Nature盘点的这些代码,个个都改变了科学:Fortran、AlexNet还有arXiv等
还有IPython Notebook
杨净 发自 凹非寺
量子位 报道 | 公众号 QbitAI
今天,Nature的一篇报道有点不同。
没有说最新的科学研究进展,也没有说这个时代的科学家们。
而是将镜头聚焦在计算机上,更具体一点,是聚焦在计算机代码上。

在过去的一年中,Nature对数十名研究人员进行了调查,以选出这几十年以来,改变研究的关键代码。
现在,评选结果新鲜出炉。
简单看了下,有半世纪的“语言先驱”、“祖宗之法”Fortran,理工科的老朋友了,相信个中滋味很多人都能体会。
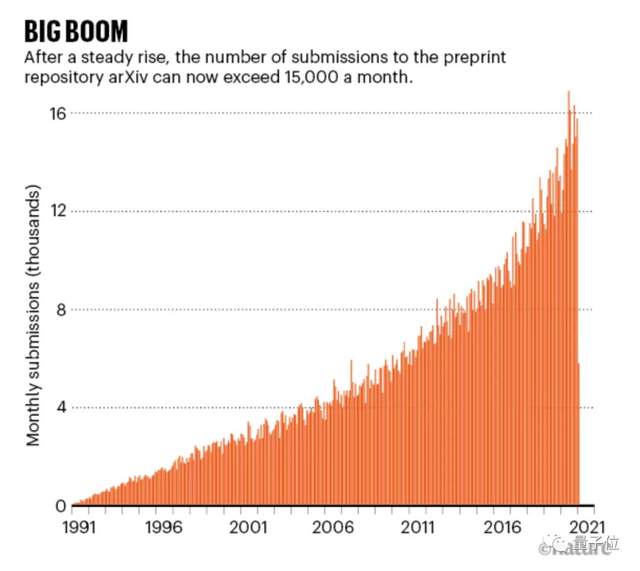
还有不知不觉已经“而立之年”的论文利器arXiv.org——全球最大的免费预印本平台,每月吸引超过15000份投稿和3000万次下载。
……
究竟还有哪些代码改变了现在的科学?Nature又为何Pick这些代码?
“语言先驱”Fortran(1957)
说到Fortran,相信很多大学生都受到它的摧残“洗礼”。
在知乎上有一个2015年的古早问答:“和 C++ 相比,用 Fortran 编程是怎样的体验?”
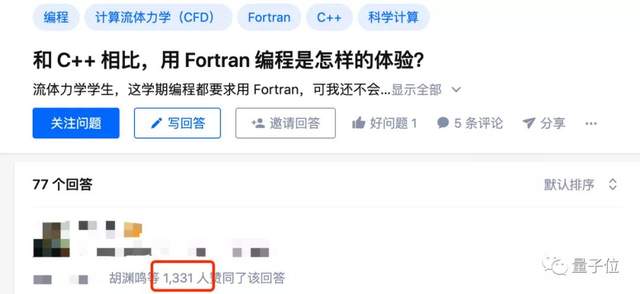
其中一个高赞回答讲述了他被Fortran“洗礼”的经历,引发广泛共鸣,得到了1331个点赞。
即便如此,依然没办法磨灭它在语言界的地位。
最早的现代计算机对用户,尤其对科学家并不友好。其中的机器语言、编程语言需要科学家对计算机的体系结构有深入的了解。
直到在上个世纪50年代,IBM团队开发了“公式翻译语言”Fortran,情况发生了改变。
普林斯顿大学的气候学家Syukuro Manabe表示,Fortran使非计算机科学家的研究人员可以访问程序。

他和他的同事使用该语言开发了全球第一个气候模型,被美国国家海洋和大气管理局200年来发生的十大突破之一。
如今,Fortran已经发展到第八个十年了,它仍然被广泛地应用于气候建模、流体动力学、计算化学等一些涉及复杂计算的学科。
古早的Fortran代码库仍然活跃在实验室和全球的超级计算机上。
而立之年的arXiv.org(1991)
一定没有想过,几乎所有科研人员都使用过的论文福音——arXiv已进入第三十个年头。
目前,它已经收录约180万份预印本,全部免费提供大家交流。
每月的投稿和下载数量也一直只增不减。
据Nature统计,现在每月将吸引了15000多份投稿和约3000万次下载。
而它一开始,也不过只是一个聚焦于高能物理的电子邮件自动回复系统。
在没有arXiv之前,科学家们大多通过邮寄的方式将提交的手稿副本寄给同事,以征求评价。
但寄出的数量有限,看到论文的也不过几个人。
见到此状,一位墨西哥州工作的高能物理学家Ginsparg决定编写了一个电子邮件自动回复系统。
订阅者每天都会收到预印本的清单,每个清单都有一个文章标识符。
于是,通过一封电子邮件,世界各地的用户可以从实验室的计算机系统中提交或检索文章,获得新文章列表或按作者、标题搜索。
一开始,Ginsparg计划是将文章保留三个月,论文内容限制在高能物理学界。
但在同事的说服之下,1993年他将该系统迁移到互联网上。5年之后,他给它起了今天的名字:arXiv.org。
Hinton指导的AlexNet(2012年)
如果要说当前更接地气一点,就要提到这个快速学习AI——AlexNet。
一开始,人工智能有两种。一种是使用编码规则,另一种使用计算机通过模拟大脑的神经结构来“学习”,几十年来,人工智能研究人员一直将后一种方法视为“废话”。直到2012年,Hinton改变了这一格局。

