
这款超火的游戏,AI只用4小时,就秀出了人类花1年才能达到的水平
Reddit热度2.7k
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
操控一辆赛车,在空中带球射门,需要练习多长时间?
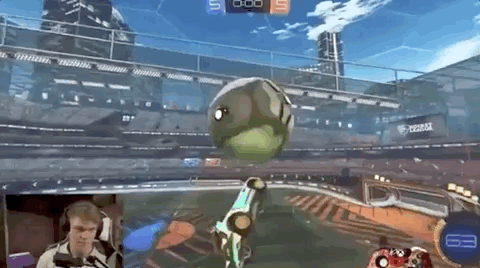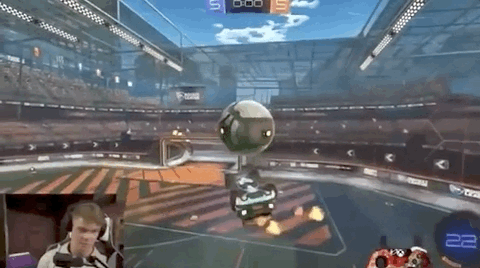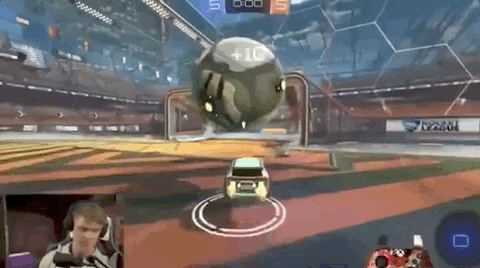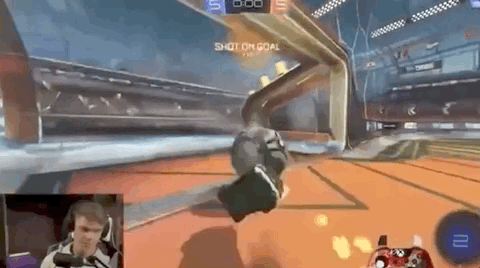
通常来说,一名普通玩家要达成这样的水平,至少要练习上一年时间。
这是一款国外很火的游戏《火箭联盟》 (Rocket League),玩家会操作一辆赛车,利用各种办法将球“踢”进门。
然而,现在已经有人开发出了一个基于深度强化学习的赛车游戏环境RoboLeague。通过环境训练的赛车,不仅能看准时机射门:
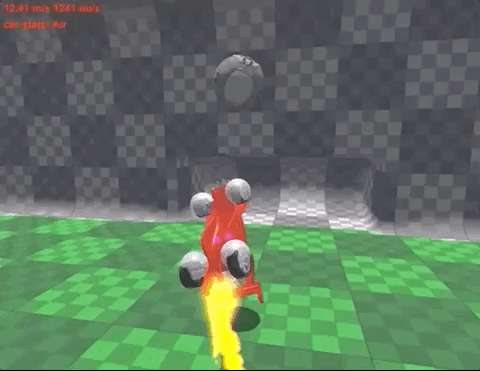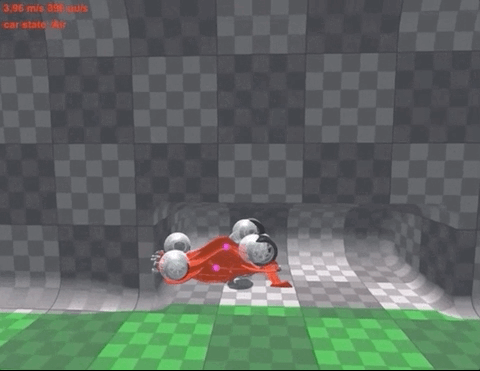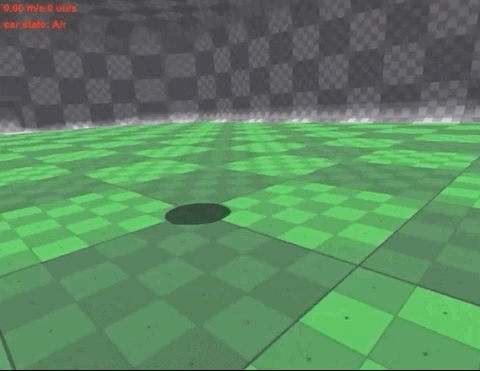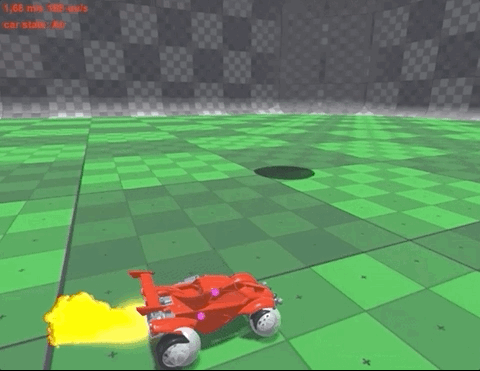
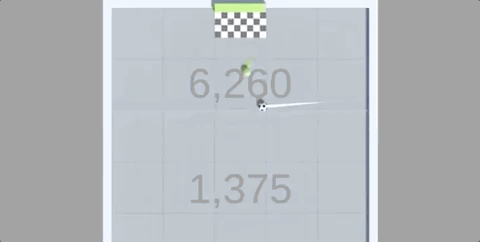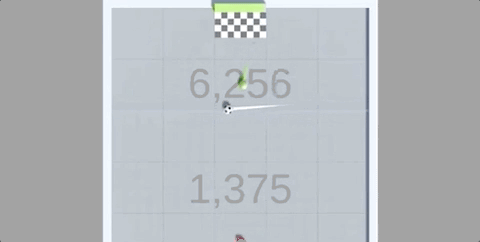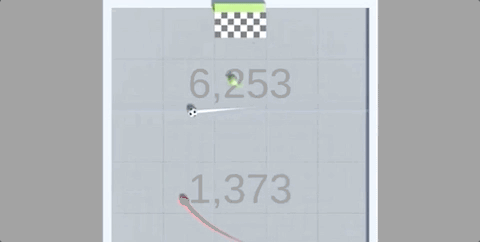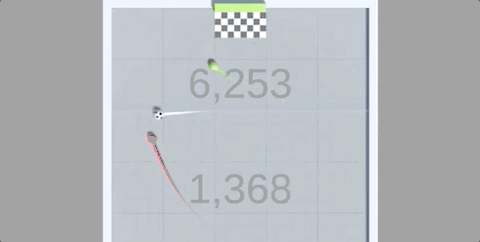
还在4小时的训练后,就能长时间颠球,保证车和球都不落地:

