阿里的“扫地僧”,2年“抄”了20万页古籍
阿里达摩院用AI,让“离家百年、去国万里”的中华传统古籍,以非传统的方式回归祖国>>>>
金磊 贾浩楠 发自 凹非寺
量子位 报道 | 公众号 QbitAI
阿里达摩院,一个正儿八经搞AI的地方。
但偏偏“扫地僧”们干起了文绉绉的工作:
研究古籍。
他们将流散海外的珍贵古籍善本以数字化的形式请回故土。
第一批达20万页。
△宋百家诗存
当理科生干起了专业文科生的工作,会擦出怎样的火花?
古籍为何“出海”,又如何“回来”?
关于这个故事,很精彩,也很有意义。
古籍为何外流?
1860年(清咸丰10年),五千年文明古国此刻风雨飘摇。
北有英法联军捣毁圆明园,逼迫中国签下《天津条约》、《北京条约》。

南有太平军进入杭州,
藏有《四库全书》的“南三阁”之一杭州文澜阁,次年毁于战乱。
阁圮而书散,无数经典,从此淹没在历史中。

文澜阁遭遇“灭顶之灾”后,杭州藏书家丁申、丁丙兄弟在逃难途中无意间发现文澜阁《四库全书》残编。
相传,丁式兄弟买包子时,偶尔发现包食物的纸,“皆四库书也”,大惊。
于是他们开始紧急救书,上下打点,四处寻访。
经历这轮战乱,文澜阁本《四库全书》的四分之一被丁氏兄弟抢救,四分之三消散飘零,不知所踪。

直到将近100年后的1950年代,清代曹庭栋辑纂的《宋百家诗存》 (卷七),出现在美国加州大学伯克利分校东亚图书馆。
而这本《宋百家诗存》,正是丢失的文澜阁本《四库全书》之一。
目前有线索可查的,只能明确伯克利东亚图书馆从日本三井文库购得这批古书。
△伯克利东亚图书馆
这类古书文物到底经历了怎样的颠簸流离,如今已不可考。
据不完全估计,近代散居海外的中国古籍超过40万部、400万册,包括甲骨简牍、敦煌遗书、宋元善本、明清精椠、拓本舆图、少数民族文献等等。
如今山河无恙,但流散海外的古书典籍,却成了中国文学、历史研究,以及传统文化传承难以弥补的遗憾。
“再现”20万页古籍
大约两年前,阿里巴巴联合四川大学、美国加州大学伯克利分校,共同发起一项公益项目汉典重光,寻觅那些流散在海外的中国古籍,借助达摩院的AI技术,用数字化的方式让它们回归故土。
而鲜有接触古籍的达摩院“扫地僧”们,一开始还不知道AI录入古书是多么有挑战的任务。
OCR(光学字符识别),其实是一种常用的计算机视觉技术,经常被用来识别文字,比如证件、票据、电商平台的商品图片等。
但是,我们生活中常见的OCR,绝大部分是针对现代汉字,而且还是印刷字体,把这样的系统直接拿来用在古书上,根本行不通。
首先,古籍文字的类别极其庞大。现代汉语常用字不过6000多个,常见印刷体,算法能够覆盖到的文字基本上在2万字以内。
但是据估计,古籍文字多达几十万。
为什么古籍上面有如此多的字?
古籍上面每个字都有不同的写法。比如一个“郷”有各种写法。

此外,还有字体的变化。在雕版印刷古籍中,即使是同一拓片在不同季节、气候、地点印出的书也完全不同,而那些人工抄录的古书,更是千人千面。
每一个字形,即使表意可能相同,对于AI来说,也是一个需要重新学习记忆的新知识。
第三,古书版式复杂。除了不同于如今的从右到左,从上到下的排版,在每行字中间还常常夹有批注,这就使得常规使用的行识别方法失效。

