
都在说GPT-3和AlphaFold,2020没点别的AI技术突破了?
2020年是巨大飞跃的一年。从OpenAI的GPT-3,再到AlphaFold,都是令人振奋的成就。与此同时,数据科学在机器学习、自然语言处理(NLP)、计算机视觉等领域中蓬勃发展。
晓查 蕾师师 发自 凹非寺
量子位 报道 | 公众号 QbitAI
2020年在紧张的防疫工作中悄然过去。这一年,人工智能却从来没有停下前进的脚步。
这一年人工智能行业有哪些新进展?为全球疫情做了哪些贡献?明年趋势又将如何?数据科学社区Analytics Vidhya对此进行了总结。
报告认为,2020年是巨大飞跃的一年。从OpenAI的GPT-3,再到AlphaFold,都是令人振奋的成就。与此同时,数据科学在机器学习、自然语言处理(NLP)、计算机视觉等领域中蓬勃发展。

一起来逐一盘点2020的哪些突破性的技术吧:
自然语言处理(NLP)
最大语言模型GPT-3
今年2月微软才发布全球最大的深度学习模型,拥有170亿参数的Turing NLP,几个月之后它就被GPT-3远远地超越了。
GPT-3是一个具有1750亿参数的自然语言深度学习模型,它还收集了Common Crawlhe和Wikipedia的数据集,数据集总量是之前发布的GPT-2的116倍,是迄今为止最大的训练模型。

作为GPT-2的升级版,它们功能上有什么异同呢?
虽然都是基于Transformer的,修改初始化、预规范化、可逆标记化性能也都是一样的。
但是T它们的ransformer类型不同,GPT-3使用了一种类似于稀疏Transformer的东西,在各层中运用了交替密集、局部带状的稀疏注意模式。
GPT-3还完美地弥补了BERT的两个不足之处,它既不用对领域内标记的数据过分依赖,也不会对领域数据分布过拟合。
这个强大的语言模型,不仅能够答题、翻译、算数、完成推理任务、替换同义词等。它还能够撰写新闻,写出来的新闻有理有据,难辨真假。
这么强大的GPT-3,普通的用户应该怎么使用?
OpenAI以付费的形式开放了API,只要通过一个“文本输入、文本输出”的接口,就可以访问他们的GPT-3模型。
它的相关论文入选了NeurIPS2020最佳论文。
论文地址:
https://arxiv.org/abs/2005.14165
项目地址:
https://github.com/openai/gpt-3
参考链接:
https://openai.com/blog/openai-api/
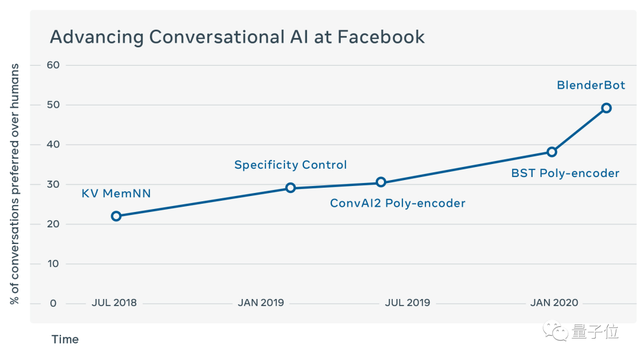
最大聊天机器人BlenderBot
BlenderBot是Facebook开源的94亿参数聊天机器人。

Facebook宣称,BlenderBot比Google的Meena更好,它是Facebook多年研究的成果,具有包括同情心、知识和个性在内的多种会话技巧的组合。
根据人类评估者的看法,BlenderBot在参与度方面优于其他模型,并且感觉更人性化。
这个聊天机器人包含94亿个参数,具有改进的解码技术,新颖的技能融合,是之前最大的聊天机器人系统的3.6倍。
官方博客:
https://ai.facebook.com/blog/state-of-the-art-open-source-chatbot/
项目地址:
https://parl.ai/projects/recipes/
计算机视觉
目标检测模型DETR
DETR是使用Transformer的端到端目标检测模型。
与传统的计算机视觉模型不同,DETR将目标检测问题作为NLP模型中的预测问题来解决。

Facebook声称DETR是“一种重要的目标检测和全景分割新方法”。它包括一个基于集合的全局损失,该损失使用二分匹配以及一个Transformer编码器-解码器体系结构来强制进行唯一的预测。
与以前的物体检测系统相比,DETR的体系结构完全不同。它是第一个成功集成Transformer作为检测pipeline的中心组建模块的目标检测框架。
DETR通过最先进的方法实现性能均衡,同时完全简化了体系结构。
官方博客:
https://ai.facebook.com/research/publications/end-to-end-object-detection-with-transformers
源代码:
https://github.com/facebookresearch/detr
语义分割模型FasterSEG
FasterSEG不仅有着出色的性能,也有着最快的速度。它是一个实时语义分割网络模型。
众所周知,语义分割可以精确到对图像的像素单位进行标注。
但随着时代发展,图像的分辨率越来越高。
这里,FasterSeg采用神经架构搜索(NAS)的方式,使之可以被应用到更新颖的、更广泛的搜索空间,解决不同分辨率的图像问题。
它还提出了一种解耦和细粒度的延迟正则化的处理方式,这种方法,在提高准确度的同时,也能够提高速率,从而缓解“架构崩溃”问题。
通过实验发现,FasterSeg在保持了准确度的同时,运行速度比Cityscapes快了30%多。