这个RoboLeague,一下子在Reddit炸出了2.7k的热度。

有网友调侃,看到这些比自己玩得好的“AI选手”,总会让他感觉很挫败。

那么,这个赛车游戏环境,究竟优秀在哪里?
比已有的游戏环境更好用
事实上,这并不是第一个基于《火箭联盟》做出的游戏环境。

有网友很快指出,此前已有支持用自定义赛车玩《火箭联盟》的RLBot,效果挺不错。
在RLBot中,同样允许玩家用自己编写的代码来控制赛车。
而且,玩家能通过游戏场景的反馈,对代码进行反复调试,最终做出想要的机器人赛车。
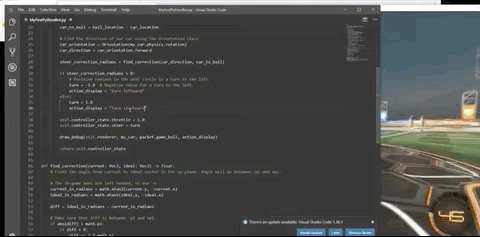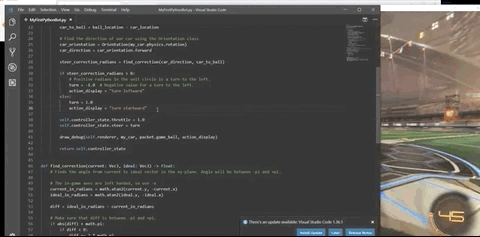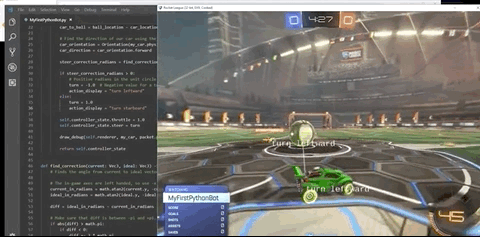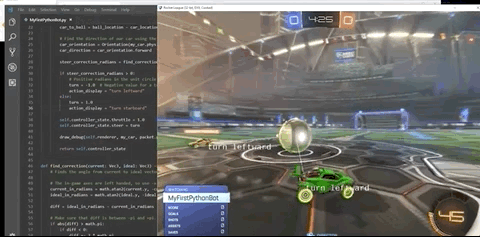
事实上,作者在训练强化学习模型前,并非没有考虑过RLBot。
毕竟,这个框架支持各种语言,让玩家能编写出想要的机器人赛车。

