
Jeff Dean被迫发论文自证:解雇黑人员工纯属学术原因
其实挖矿污染更严重
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
还记得去年12月,Jeff Dean在网上成为“千夫所指”吗?
当时谷歌一名员工Timnit Gebru准备发表一篇AI伦理论文,结果双方内部评审上存在着严重分歧,Jeff Dean就把她开除了。

这篇论文指出了大语言模型训练时,造成的碳排放量和能源消耗量过于巨大,还谈到了谷歌BERT在AI伦理上的负面影响。
不到几天,已有1400名谷歌员工和1900名AI学术圈人士对谷歌的行为表示谴责,一向口碑不错的Jeff Dean,也因此成了众矢之的。
现在,Jeff Dean终于“有理有据”了——
他亲自下场,对Gebru的论文进行了指正,表明她统计碳排放量和能源消耗的方法“不合理”,并将结果写成了一篇新的论文。

近日,谷歌联合加州大学伯克利分校,撰写了一篇新论文,仔细研究了AI模型对环境的影响,并得出结果表明:
AI模型,不会显著增加碳排放。
论文指出,Gebru的论文对AI模型产生的碳排放量估算不合理。

“如果数据中心、处理器和模型选择得当,甚至能将碳排放量降低为原来的百分之一。”
“此前评估方法不严谨”
Jeff Dean的这篇论文,同样选择了NLP模型进行研究。
这项研究,将模型的碳排放量定义成多变量函数,(每个变量都对结果有影响)这些变量包括:
算法选择、实现算法的程序、运行程序所需的处理器数量、处理器的速度和功率、数据中心供电和冷却的效率以及供能来源(如可再生能源、天然气或煤炭)。
也就是说,碳排放与很多因素都有关系。

而此前的研究,对模型的评估方法有误,尤其是对基于NAS的模型训练方法理解有误。
以基于NAS方法的Transformer为例,研究者们经过重新评估后,发现碳排放量可以降为原来的八十八分之一。
研究者们还表示,采用新公式估计机器学习模型的碳排放量的话,净排放量可以降低10倍。
采用新公式,研究者们重新估计了5个大语言模型的能源使用量和二氧化碳排放量:
- T5,谷歌预训练语言模型,86MW,47吨
- Meena,谷歌的26亿参数对话机器人,232MW,96吨
- GShard,谷歌语言翻译框架,24MW,4.3吨
- Switch Transformer,谷歌路由算法,179MW,59吨
- GPT-3,OpenAI大语言模型,1287MW,552吨
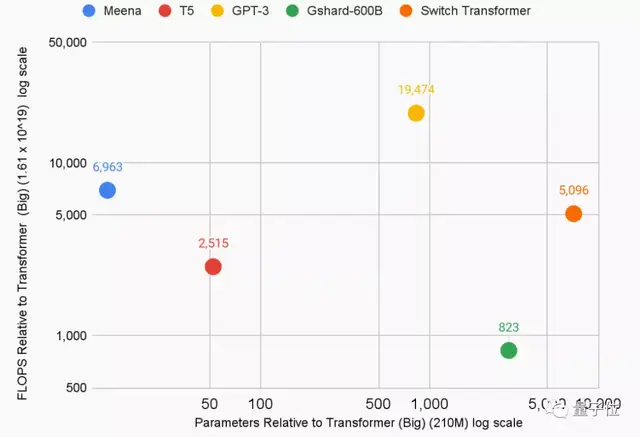
不过,即使谷歌的碳排放量,真是Jeff Dean这篇论文统计的结果,这些模型训练导致的二氧化碳排放总量也已经超过200吨。
甚至OpenAI的一个GPT-3模型,就已经达到了这个数值。
这相当于43辆车、或是24个家庭在一年内的碳排放量。
论文还表示,谷歌会继续不断提高模型质量、改进方法,来降低训练对环境造成的影响。
例如,谷歌对Transformer改进后的Evolved Transformer模型,每秒所用的浮点计算降低了1.6倍,训练时间也减少了1.1~1.3倍。
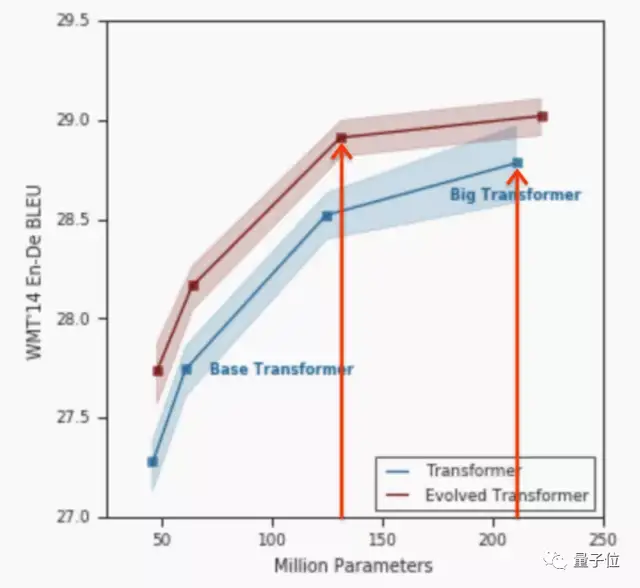
除此之外,稀疏激活(让信息编码中更多元素为0或趋近于0)也同样能降低模型能耗,甚至最多能降低55倍的能源消耗、减少约130倍的净碳排放量。
这篇论文,还引用了发表在Science上的一篇论文:
即使算力已经被增加到原来的550%,但全球数据中心的能源消耗仅比2010年增长了6%。
论文最后给出的建议如下:
需要大量计算资源的机器学习模型,在实际应用中,应该明确“能源消耗”和“二氧化碳排放量”的具体数值,这两者都应该成为评估模型的关键指标。
所以,Jeff Dean忽然参与到碳排放量研究中,到底是怎么回事?
与谷歌利益相冲突
事实上,这篇论文是对此前Timnit Gebru合著的一篇论文的“指正”。

