清华唐杰团队造了个“中文AI设计师”,效果比Dall·E好,可在线试玩
代码即将放出
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
要说2021年OpenAI最热最有创意的产品,那么非Dall·E莫属了,这是一个可以从“AI设计师”,只要给它一段文字,就能按要求生成图像。但可惜的是Dall·E并不支持中文。
现在好了,最近清华大学唐杰团队打造了一个“中文版Dall·E”——CogView,它可以将中文文字转图像。
CogView可以生成现实中真实存在场景,如“一条小溪在山涧流淌”:

也可以制造不存在的虚拟事物,如“猫猪”:

有时候还有点黑色幽默,如“一个心酸的博士生”:

CogView现在还提供了试玩网页,你可以在那里输入任何文字去转成图形,不像OpenAI的Dall·E只提供几个关键词修改选项。
能指定画风,能设计服装
CogView的能力可不仅仅是从文字输入图像,它还能处理不同微调策略的下游任务,例如风格学习、超分辨率、文本图像排名和时装设计。
在使用CogView的时候,可以加入不同风格限定,从而生成不同的绘画效果。在微调期间,图像对应的文本也是“XX风格的图像”。

CogView设计的服装也像模像样,看起来就像电商展示页,没有虚假痕迹。

原理
CogView是一个带有VQ-VAE分词器40亿参数的Transfomer,它的总体结构如下:
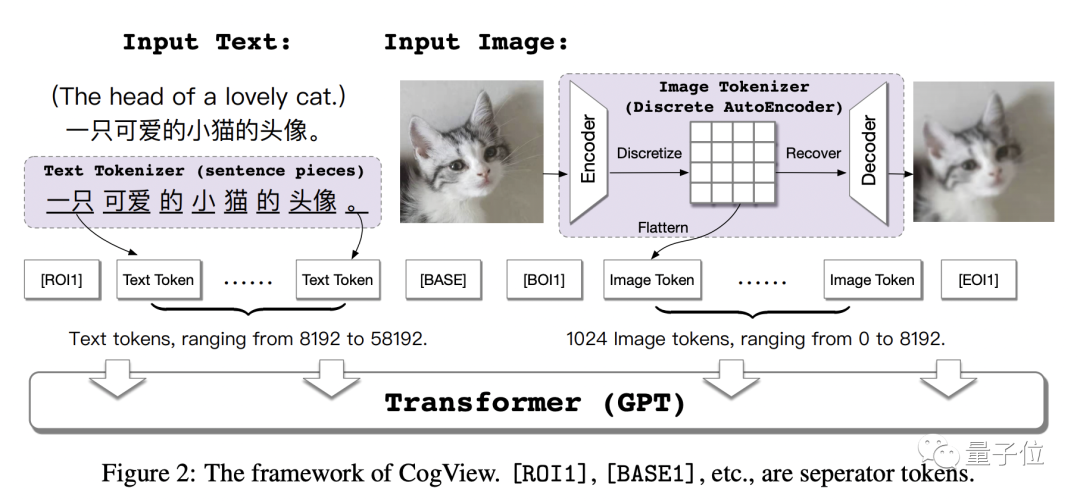
CogView使用GPT模型处理离散字典上的token序列。然后将学习过程分为两个阶段:编码器和解码器学习最小化重建损失,单个GPT通过串联文本优化两个负对数似然 (NLL) 损失。
结果是,第一阶段退化为纯离散自动编码器,作为图像tokenizer将图像转换为标记序列;第二阶段的GPT承担了大部分建模任务。