△古籍版式复杂
最后,由于年代久远,古书保存状况也各有不同,在AI看来,纸张破损、污渍等等相当于大量的人为噪声。
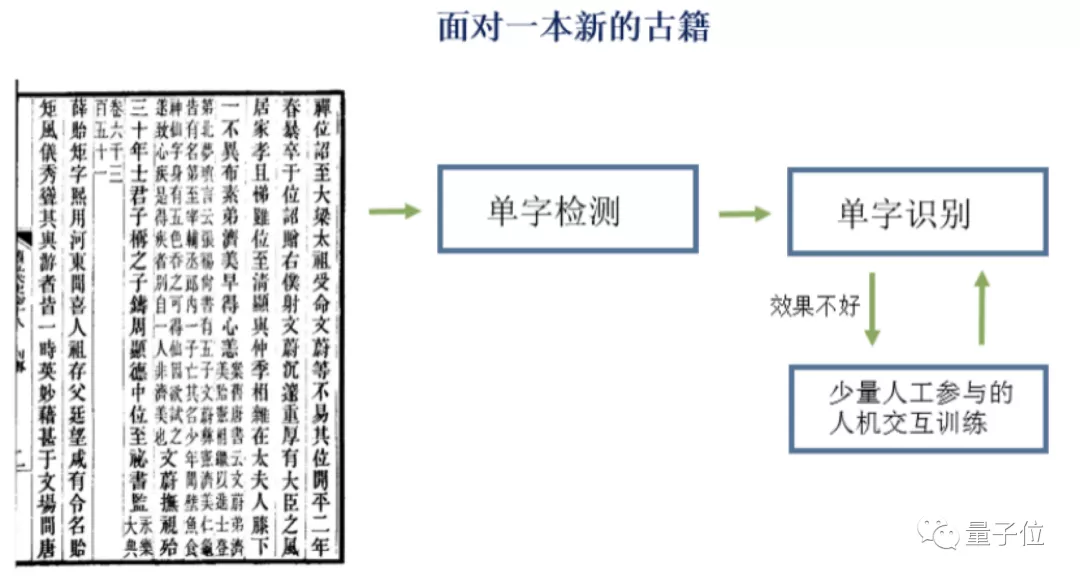
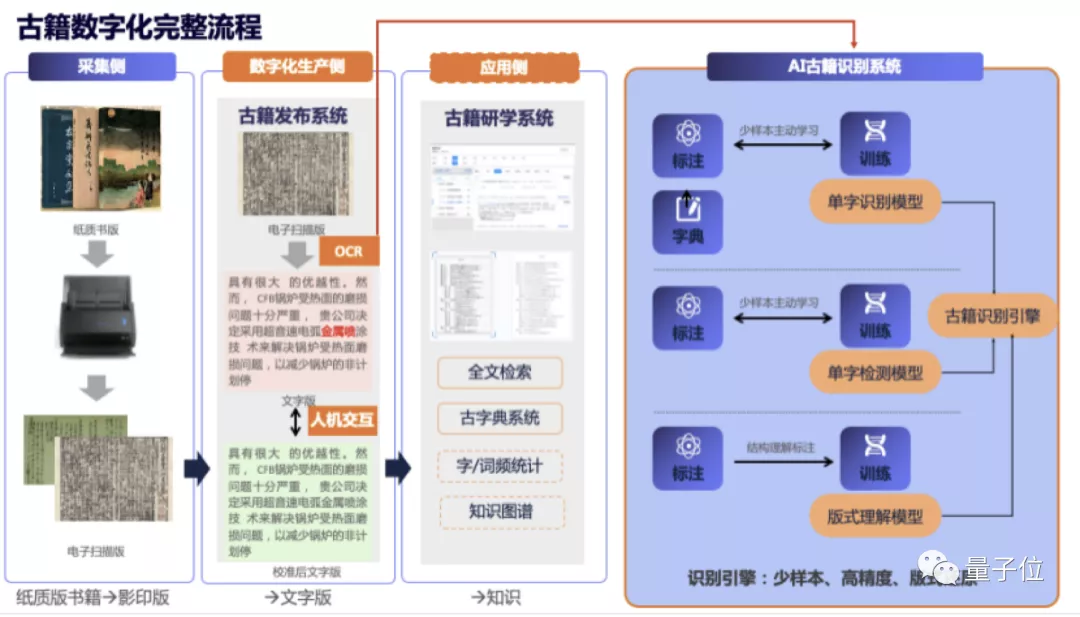
而达摩院,专门为古籍识别开发出了新的系统的。
主要分为两大步,一是聚类数据生产识别,二是主动学习数据生产识别。用到了单字检测、无监督图像聚类、少样本分类、主动学习等一系列机器学习方法。
首先是全书检测,把古籍正文中的每个字都抠出来,作为单独的一张图。
其次是聚类。
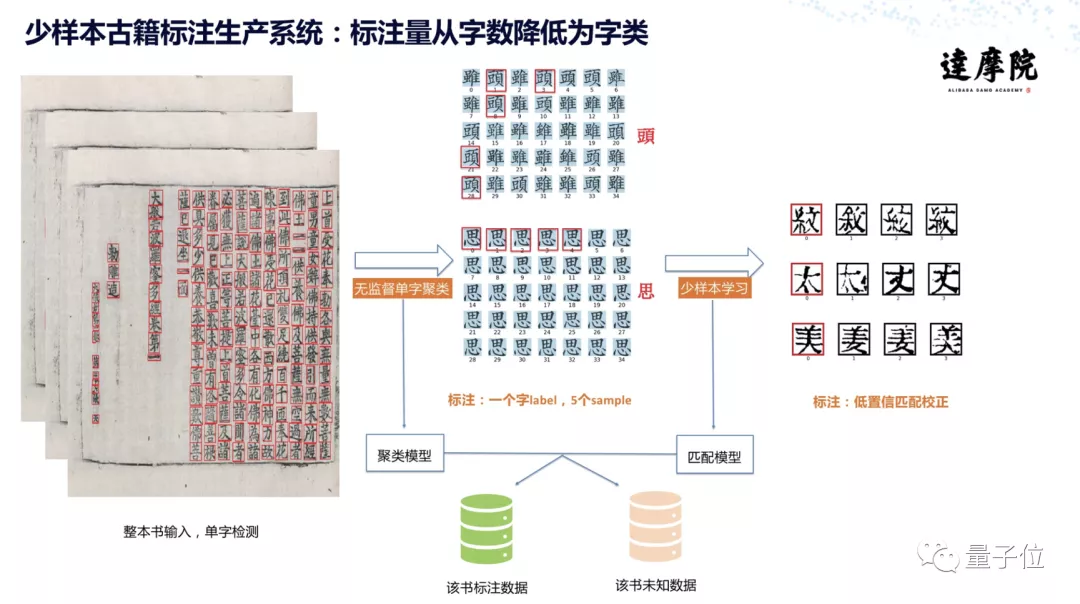
一本古籍总字数可能有10万字,但其中有很多字是重复的,比如“之、乎、者、也”,聚类所做的事就是让机器自动把字形笔画一致的字归为一类,接着再由人工进行标注。也就是说,原来要人工标注全部10万字的书,经过聚类,只需要对全部二三千字类进行标注,一类字只标注一次。
聚类和人工标注,不仅完成了每一类文字的认字过程,还收获更多新的训练样本,可以继续喂给机器学习。
一般来说,数据越多,越有利于模型的训练。但古籍里有很多异体字、生僻字,出现概率极低,根本无法寻觅这么多的样本。
所以团队想到了让机器自动生成样本。使用字体迁移方法来使合成数据,机器自动为每个字合成几个新的样本,确保单字样本量达到10个。这样,就有足够数据训练少样本识别模型。