Gebru那篇论文的标题,名为「On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?」(随机鹦鹉的危险:语言模型会太大吗?)
论文提出,自然语言模型存在“四大风险”:
- 环境和经济成本巨大
- 海量数据与模型的不可解释性
- 存在研究机会成本
- 语言AI可能欺骗人类
论文表明,使用神经网络结构搜索方法(NAS)的语言模型,会产生相当于284吨的二氧化碳,相当于5辆汽车在其寿命内的碳排放量。
论文还以谷歌的NLP模型BERT为例,指出它会在AI伦理上会产生一系列负面影响:
它排放的1823磅二氧化碳量,相当于纽约到旧金山航班往返的碳排放量。
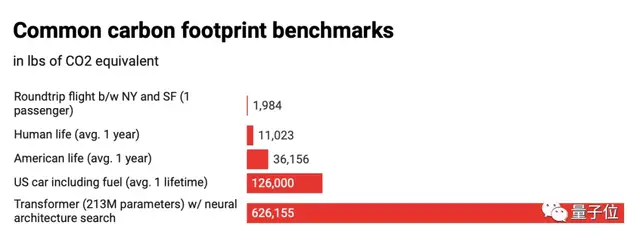
这篇论文被认为显然不符合谷歌的商业利益。
谷歌此前开发过许多AI模型,包括云翻译和NLP语言对话模型等,而谷歌云业务,还在2021年Q1收入增长了46%,达到40.4亿美元。
论文被送到谷歌相关部门审核,但过了两个月,却一直没有得到反馈。
2020年12月,Gebru忽然被解雇。
Jeff Dean表示,Gebru的论文存在着一些漏洞,只提到了BERT,却没有考虑到后来的模型能提高效率、以及此前的研究已经解决了部分伦理问题。

而开除原因,则是因为“她要求提供这篇论文的审核人员名单,否则将离职。”
Jeff Dean表示,谷歌无法满足她的要求。
这件事一直发酵到现在,Jeff Dean也正式给出了论文,“学术地”回应了这件事情。
和挖矿相比如何?
据Venturebeat报道,此前研究表明,用于训练NLP和其他AI模型的计算机数量,在6年内增长了30万倍,比摩尔定律还要快。
MIT的一项研究人员认为,这表明深度学习正在接近它的“计算极限”。
不过,商业巨头们也不是完全没有行动。
OpenAI的前老板马斯克,最近还悬赏了1亿美元,来开展碳清除技术比赛,比赛将持续到2025年。

这场主办方是XPRIZE的比赛,鼓励研究碳清除技术,来消除大气和海洋中的二氧化碳,以对付全球气候变暖的事实。
但这项技术,目前还不具备商业可行性。
据路透社表示,光是去除一吨碳,就需要花费超过300美元的成本,而全世界一年排放的温室气体,相当于约500亿吨二氧化碳。
那么,产生的这些碳排放量,和挖矿相比如何呢?
据Nature上的一项研究显示,到2024年,中国的比特币挖矿产业可能产生多达1.305亿吨的碳排放量,相当于全球每年飞行产生的碳排放量的14%。

具体到年份的话,到2024年,全球挖矿产生的能量将达到每年350.11TWh(1太瓦时=10^9×千瓦时)。

而据Venturebeat的报道,训练机器学习模型耗费的能量,每年估计也将达到200TWh。
对比一下的话,一个美国家庭平均每年消耗的能量仅仅是0.00001TWh。
看来,挖矿造成的环境污染,确实要比机器学习模型更严重……
论文地址:
https://arxiv.org/abs/2104.10350
参考链接:
[1]https://venturebeat.com/2021/04/29/google-led-paper-pushes-back-against-claims-of-ai-inefficiency/
[2]https://www.reuters.com/article/musk-offering-prize-carbon-removal-0422-idCNKBS2CA025
[3]https://www.nature.com/articles/s41467-021-22256-3
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07










