
百度万亿级图检索引擎发布!四大预训练模型开源,还“发糖”15亿元
百度的“520”礼物
金磊 梦晨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
又一年520,又一年情……
Stop!不是这种打开方式。
瞧~同样是为了“过节”,却吸引了五湖四海的开发者聚集在此。

这就是已经“约定俗成”的深度学习开发者盛会——WAVE SUMMIT 2021。
而百度飞桨,作为国产最大深度学习平台,同样也在520这样的日子,给开发者们带来了不少“糖”吃:
- 发布全新飞桨开源框架2.1版本
- 发布全新大规模图检索引擎
- 开源文心ERNIE四大预训练模型
- 全新发布推理部署导航图
- ……
除此之外,还有15亿元资金,其中10亿要“发”给10万家企业和百万产业AI人才。
与以往不同,此次峰会揭示了一种全新定调——大融合、大创新。
百度首席技术官王海峰表示:
从技术的角度,多技术融合创新,知识与深度学习相结合,突破了知识增强的深度语义理解,在参数规模相同的情况下效果大幅提升,可解释性更强。
从平台的角度,深度学习平台与芯片软硬一体融合创新,面向不同硬件配置的各种生产环境,满足不同算力、功耗、时延等的多样化需求,取得AI应用的最佳效果。
从产业的角度,人工智能技术越来越深入与产业融合,以产业需求为牵引,持续打磨 AI 技术及平台能力,与应用场景融合创新发展。

△百度首席技术官,王海峰
此外,降低AI门槛,也是此次峰会的另一重点,是加快多样性和产业进程的核心。
而之于融合创新和降低AI门槛,如何把AI价值带入到产业中,实现高效率高质量的大生产,百度集团副总裁吴甜认为:
AI工业大生产首先在企业生产活动中逐阶段实现,进一步发展,将会从企业内部的多人多任务分工协同,走向全社会的AI大生产大协同。

△百度集团副总裁,吴甜
接下来,便来一文看尽WAVE SUMMIT 2021。
六大全新发布
飞桨开源框架2.1版本
作为国产最大的深度学习平台,在此次峰会中,再次迎来升级——2.1版本。
划重点!
四大功能着重优化:
- 集自动混合精度优化:以ResNet50和BERT为例,启动该功能后,训练速度可提升3倍。
- 动态图功能增强:新增inplace操作功能,显存占用降低17%;优化Python/C++交互开销,训练速度提升10%。
- 高层API:新增支持GPU预处理、混合精度和模型共享机制。
- 尤其是在自定义算子功能上的升级,让开发者自定义算子的学习、开发成本大幅降低,也大大提高了开发的灵活性。
由此,也就展开了此次2.1版本升级后,百度飞桨的一张全景图。

而在这张全景图中,除上述核心框架开发功能优化之外,百度飞桨此次的升级,还远不止于此。
大规模图检索引擎
此次百度飞桨2.1版本,在分布式训练方面的发布,便是大规模图检索引擎,核心亮点如下:
支持万亿边的分布式图存储和检索,支持线性扩展。
例如在与网易云音乐的合作过程中,“主播推荐”便用到了该功能。
支撑了十亿边图模型训练,有效地解决了冷启动问题,提高了主播推荐场景的有效播放率。
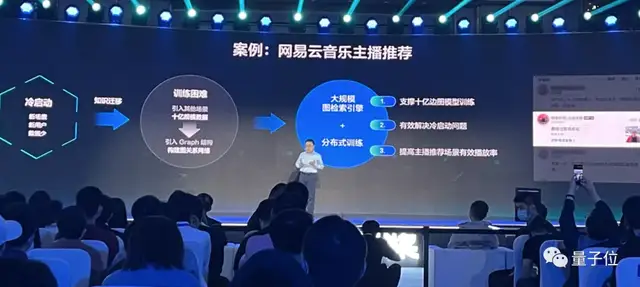
不难看出,大规模图检索引擎的发布,让百度飞桨具备更强的产业场景应用特性。
文心ERNIE四大预训练模型开源
框架层之后,便是模型套件层方面。
开源了文心ERNIE的四大预训练模型:
- ERNIE-Gram:提出显式的n-gram掩码语言模型,通过引入多粒度语言知识增强预训练模型效果,在5项典型中文文本任务中领先。
- ERNIE-Doc:针对篇章长文本建模不充分问题,提出回顾式建模技术和增强记忆模型机制,在13项长文本理解任务上取得领先效果。
- ERNIE-ViL:针对跨模态理解难题,基于知识增强思想,实现了融合场景知识的跨模态预训练,在5项跨模态理解任务上取得效果领先
- ERNIE-UNIMO:进一步增强不同模态间的知识融合,通过跨模态对比学习,同时提升跨模态语义理解与生成、文本理解与生成的效果,在13项跨模态和文本任务上实现领先。

