我用90年代的古董电脑训练CNN
网友:心疼电脑
杨净 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在90年代的电脑上实现CNN是一种什么体验?
最近,一位日本小哥武田广正(音译)就在1990年的电脑PC-9801上实现了CNN来识别手写字符。

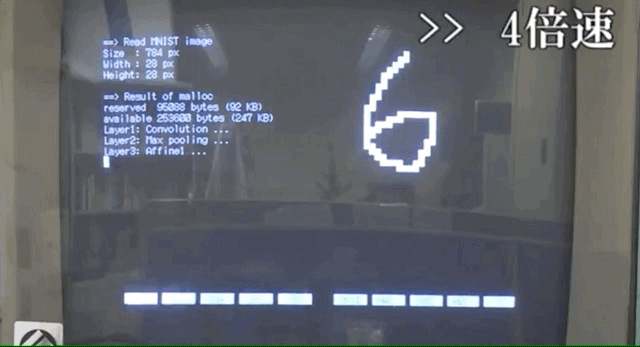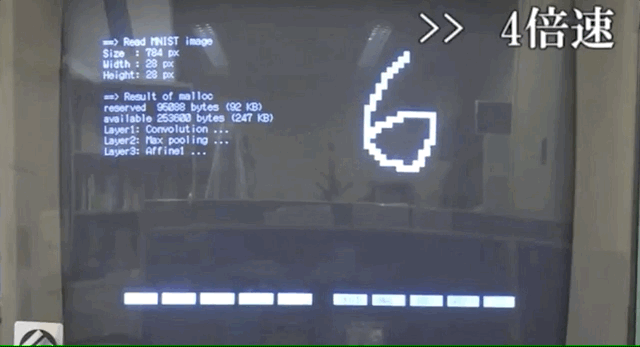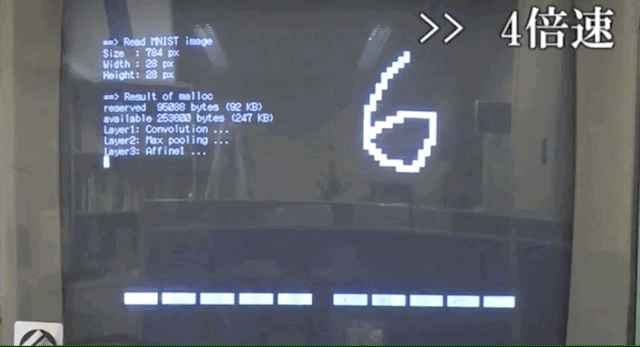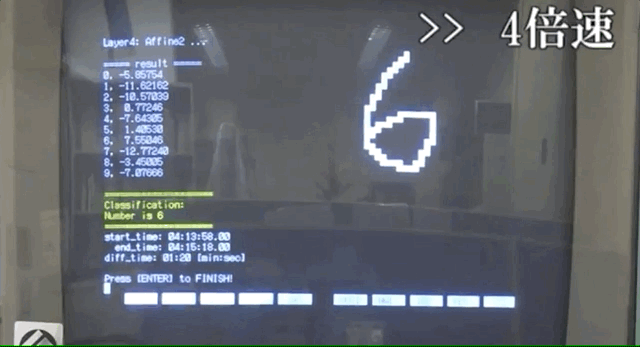
就像这样。
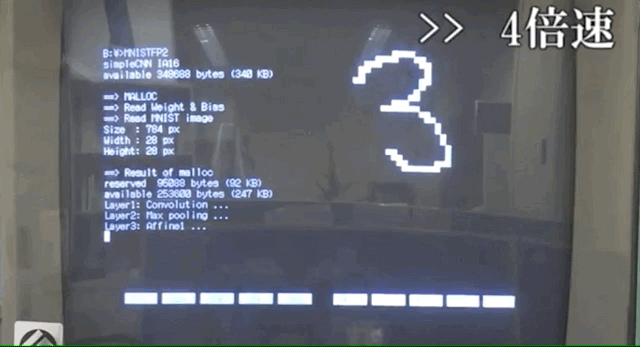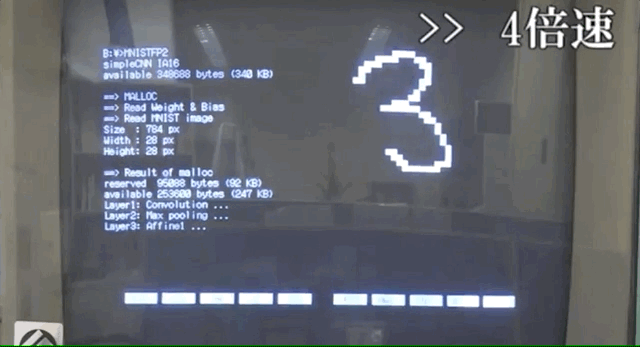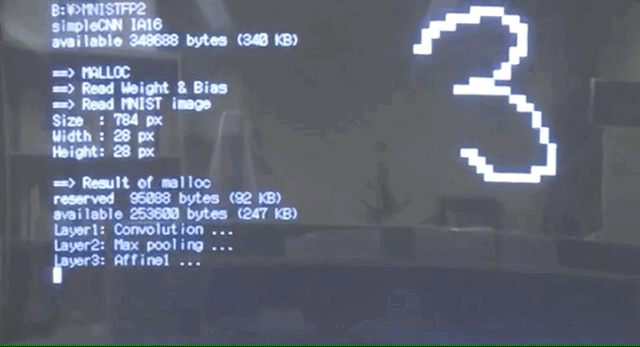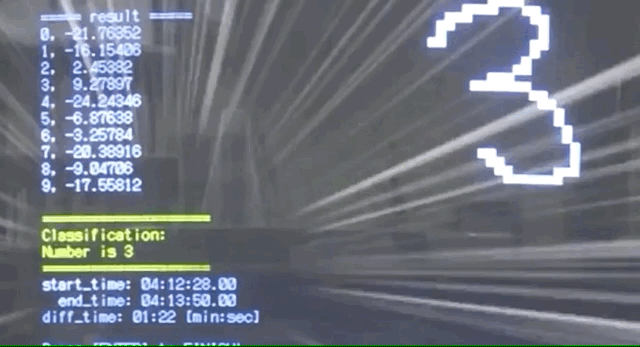
可能因为电脑性能的限制,整个识别过程要消耗一分多钟。
原来30年前CNN是这样实现的。
他还将整个过程分享到了推特上,得到了大量的关注。
不少网友惊叹之余,还表示,心疼这个电脑,学习AI一定很难……
如何实现?
虽然目前这项技术还没有开源,但早在93年就已经有人将CNN玩得很溜了。
这个人就是LeCun。
前不久,一段关于LeCun93年的视频火了。视频中展现的是,当时的文字识别系统已经用上了CNN。