图像tokenizer的训练非常重要,方法有最近邻映射、Gumbel采样、softmax逼近三种,Dall·E使用的是第三种,而对于CogView来说三者差别不大。
CogView的主干是一个单向Transformer,共有48层、40个注意力头、40亿参数,隐藏层的大小为2560。
在训练中,作者发现CogView有两种不稳定性:溢出(以NaN损失为特征)和下溢(以发散损失为特征),然后他们提出了用PB-Relax、Sandwich-LN来解决它们。
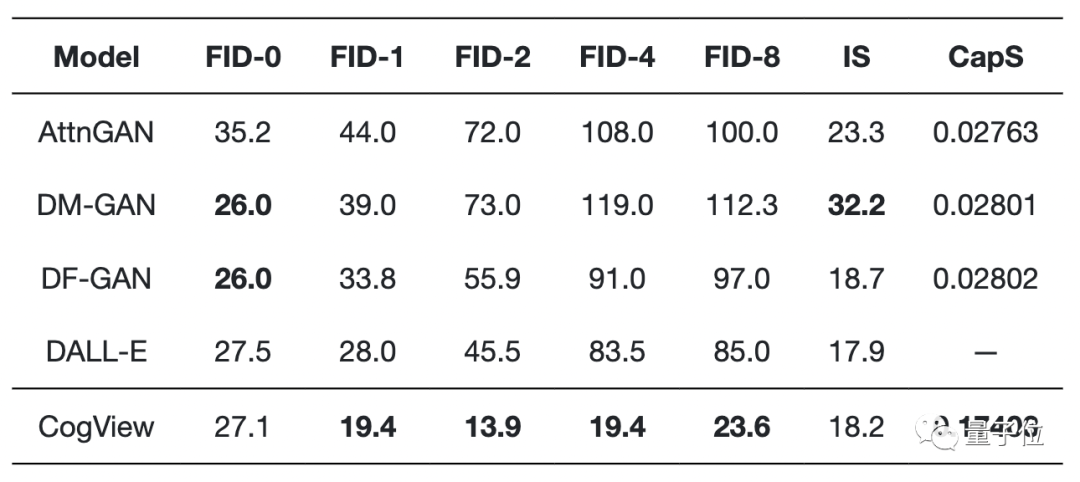
最后,CogView在MS COCO实现了最低的FID,其性能优于以前基于GAN的模型和以及类似的Dall·E。
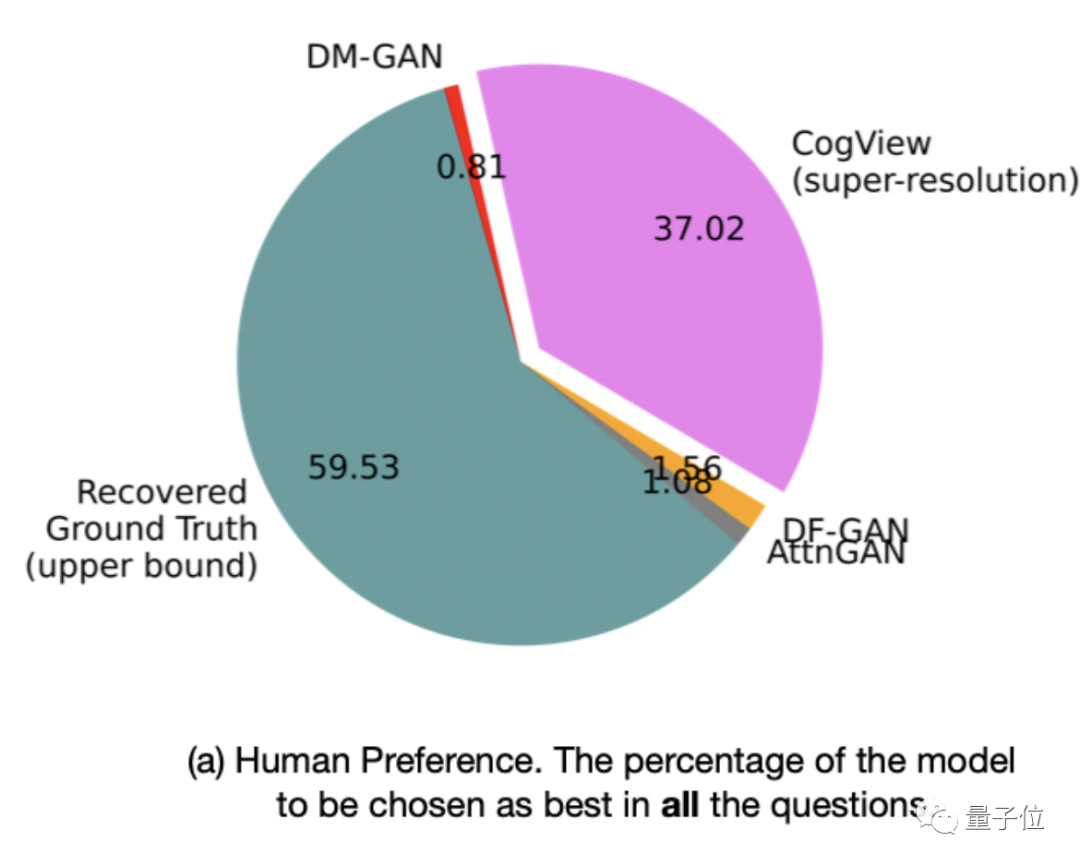
而在人工评估的测试中,CogView被选为最好的概率为37.02%,远远超过其他基于GAN的模型,已经可以与Ground Truth(59.53%)竞争。
另外作者已经放出了GitHub项目页,不过目前还没有代码,感兴趣的朋友可以关注一下等代码放出。
论文地址:
https://arxiv.org/abs/2105.13290
试用Demo:
https://lab.aminer.cn/cogview/index.html
GitHub页:
https://github.com/THUDM/CogView
- 脑机接口走向现实,11张PPT看懂中国脑机接口产业现状|量子位智库2021-08-10
- 张朝阳开课手推E=mc²,李永乐现场狂做笔记2022-03-11
- 阿里数学竞赛可以报名了!奖金增加到400万元,题目面向大众公开征集2022-03-14
- 英伟达遭黑客最后通牒:今天必须开源GPU驱动,否则公布1TB机密数据2022-03-05