而在复杂的语义理解需求下,这四大预训练模型可各自发挥它们的所长。
与此同时,还可以做到技术融合,达到“1+1>2”的创新效果。
不仅能理解语言,还可以理解图像,实现统一的跨模态语义理解。
飞桨推理部署工具链、导航图
除了开发、训练和套件之外,在推理部署工具链的各个节点上,也有所升级:
- PaddleSlim:进一步优化剪枝压缩技术,新增非结构化稀疏工具;率先支持OFA压缩模式,保障压缩后的精度。
- Paddle Lite:发布了面向移动开发者的“开箱即用”工具集 LiteKit,大大降低端侧AI开发者的开发成本。
- Paddle Serving:新增全异步设计的Pipeline模式,更好地支持现实业务中模型组合使用的问题。
- Paddle.js:新增支持多种 Backend和主流图像分割及分类模型,在高兼容性的同时也兼顾了高性能。
飞桨除了在已有推理部署工具链上做了升级外,还提供了一张推理部署导航图。
据了解,目前已经涵盖了300多条充分验证的部署通路,由此才形成了如下图般的导航图。
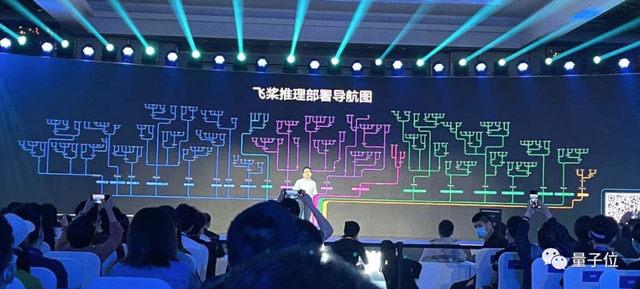
这棵树当中,从根部到每一个树枝都是一个完整打通的路径,可以帮助开发者顺利实现AI部署。
而做出如此之举的原因,百度飞桨给出了他的理由:
每一次“走得通”都有迹可循,每一次“走不通”都能溯本求源。
硬件生态成果
在部署方面的发布,除了“软”的一面,还有“硬”的一面。
据了解,飞桨已经和包括百度昆仑在内的22家国内外硬件厂商,开展适配和联合优化工作,已经完成或正在适配的芯片或IP达到31款。
这其中就包括了英特尔、英伟达、华为、海光、瑞芯微、安霸等芯片企业。

更具体的例子,飞桨在海光DCU上适配的模型已经超过50个。
由此可见,在部署环节的硬件生态方面,百度飞桨已经做到了全面覆盖国内外硬件厂商。
云原生机器学习核心PaddleFlow
随着人工智能技术深入到产业应用,产生了更广泛AI开发场景,对平台提出了更多样化的需求:
- 针对更广泛的垂直行业AI应用开发需求
- 针对深度定制的AI开发平台需求
- 具备AI原生的容器服务
基于此,百度AI产品研发部总监忻舟宣布,正式开放飞桨企业版的“核”——PaddleFlow。

△百度AI产品研发部总监,忻舟
简而言之,这是一个专为AI平台开发者打造、易被集成的云原生机器学习核心系统。
所具备的特色也是非常明显,即云原生、性能优异、轻量易用等。
可以帮助AI平台开发者,高效构建更多细分场景和深度定制的AI平台。
……
除了上述的六大发布之外,还有一些重磅升级。
螺旋桨PaddleHelix于去年正式发布,而在今天正式升级到1.0版本,新增了化合物预训练模型ChemRL,还将ChemRL模型应用到更多的下游任务。
凭借螺旋桨的能力,百度在今年3月国际权威的图神经网络OGB上,在HIV和PCBA两个药物相关的数据集上,获得双冠军。

而作为国内率先加持量子机器学习的量桨,与飞桨框架2.0及其之后的版本同步更新,整体运行速度得到了大幅提升,在核心应用场景平均提升达到 21.9%,最高提升达到 40.5%。
与此同时,量桨还新增了量子核方法等特征提取方式等。
而对于难度很大的纠缠提纯任务,量桨新增了最优化量子纠缠处理框架,给出了目前业界最优且可实施的提纯方案。
还要“发糖”15亿元
除了上述的“六大发布”之外,在此次WAVE SUMMIT 2021上,百度飞桨的“发糖”还在继续。
而且是非常实在的那种“糖”——发钱,15亿元。
在百度飞桨“大航海”计划中,除了去年年底已推出的面向高校AI人才培养的“启航”之外,还包括:
- “大航海”护航计划
- “大航海”领航计划
“大航海”护航计划
10亿元,这是护航计划要在未来三年内资金投入。
给谁?
10万企业和百万产业AI人才。
怎么给?
整体来看,分为三个方面,包括技术、人才和生态。

护航之于企业,要达到的是智能升级,通过技术赋能、市场推广和资源导入,缩短技术创新到商业落地的路径,包括:飞桨技术伙伴计划、飞桨企业版 (万有引力)、飞桨中国行。
而护航之于人才,则是AI私享会、AI快车道和AICA首席AI架构师培养计划。

△ 百度AI技术生态部总经理,刘倩
“大航海”领航计划
这项计划的面向群体,则是核心开发者,目标是与社区开发者一起共建开源生态,并探索前沿技术。
包括PPDE(飞桨开发者技术专家计划)、PPSIG(飞桨社区特殊兴趣小组)、飞桨领航团、博士会等组织形式。