然而,在尝试过RLBot后,作者还是决定基于Unity引擎,自己开发一个游戏环境。
主要有3点原因:
- 基于Unity引擎打造的环境,能够自己创建想要的游戏场景。
- 此外,在RLBot中,基于实时数据训练AI模型的速度,其实并不快。而如果游戏再大点,在RLBot中训练可能就会出现问题了。
- 自己创建的游戏环境,可以并行训练游戏中的多个实例。相比之下,RLBot基于《火箭联盟》搭建,只能同时玩1场游戏,无法并行训练。
那么,在RoboLeague环境中,如何训练出这样一个“聪明的”智能体?
基于强化学习,训练出智能体
在训练之前,先来了解一下,《火箭联盟》中大致有些什么规则,玩家又是怎么射门的。

整体来说,这是一个玩家通过控制赛车,来进球射门的游戏。
其中,这里面的赛车和球,符合一些物理规则:
球具有弹性,可以从地面/墙壁反弹、受摩擦力和重力影响
赛车在地面可以加速制动,在空中的控制也符合物理条件
赛车的轮子具有某种黏力,可以在墙壁上运动不脱落下来
而《火箭联盟》中的一些高级玩家,通常会想办法让自己和球不落地,完成空中带球射门。
但要达到这样的水平,不仅要对场地有足够的了解,操作水平也必须在线。
这其中,作者利用了强化学习中的“奖励机制”,来告诉智能体应该怎么做。
智能体并不需要基于先验知识完成操作,而会通过尝试各种随机行为,试图达成“奖励机制”的要求。
而作者给出的唯一一个奖励机制,就是保证赛车和球不落地,即“活着”。
因为只要不落地,空中带球的条件就完成了大半。

在反复尝试后,智能体发现,只要让赛车尽可能垂直竖在空中,同时保持颠球的稳定,就能保证“活着”。
也正是在这样的奖励机制下,只用4个小时(约50M次运行),赛车就完成了自己的目标。
如果想要让智能体完成更复杂的任务,如空中带球射门等,也只需要找到对应的奖励机制,利用强化学习训练就能达成。
目前,作者已经将RoboLeague开源。
也就是说,如果你想要训练出符合自己要求的深度强化学习模型,那么用这个游戏环境,就能进行训练。
关于作者
作者@Roboserg,并未透露自己的真实姓名,不过此前,他已经做出了很多利用强化学习训练出来的小型游戏实验。
例如,在各种球的撞击下保持平衡的飞机:

又或者,两个球之间的“足球”比赛:
据作者透露,他接下来还会计划开发一款穿越飞环的游戏。
这款游戏会训练智能体穿过飞环,真正做到和大神玩家的操作无异。
说不定,作者甚至真能用强化学习,训练出一整个网站的小游戏来?
源代码:
https://github.com/roboserg/RoboLeague
参考链接:
https://www.reddit.com/r/MachineLearning/comments/klbvaw/p_doing_a_clone_of_rocket_league_for_ai/
https://rlbot.org/
https://unity.com/cn/products/machine-learning-agents
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07