关于FasterSeg的论文被发表在ICLR 2020上。
论文地址:
https://arxiv.org/abs/1912.10917
项目地址:
https://github.com/VITA-Group/FasterSeg
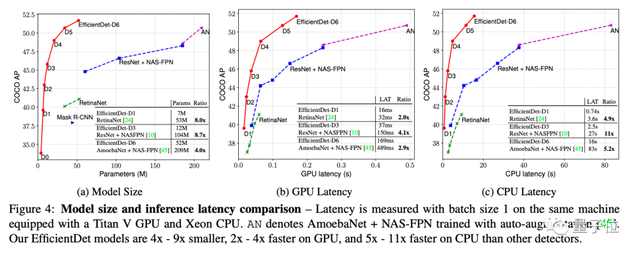
EfficientDet-D7
EfficientNet-D7主要用于CV领域上的边缘设备,使之更加高效便利。
它由谷歌基于AutoML开发,在COCO对象检测任务上达到了SOTA水平。
它需要的模型参数比同类产品少4-9倍,在GPU上的运行速度则比其他检测器快5-11倍。
其作者是来自谷歌大脑的工程师Mingxing Tan和首席科学家Quoc V. Le。
它的相关论文被CVPR 2020采用。
论文地址:
https://arxiv.org/abs/1911.09070
项目地址:
https://github.com/google/automl/tree/master/efficientdet
Detectron2
这项超强PyTorch目标检测库来自Facebook。
比起初代Detectron,它训练比之前更快,功能比之前更全,支持的模型也比之前前更丰富,还一度登上GitHub热榜第一。

实际上,Detectron2是对初代Detectron的完全重写:初代是在Caffe2里实现的,而为了更快地迭代模型设计和实验,Detectron2是在PyTorch里从零开始写成的。
并且,Detectron2实现了模块化,用户可以把自己定制的模块实现,加到一个目标检测系统的任何部分里去。
这意味着许多的新研究,都能用几百行代码写成,并且可以把新实现的部分,跟核心Detectron2库完全分开。
Detectron2在一代所有可用模型的基础上(Faster R-CNN,Mask R-CNN,RetinaNet,DensePose),还加入了了Cascade R-NN,Panoptic FPN,以及TensorMask等新模型。
开源地址:
https://github.com/facebookresearch/detectron2
DeepMind的AlphaFold解决蛋白质折叠问题
谷歌旗下人工智能技术公司 DeepMind 提出的深度学习算法「AlphaFold」,破解了困扰生物学家五十年之久的蛋白质分子折叠问题。
AlphaFold还能够准确判断出蛋白质结构中的哪一个部分更重要。
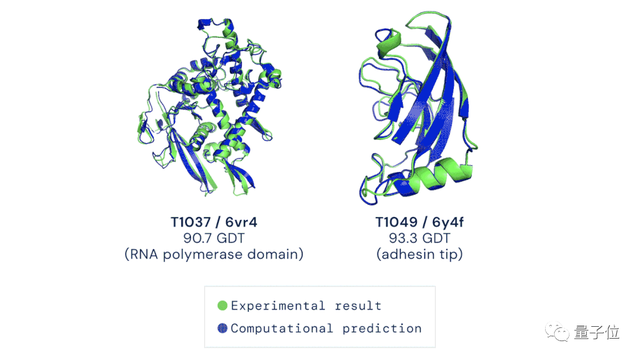
Nature、Science争先报道这项科技成果,科技大佬们也纷纷发来贺电。
Alphafold实现了在生物学上的重大突破,成为了CV和ML领域的里程碑,被称作是:“生物界的ImageNet时刻”。
在这个算法中,科学家将蛋白质的折叠形状看作一个“空间图”,用残基(residue)来表示它们之间的节点。由此创建了一个注意神经网络系统,进行端与端之间的训练,探索出蛋白质的具体结构。
为了训练好这个算法,Alphafold采用了具有17万个蛋白质结构的数据库,使用约128个 TPUv3 内核(相当于 100-200 个 GPU)运行数周,算法的效率较高。
这项研究成果的影响深远。哥伦比亚生物学家Mohammed AlQuraishi 在 Nature 文章中说道:
这对蛋白质结构预测领域影响深大,是一流的科学突破,也是我毕生追求的科学成果。
开源代码:
https://github.com/deepmind/deepmind-research/tree/master/alphafold_casp13
论文地址:
https://www.biorxiv.org/content/10.1101/846279v1.full.pdf
强化学习
Agent57得分高于人类baseline
Agent57是由DeepMind开发的,在Atari测试集中的2600场游戏比赛中,它的成绩都高于人类平均水平。

