李飞飞团队从动物身上get AI新思路,提出RL计算框架,让机器在复杂环境学习和进化
深度进化强化学习计算框架DERL
杨净 发自 凹非寺
量子位 报道 | 公众号 QbitAI
如果机器能像动物一样学习与进化会如何?
这是李飞飞团队的最新研究。

在过去6亿年中,动物在复杂的环境中学习与进化成各异的形态,又利用进化的形态来学习复杂的任务。如此周而复始的学习与进化,造就了动物的认知智慧。
但其中环境复杂性、进化形态和智能控制的可学习性之间的关系原理仍然难以捉摸。
本中提出了一种深度进化强化学习计算框架DERL。它可以演化不同的形态,在复杂的环境中学习一些具有挑战性的运动、操纵任务。

最终利用DERL,研究人员证明了环境复杂性、形态智能和控制的可学习性之间的几个关系。
通过学习和进化来实现的形态智能
创建适应性的形态,在复杂的环境中学习操纵任务是具有挑战性的,存在双重困难。
第一种,在大量可能的形态组合中进行搜索。第二种,通过终生学习评估适应性所需要计算时间。
因此,此前的工作要么在有限的形态空间中进化,要么专注于寻找固定的形态最佳参数,亦或是就在平坦的地形中学习。
为了克服这些实质性的限制,本文提出了深度进化强化学习(Deep Evolutionary Reinforcement Learning,DERL)计算框架。
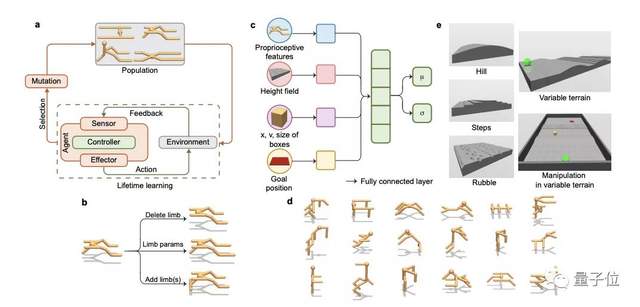
本文提出了一种高效的异步方法,用于在许多计算元素之间并行化学习和进化基础计算。
如图(b)所示,进化的外循环通过突变操作优化机器形态,比如高度、位置、箱子的大小等属性。
而内部的强化学习循环则用来优化神经控制器的参数。
还引入了一个UNIMAL,即UNIversal aniMAL形态设计空间,如图(d)所示,它既具有高度的表现力,又丰富了有用的可控形态。
而复杂环境由三个随机生成的障碍物组成:山丘、台阶和碎石。模型必须从初始位置(图e绿色物体)开始,并将一个盒子移动到目标位置(红色方块)。
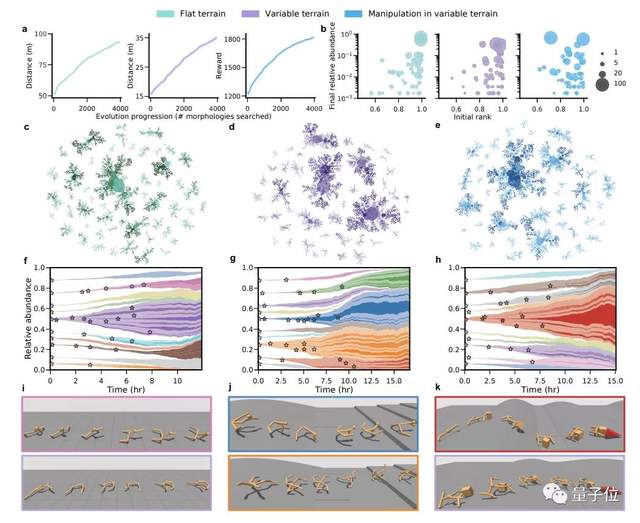
此外,DERL创建了体现型的模型,不仅可以在较少的数据进行学习,还可以泛化解决多个新任务,从而缓解了强化学习的样本效率低下。