与业界优秀的开源社区和开源项目合作,系统化地设立研究和研发方向,包括探索生物计算、量子计算等前沿方向。
据了解,目前已认证了120位PPDE,飞桨城市/高校领航团已覆盖150个城市。
《AI人才产教融合培养方案》正式发布
其实,在此次发布“领航”和“护航”之前,早在去年年底的WAVE SUMMIT+2020上,百度飞桨便已经推出了“大航海”系列的启航计划:
未来三年,飞桨将投入总价值5亿元的资金与资源,支持全国500所高校,重点培训5000位高校AI师资,联合培养50万AI学子。
时隔近半年之久,这项计划又取得了怎么样的成绩?
飞桨基于丰富的产业实践,在高校人工智能实践课的开展中新增开放了包含人工智能全技术方向的50多个实战案例,到7月底将累积超过100个。
面向高校老师的深度学习师资培训,目前飞桨已累计举办了14期、培养了570所高校的2000+名老师,助力226所高校开设学分课。
承办中国高校计算机大赛等多项赛事,还为高校学生提供实习计划、就业指导,培育适应产业需求的复合型人才。
在会上,还举行了飞桨与三大高校创新创业实验室合作签约仪式。
包括清华大学基础工业训练中心、吉林大学创新创业实验室、郑州大学人工智能工程应用实验室。
它们将与飞桨一起,共同推进产学研用一体化发展,打造产业智能化预备军,开启产教融合新纪元。
最后,此次WAVE SUMMIT除了六大发布和三大生态计划外,还联合信通院,发布飞桨开源生态报告(后台对话框回复“信通院”获取)。
报告指出,人工智能产业已进入工程化应用爆发的窗口期。开源框架能够降低全行业智能化升级的难度,提高其广度和深度。
飞桨开启区域化、特色化、规模化发展的中国开源新生态,加速产业链跨界协同创新,构建人才培养体系。
现场还正式宣布了开源框架前沿模型复现赛。

这是通信院主办的人工智能创新应用大赛的分赛道,将由百度承办,希望能挖掘和培育更多人才,沉淀更多前沿模型,促进整个人工智能的发展。
融合是为了更好的创新
融合创新,这是正常峰会从开始到结束所贯穿的一个“主旋律”。
那么百度飞桨力推“融合创新”的背后,又是怎样的一个逻辑?
首先,融合创新是时代发展的需求。
不同于以往的算法优先,人工智能进入工业大生产阶段,需要算法、数据和算力合力才能发挥、碰撞出更具创新的新价值。
此次百度飞桨在开发、训练、部署等环节中,细节技术上的升级,正是本着这样的一个原则。
例如文心ERNIE开源的四大预训练模型,在技术角度不是走“单线程”路线,而是以“1+1>2”的方式产生更多的创新价值。
其次,企业发展到了一定程度之后,单单是技术的发展,在行业激烈竞争面前,是无力突破固有瓶颈的。
唯有跨界的融合和模式的创新,才能适应越来越严峻的竞争发展。
但除了技术、跨界等方面的融合,还有一点非常重要,也是必不可缺的。
那就是深度学习平台开源生态的融合创新,包括产业、开发者社区和人才培养等。
这对应的便是百度飞桨“大航海”系列计划。
截至目前,飞桨凝聚了320万开发者,服务12万企业,创建36万个模型,涉足医疗、金融、娱乐、环境、能源、工业制造等诸多领域。
而之所以能够达到如此规模,正是因为技术、模式、人才、跨界等诸多方面的融合创新,让AI开发的门槛大大降低,所产生的价值也更为丰富。
不仅可以打造灵活全面的建模方式,还可以满足自定义场景需求。
那么融合创新之下的AI价值带入到产业生产活动中,该是怎样的一条路线?
对此,百度集团副总裁吴甜总结了一条三阶段路线:
- 为支持先行者探路阶段的快速验证落地,飞桨为产业引入AI验证提供了在真实场景中打磨的产业级模型库,并通过便捷的多端多平台部署推理引擎,解决AI落地的“最后一公里”问题。
- 为助力工作坊应用阶段的团队应用AI创新,百度飞桨降低了门槛,使小型团队不用重复造轮子,从移植复用开始,到针对性改写,再到完全自研的全流程提供支持。
- 为支撑工业大生产阶段的多人多任务协同,飞桨通过对算力资源的高效管理、开发者的集成开发环境,全流程效能提升。开源开放,支持多种硬件更是可以实现多企业之间社会化协同生产。
由此可见,飞桨已经走通了AI产业化应用全阶段,为大家找出一条可参考、可实现的道路。
这样的百度飞桨,这样的520,你觉得够诚意了吗?
- 手机实现GPT级智能,比MoE更极致的稀疏技术:省内存效果不减|对话面壁&清华肖朝军2025-04-12
- 7B小模型写好学术论文,新框架告别AI引用幻觉,实测100%学生认可引用质量2025-04-11
- 字节新推理模型逆袭DeepSeek,200B参数战胜671B,豆包史诗级加强?2025-04-11
- Llama 4发布36小时差评如潮!匿名员工爆料拒绝署名技术报告2025-04-07