它还创造了57种不同的Atari视频游戏的评估机制。由于这些评估机制要求RL智能体要掌握的东西太多了,因此,很少有RL算法能够实现。
Agent57在其Arcade学习环境中(ALE)环境中采用了RL、模型学习、基于模型的训练、模仿学习、迁移学习和内推力等一系列方法。
它提供的Atari2600游戏环境接口,使人类玩家能接受更丰富的人机挑战。
在游戏方面,Agent57毋庸置疑成为最强的RL智能体。
其研究论文发表在了《人工智能研究杂志》上。
论文地址:
https://arxiv.org/abs/1207.4708f
机器学习运维兴起
MLOps(Machine learining Operations)是数据科学领域中一个相对较新的概念。类似于DevOps(Development和Operations组合词),简单来说,就是机器学习方面的DevOps。
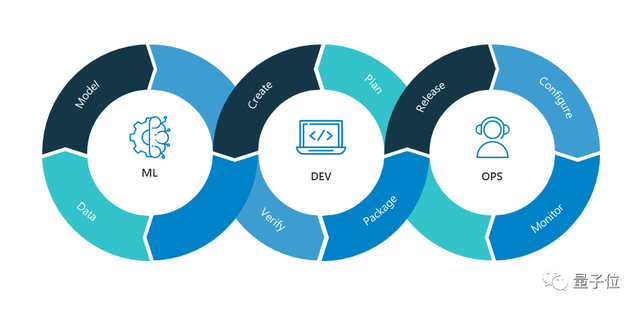
如果说DevOps是为IT开发者服务,解决了开发者将项目交给IT运营部门实施和维护的问题。
那么,MLOps就为数据科学家、ML工程师提供服务,使他们转向协同工作,提高工作效率。
它拥有一套完整的行为策略方式,用来解决ML和AI在运行周期内遇到的各种问题。
在增长最快的GitHub项目Top-20中有5个是机器学习运维工具。
这表明整个AI行业正在从“如何开发模型”转向“如何运维模型”的趋势。
参考链接:
https://nealanalytics.com/expertise/mlops/
开源地址:
https://github.com/microsoft/MLOps
AI对抗新冠病毒
世界卫生组织列出了对抗新冠病毒的9大研究方向。
美国白宫邀请Kaggle参与其中,发起NLP挑战,找到这9大关键问题的答案。
在Kaggle上,包含20万篇学术文章的新冠数据集,免费提供给世界各地的NLP研究和AI研究,希望全世界AI学者,能够科技手段,促进解决新冠病毒问题。
数据集由白宫科学技术政策办公室协调策划,艾伦AI研究所、扎克伯格基金会、乔治城大学安全与新兴技术中心、微软研究院、IBM等多家科技巨头都有参与贡献。

Kaggle还发动了一个预测比赛。预测全球不同地区感染新冠肺炎、死亡人数等。并且将预测的数据与实际数据对比,形成一个数据预测模型。
假如预测模型足够好,就可以缓解新冠肺炎带来的医疗资源稀缺问题。
新冠病毒九大研究方向:
https://www.who.int/blueprint/priority-diseases/key-action/Global_Research_Forum_FINAL_VERSION_for_web_14_feb_2020.pdf?ua=1
新冠数据集:
https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/
展望2021年的机器学习
从NLP到计算机视觉,在从强化学习到机器学习运维。所有人见证了AI领域的进步,也期待AI能够为全球疫情提供力量。
科技仍在进步,2021年又会发生什么样的变化呢?
Analytics Vidhya预测了一下2021年的一些关键趋势:
1、2021年数据科学领域的工作机会将继续增加。因为数据爆炸和消费习惯的改变,数据科学将会扮演越来越重要角色。同时,传统的制造业、采矿业也需要对数据进行分析。
2、Facebook的PyTorch使用率将超过Google的TensorFlow。机器学习框架之战有两个主要竞争者:PyTorch和TensorFlow。分析表明,研究人员正在逐渐放弃TensorFlow,大量使用PyTorch。
3、Python在2021年将更加流行。毋庸置疑,Python是当前最受欢迎的语言。为了巩固它的地位,在10月时候,它推出了Python 3.9,提升性能。目前,Python 3.10现在正在开发中,预计2021年初发布。
4、基于前疫情时代数据的模型有效性将下降。疫情导致全球的消费习惯发生了改变,前疫情时代的数据模型有效性在逐渐下降。在后疫情时代,谁能抓住这些新的消费模式特征,谁就能取得成功。
5、数据市场将持续上升。新冠疫情改变了全球的消费行为和市场游戏规则,这意味着多样化、全新的数据集正在产生,将创造更大的价值。
- 光子计算加快AI运算速度,Nature连登两篇论文2021-01-07
- 地平线 C2 轮融资 4 亿美元,C 轮已经完成 5.5 亿美元2021-01-07
- 英伟达400亿美元收购ARM要泡汤?英国出手调查了,结果未知2021-01-07
- 爱奇艺奇遇VR将发布新品奇遇3,带追光技术,可对标Oculus Quest22021-01-06











