏化方法,可以帮你解决烦恼,让你的深度学习模型效率“一节更比七节强”!
Neural Magic是专门研究深度学习的稀疏方法的公司,这次他们发布了教程:用recipe稀疏化YOLOv3。
听起来有点意思啊,让我们来看看是怎么实现的~
稀疏化的YOLOv3
稀疏化的YOLOv3使用剪枝(prune)和量化(quantize)等算法,可以删除神经网络中的冗余信息。
这种稀疏化方法的好处可不少。
它的推断速度更快,文件更小。
但是因为过程太复杂,涉及的超参数又太多,很多人都不太关心这种方法。
Neural Magic的ML团队针对必要的超参数和指令,创建了可以自主编码的recipe。
各种不同条件下的recipe构成了一种可以满足客户各类需求的框架。
这样就可以建立高度精确的pruned或pruned quantized的YOLOv3模型,从而简化流程。
那这种稀疏化方法的灵感来源是什么呢?
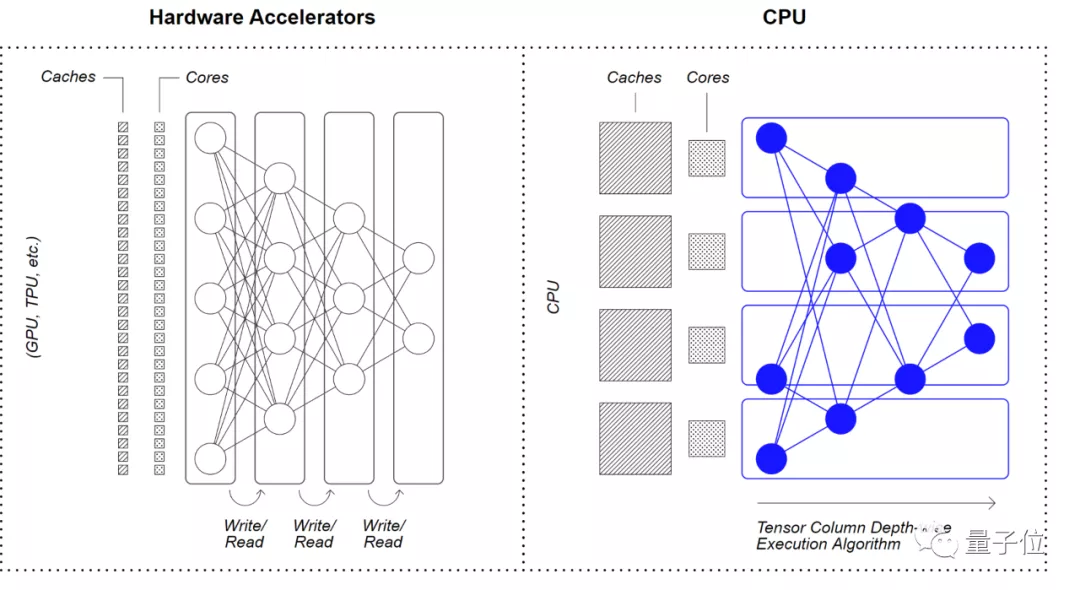
其实,Neural Magic 的 Deep Sparse(深度稀疏)架构的主要灵感,是在产品硬件上模仿大脑的计算方式。
它通过利用 CPU 的大型快速缓存和大型内存,将神经网络稀疏性与通信局部性相结合,实现效率提升。
教程概况
本教程目录主要包括三大模块:
- 创建一个预训练的模型
- 应用Recipe
- 导出推理
教程的这些recipe可以帮助用户在Ultralytics强大的训练平台上,使用稀疏深度学习的recipe驱动的方法插入数据。
教程中列出的示例均在VOC数据集上执行,所有结果也可通过“权重和偏差”项目公开获得(地址见参考链接4)。
调试结果展示
研究团队给出了稀疏YOLOv3目标检测模型在Deep Sparse引擎和PyTorch上的运行情况。
这段视频以波士顿著名地标为特色,在Neural Magic的诞生地——MIT的校园取景。
同样的条件下,在Deep Sparse引擎上比PyTorch上效率会更高。
遇到的常见问题
如果用户的硬件不支持量化网络来推理加速,或者对完全恢复的要求非常高,官方建议使用pruned或pruned short 的recipe。
如果用户的硬件可以支持量化网络,如CPU 上的 VNNI 指令集,官方建议使用pruned quantized或pruned quantized short的recipe。
所以使用哪一种recipe,取决于用户愿意花多长时间训练数据,以及对完全恢复的要求。
具体要比较这几种recipe的话,可以参考下表。
网友:这个框架会比传统的机器学习框架pytorch好吗?
既然给出了和pytorch的比较视频,就有网友发问了:
Neural Magic也使用python吗?为什么一个比另一个快10倍以上?我不相信像pytorch这样传统的机器学习框架不会得到优化。两种模型的实现是否相同?

公司官方人员也下场解释了:
我们拥有专利技术,可以通过减少计算和内存移动来使稀疏网络在CPU上更高效的运行。
虽然传统的ML框架也能很好地实现简单而高效的训练过程。
但是,多加入一些优化的推理,可以实现更多的性能,尤其是在CPU上更明显。

看来,有了以上强大的YOLOv3 模型工具和教程,用户就可以在CPU上,以最小化的占用空间和GPU的速度来运行深度学习模型。
这样有用的教程,你还在等什么?
希望教程能对大家有所帮助,欢迎在评论区分享交流训练模型经验~
最后介绍一下Neural Magic,有兴趣的朋友可以去了解一下。
Neural Magic是一家什么样的公司?
Neural Magic成立在马萨诸塞州的剑桥。
创始人Nir Shavit和Alexander Matveev在MIT绘制大脑中的神经连接图时,一直觉得GPU有许多限制。
因此他们停下来问自己两个简单的问题:
为什么深度学习需要GPU等专用硬件?
有什么更好的方法吗?
毕竟,人脑可以通过广泛使用稀疏性来减少神经网络,而不是添加FLOPS来匹配神经网络,从而满足神经网络的计算需求。
基于这种观察和多年的多核计算经验,他们采用了稀疏和量化深度学习网络的技术,并使其能够以GPU的速度或更高的速度在商用CPU上运行。
这样,数据科学家在模型设计和输入大小上就不需要再做妥协,也没必要用稀缺且昂贵的GPU资源。

Brian Stevens
Neural Magic的CEO,Red Hat和Google Cloud的前CTO。

Nir Shavit
Neural Magic联合创始人。
麻省理工学院教授,他目前的研究涉及为多处理器设计可伸缩软件的技术,尤其是多核计算机的并发数据结构。

Alexander Matveev
Neural Magic首席技术官兼联合创始人。
麻省理工学院前研究科学家,专门研究AI多核算法和系统。
参考链接:
[1]https://github.com/neuralmagic/sparseml/blob/main/integrations/ultralytics-yolov3/t2.utorials/sparsifying_yolov3_using_recipes.md
[2]https://neuralmagic.com/blog/sparsifying-yolov3-using-recipes-tutorial/
[3]https://arxiv.org/pdf/1804.02767.pdf
[4]https://wandb.ai/neuralmagic/yolov3-spp-lrelu-voc
- 3行代码就能可视化Transformer的奥义 | 开源2021-06-20
- “接着奏乐接着舞”,大脑也是这么想的2021-06-20
- 新型内存攻击,专治制程提高的芯片2021-06-08
- 台大喊你来上课,深度学习优化,免费的哟2021-05-31