得到少样本识别模型之后,就能投入使用,把第一步全书检测获得的所有图片进行重新标注。不同于上一轮聚类+人工打标,这次是识别模型的自动标注,如果识别打标的数据与前一轮聚类的结果一致,就可以认为这张图片当前标签是对的。如果不一致,那就让这个字回到聚类步骤,继续迭代。
从聚类打标到少样本模型打标走完一轮,全书70%左右的文字可以被打上正确的标签,余下的30%,从头开始再来一遍,第二轮迭代,又能解决余下文字中的70%。
经过两轮迭代,一本书的91%的文字可以被打上正确的标签。
它们不仅沉淀为了机器的字典,也是更丰富的训练数据。通过前期一本书、一本书地学习,产生的训练数据越来越多,机器的认字能力也越来越强。
最后,就是训练最终模型,能对100本以上的书进行批量识别的单字分类模型。这个模型一出手,对批量数据的识别准确率就高达96%。随着模型的优化和迭代,目前系统对20万页古籍的整体识别准确率已经达到97.5%。今后,AI学到的数据越多,模型的进化程度也会越高。
回到模型“养成”环节,AI识别完绝大部分文字,剩下的需要人工专家补充标注。
那么问题又来了AI怎么知道哪一部分是识别好的,哪一部分是需要交给人类专家的呢?
这个时候,主动学习算法出场了。通过它,机器自己就能找出那些它识别不了的文字,交给人类来做最后一步工作。
以往,人工标注通常需要“两录一检”以达到99.97%的出版要求。
以一本100万字的古籍为例,如果全靠专家录入,每人1000字/天,需要1000天。