DERL的运作方式是模仿达尔文进化过程中几代模型在形态上的搜索、一生中的神经学习交织在一起的过程,通过智能控制来评估一个给定形态解决复杂任务的速度和效果。
总共有8个测试任务,涉及了稳定性、敏捷性和操纵性的测试,来评估每个形态对强化学习的促进作用。
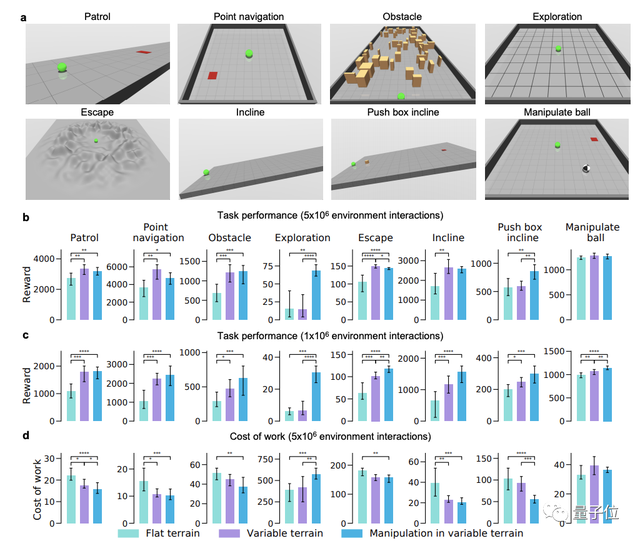
研究人员在每个环境的3次进化运行中挑选出10个表现最好的形态。然后,每个形态从头开始训练所有8个测试任务。
最终选出了在不同环境下演化出的最佳模型形态。
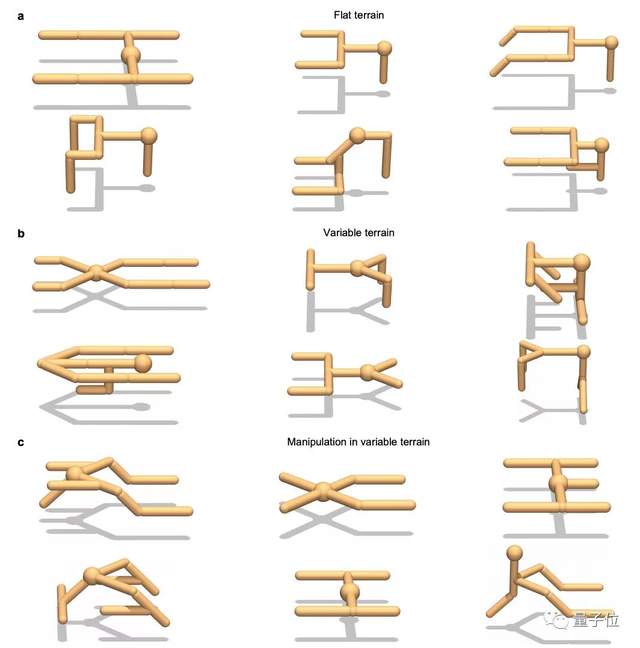
结果发现,通过鲍德温效应,模型适应性可以在几代的进化过程中从其表型学习能力迅速转移到其基因型编码的形态上。
(鲍德温效应:没有任何基因信息基础的人类行为方式和习惯,经过许多代人的传播,最终进化为具有基因信息基础的行为习惯的现象。)
这些进化后的形态学又赋予了模型更好更快的学习能力,以适应新任务。
团队猜测,很可能是通过增加被动稳定性和能量效能来实现的。

此外还证实了环境复杂性、形态智能和可学习性控制之间存在着以下的关系。
首先,环境复杂性促进了形态智能的进化,以一种形态促进学习新任务的能力来量化。
其次,进化时会迅速选择学习速度较快的形态,这一结果构成了长期以来猜想的形态学鲍德温效应的首次证明。
第三,实验表示, 鲍德温效应和形态智能的出现都有一个机理基础,即通过物理上更稳定、能量效率更高的形态的进化,从而可以促进学习和控制。
团队介绍
这篇文章李飞飞团队领衔,由来自斯坦福大学计算机科学系、应用物理系、吴蔡德神经科学研究所等团队共同研究。

第一作者是Agrim Gupta,斯坦福大学二年级博士生,致力于研究计算机视觉。

论文链接:
https://arxiv.org/abs/2102.02202
- AI应用突围,中小企业的新周期已至2025-04-11
- GPT-4o能拼好乐高吗?首个多步空间推理评测基准:闭源模型领跑2025-04-23
- 飞猪AI意外出圈!邀请码被黄牛倒卖,分分钟搞定机酒预订,堪比专业定制团队2025-04-20
- 21岁学生开发AI作弊工具被哥大停学,转入拿下530万美元融资2025-04-22