他首先是电脑的系统中编写了一种网络数据结构的编译器,并生成了可编译的 C 语言代码,在源代码中以权重和网表(netlist)代表文字。
整套系统是在算力为20MFLOPS 的DSP版上运行。
当时,手写数字数据集 MNIST还没有问世,LeCun则用摄像拍摄来构建文字识别系统的。除此之外,还需要解决文字缩放、位置等问题。
只需在纸上写好任意数字,不管任意大小形状,或者带有一定的“艺术性”,只要用摄像头导入电脑,就可以识别。

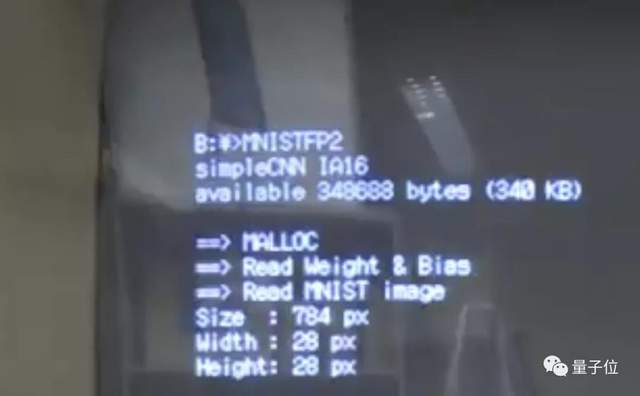
而这位日本小哥则是在MNIST数据集上构建的,电脑上清晰展现了识别过程。
首先,读取MNIST的数字图像的信息。
随后,进行一波卷积、池化等操作。
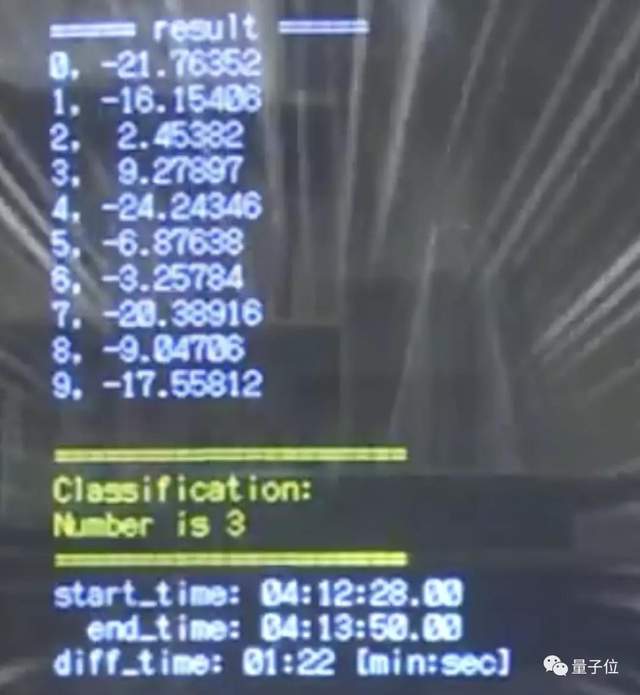
最后经过SoftMax层,每个数字转换成概率或者权重,按照权重大小选出所得数字。
背后的作者
武田广正,来自岩手县立大学信息学研究院,喜欢操作系统以及研究复古电脑,曾撰写《Raspberry Pi GPGPU入门》
因为这个项目,他在enPiT的PBL活动中获得了优秀奖。

他表示,会将这一教程编写进《令和的PC-98编程》一起发行,源代码将在GitHub上提供。
参考链接:
https://twitter.com/T_taisyou/status/1357655009618399232
- 人人可用的超级智能体!100+MCP工具随便选,爬虫小红书效果惊艳2025-04-29
- 当购物用上大模型!阿里妈妈首发世界知识大模型,破解推荐难题2025-05-01
- OceanBase全员信:全面拥抱AI,打造AI时代的数据底座2025-04-27
- 网易有道张艺:AI教育的规模化落地,以C端应用反推大模型发展2025-04-27