达摩院的古籍识别算法,用AI替代人工,在两个环节大幅压缩了专家标注工作量。
在机器为主进行识别的97.5%的内容中,约有1%(1万字左右)需要专家录入;机器不能识别的余下2.5%(2.5万字)的文字,全部交给专家做后期标注。
两部分相加,人工的工作量占全书的3.5%(3.5万字),还是按照一人1000字/天算,需要35天。因此,相比人工专家录入,百万字书籍的数字化工作量从1000天降低到了35天,效率比人工专家录入方案提升近30倍。
阿里达摩院的AI古籍识别算法,为中华古籍的回归提供了另一种可行可期的思路。
不简单的工作
2年,20万页,平均下来每天280页。
再细算一下,每个小时就是11页,还得是在不吃不喝的那种情况。
这对于用传统方式“复现”古籍来说,简直是mission impossible。
为什么这么说?
举个“人工录入”的例子,便一目了然。
在乾隆皇帝执政期间,便组织过一次对《四库全书》的编撰。
《四库全书》共包含3500种书、7.9 万卷、3.6万册,总字数多达8亿。
而当年参与次项目的人数则多达3800人,包括纪昀等360多位高官、学者。
但即便如此人力之下,也是耗时15年才完成。

然而量大,并不是这个工作的唯一难点。
非常直接的一个问题,便是“理科生”和“文科生”之间的碰撞。
阿里达摩院、四川大学历史文化学院,双方在各自的领域都堪称是专家级别。
但之于对方的领域呢?说是小白也不足为过了。
而且AI技术、古籍文化,还都属于上手门槛很高的那种。
为此,双方可谓是恶补知识短板。
历史学家、文献学家,要去学习计算机、AI相关的基础知识,要了解用AI技术识别古籍到底是怎样一个过程。
而阿里达摩院的工程师们,也花费了相当多的精力,去学习历史相关知识。
例如古籍的版本、雕版、印刷、装帧、内容,还包括古文字、古代文化知识等等。
用四川大学历史文化学院副院长王果教授的话说,就是:
在技术研发过程中,比之前预想到的难度还要大。
为此,双方在杭州、成都,开了不下10次的技术研讨会。
整体而言,汉典重光走过的这两年时间,道阻且长、困难重重。
但阿里达摩院和四川大学历史文化学院,却对此从未放弃过。
之于原因,实则这项工作背后所蕴含的意义,不仅仅是“复现”这么简单。
“复现”古籍,意义非凡
让在海外“颠沛流离”的古籍回家,让“沉眠”数百甚至上千年的古籍入世,真的有那么重要吗?
是的,而且非常重要。
具体而言,可以从三个方面来看。
首先是国家层面。
古籍是中华文明的“魂器”, 国家图书馆副馆长张志清说。
纵观历史上世界四大文明,能够延续至今的,也只有中华文明。
很重要原因是,我国拥有一个连绵不绝、经典的文献世界。
我国从古便有盛世修史和盛世整理古籍的传统。
修史、整理文献,表面上是修复残破、逸散的古籍,本质上实则是补全中国文化最重要的载体,是修复中华文明生生不息的生命力,绵延中国文化不息的源泉。
“十四五”规划和国家中长期发展规划中,古籍的保护、整理、研究、利用,得到高度重视。

△宋百家诗存卷首
其次,是研究者、学者层面。
以这次从伯克利回归的20万页古籍来讲,就有很多国内少见或者是没有的珍稀善本。
因此,当这些回归的古籍被AI识别并数字化以后,研究人员、学者足不出户,便可以研究在海外的、无法获取的古籍,未来有望产生一大批重要的研究成果。
最后,是民众层面。
或许很多人会认为古籍离普通老百姓甚是遥远,但实则不然。
中国古籍的内容浩如烟海,拥有非常庞大且复杂的知识体系,所涉及的范围也是极其广泛。
从应对自然灾害、流行疫病、经济波动、政治斗争、外交危机、气候变迁等等内容的经验。
有战争、瘟疫、地震、洪涝灾害、病虫害等等方面的经验总结,更贴近生活的,还包括医疗、中药、养生、家具、服饰、饮食文化等等。
而这些都是“老祖宗”们几千年来的经验总结和积累,是民族智慧的继承。
汉典重光项目没有停留在“回归”海外古籍这个层面,以数字化的形式来展现,大大降低了人们学习、阅读古籍的门槛,拉近了人们与中国文化的距离。
在发布会现场,许多研究古籍的知名教授也亲临现场,他们的眼中充满了对古籍研究的热情与使命感。
中央文史馆馆员、四川大学教授陈力说,他最大的心愿是,利用现代技术,让古籍活起来,让老百姓在古籍面前和祖宗对话,和传统文化亲密接触。
再细数参与此次工作的人员,除了川大的老一辈教授、专家们,像博士生、硕士生,甚至本科生也参与到了其中。
某种程度上,这也是保护文化的一种传承。
也正如阿里达摩院院长张建锋表示:
守护中华传世典籍,是科技工作者和文化工作者共同的使命。
而此次“数字化回归”的这20万页古籍,只是汉典重光迈出的第一步。
阿里和川大还将继续联手,让“离家百年、去国万里”的更多中国璀璨古籍,以数字化方式回归故里。
最后,奉上此次“汉典重光”首批数字化古籍重要书目,若想体验完整数字版,可戳文末链接~

汉典重光 · 古籍数字化平台:
https://wenyuan.aliyun.com/home
- 哈弗全面押注四驱!新能源全系标配Hi4技术,两驱价格享四驱性能2025-04-27
- 中国首款自研V8+上车坦克300虎克版,硬核越野布局全球市场2025-04-27
- 上海车展L4商业化黑马:最强芯片激光雷达同时上车,全无人可换电2025-04-25
- 「千匹马力」被比亚迪打成白菜价:最新汉唐21万起售,比小米SU 7Ultra更小米!兆瓦闪充高阶智驾都标配2025-04-10