很多3D人体模型都很强大,但总是难免“裸奔”。
像要创造出真正的人类“化身”模型,衣服和头发不可或缺。
但这些元素的精确3D数据非常稀少,还很难获得。
来自三星AI中心(莫斯科)等团队的技术人员一直致力于此方面的研究,最终他们开发出这样一个模型:
生成的3D人,穿着原本的衣服、发量发型也都毫无保留地呈现。
乍一看,“跟真人似的”。
更棒的是,无需模特示范,模型还可以“举一反三”,摆出各种POSE!
效果是这样子的:
该模型被命名为StylePeople。
来看看具体怎么搞的吧!
神经装扮模型(The neural dressing model)
其实,不止是“裸奔”,很多三维人体模型还很“死板”:模特摆什么姿势模型就跟着摆什么。
就像此前,利用隐函数来生成的三维人体模型能够高度还原模特的着装和发型了,但是人物姿势依然不够变通,只能从原模特的几个特定视角生成。
ps.也是该团队的研究成果
所以在为3D人体模型还原衣服颜色、褶皱和发型的同时,也要保证人物的姿势可以“举一反三”。
为此研究人员采用将多边形实体网格建模与神经纹理相结合的方法。
多边形网格负责控制和建模粗糙的人体几何姿势,而神经渲染负责添加衣服和头发。
首先他们设计了一个神经装扮模型(The neural dressing model),该模型结合了可变形网格建模与神经渲染,如下图所示。
最左列表示被可视化的前三个PCA组件。
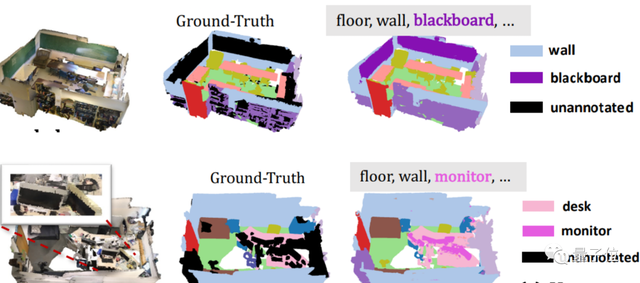
第2、3列为在用SMPL-X建模的人体网格上叠加“人型化身”的纹理(texture)。
第4、5列为使用渲染网络光栅化渲染出的结果。
可以优雅地处理出宽松的衣服和长头发以及复杂的穿衣结构!
接下来,基于上面的神经装扮模型,研究人员造出能生成“Fullbody”的3D人体模型。
最终的生成架构是StyleGANv2和神经装扮的结合。
StyleGAN部分使用反向传播算法生成神经纹理,然后将其叠加在SMPL-X网格上,并使用神经渲染器进行渲染。
在对抗性学习中,判别器将每一对图像看为同一个人。
提高了视频和少量图像生成3D人类模型的技术水平
在对神经装扮这一方法的效果验证中,研究人员首先评估了基于视频素材的3D模型生成结果。
效果如文章开头所展示的图像,左边是示例源帧,其余的图像是左边视频人物的“化身”。在简单的增强现实程序做的背景下,呈现出了模特先前并没有摆过的各种姿势。
接下来,对基于小样本图像素材的神经装扮效果进行评估。
研究人员使用仅两个人的People Snapshot数据集将他们的神经装扮方法与其他各种方法(如360Degree等,见表)进行比较。
衡量生成的模型质量的指标包括LPIPS(感知相似度)、SSIM(结构相似性)、FID(真实样本与生成样本在特征空间之间的距离)、和IS(清晰度与多样性得分)。
结果显示了他们的方法在所有指标上都占有优势,
除了IS以外,但影响不大,因为它与视觉质量的相关性最小。
最后,该团队表示,他们这个模型的生成效果(如下图)仍然受到目前样本数据规模和质量的限制,今后工作重点是提高该模型的数据利用率。
有兴趣的同学可以持续关注该团队的研究进展。
参考链接:
[1]https://arxiv.org/abs/2104.08363