最初的ImageNet全球挑战赛,最好的算法错误率也有25%之高。
而Hinton的两位研究生提出的这个AlexNet,一种深度学习算法,直接将错误率降低到了16%。
Hinton表示,我们基本上将错误率降低了一半,或者说几乎降低了一半。而这样的成绩,揭开了深度学习在各个领域上的应用。
200年“历史”的快速傅里叶变换(1965)
相信很多数学、工程领域的同学都对它很熟悉, 快速傅里叶变换 (fast Fourier transform) 即利用计算机快速计算离散傅里叶变换(DFT)的统称,简称FFT。
值得一提的是,这里的基本思想早在1805年就已推导出来,但直到在1965年才得到普及。
来自美国的两位数学家James Cooley和John Tukey提出利用算法让计算所需要的乘法次数大为减少,特别是被变换的抽样点数N越多,FFT算法计算量的节省就越显著,计算速度也会提高。
比如,对于1000抽样点数,速度提升约100倍;对于100万点,速度提升5万倍。
由此,快速傅里叶变换开启了数字信号处理、图像分析、结构生物学等方面的应用。它曾被IEEE科学与工程计算期刊列入20世纪十大算法。
软件驱动的生物数据库(1865)
数据库已经成为当今科学研究的一个重要组成部分,以至于很少有人注意到它其实是由软件驱动的。
在过去十几年中,数据库以肉眼可见的速度影响了很多领域,但也许没有什么地方可以比生物学更为显著。
不管是从蛋白质序列发现癌症致病因子,还是合成生物学等领域都少不了庞大基因组和蛋白质数据库的工作。
上个世纪60年代初,当生物学家还在努力拆解蛋白质的氨基酸序列时,Margaret Dayhoff(生物信息学先驱)则开始默默整理这些蛋白质信息,创建蛋白质和核酸数据库以及查询数据库的工具。
她的《蛋白质序列和结构图谱》在1965年首次出版,描述了当时已知的65种蛋白质的序列、结构和相似性。而且她还将其数据编码在打孔卡中,这使得扩大数据库并进行搜索成为可能。
之后,更多计算机化的生物数据库也随之而来,蛋白质数据库于1971年上线,今天它详细记录了17万多个大分子结构。
天气预报员:一般流通模型(1969年)
“蚂蚁搬家蛇过道,明天必有大雨到。”
以前的天气预报都是依靠人们的经验和直觉,直到这个模型——一般流通模型的出现,根据物理定律进行气候建模的工作,由此开启了计算机预测天气的时代。
在20世纪40年代末,现代计算机之父约翰·冯·诺依曼便成立了他的天气预测小组。
1955年,第二个团队—地球物理流体动力学实验室也开始了所谓的 “无限预报”—即气候建模的工作。

直到1969年,这其中才有人真正做出了天气预测模型,使其首次能够在硅片中测试二氧化碳水平上升的影响。,创造了2006年Nature形容的科学计算的“里程碑”。
今天的模型可以将地球表面划分为25×25公里的方块,将大气层划分为几十个层次。
相比之下,Manabe和Bryan的海洋-大气组合模型,使用的是500公里的方块和9个层次,只覆盖了全球的六分之一。
除此之外,还有数字处理者BLAS,显微镜必不可少的NIH Image,序列搜索器BLAST,数据浏览器IPython Notebook。
好了,你Pick哪一款?如果其他心仪的代码,欢迎与我们分享。
更多细节可戳下方链接了解哦~
参考链接:
https://www.nature.com/articles/d41586-021-00075-2
https://www.zhihu.com/question/28683874
- 飞猪AI意外出圈!邀请码被黄牛倒卖,分分钟搞定机酒预订,堪比专业定制团队2025-04-20
- 首个AI科学家发论文进ICLR!得分6/7/6,从选题到实验全程零人工2025-04-09
- AI应用突围,中小企业的新周期已至2025-04-11
- 商汤大装置发放“1亿代金券”,全栈赋能场景落地2025-04-10