我用AI分析了《赛博朋克 2077》的评价,发现真爱粉都是来吸猫的
「差评,退款」
贾浩楠 萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
CDPR三度延期《赛博朋克 2077》,可把玩家憋坏了。

12月10日上线当天,网上一夜间流行起各种赛博朋克的梗:

前期预售800万份,上线首日就收回成本,3天时间就有17万留言评价…..
尽管CDPR不给游戏加密,默许盗版,但绝大部分玩家毫不介意为《2077》掏钱。
从来没有哪家厂商能像「波兰蠢驴」这样被玩家拥戴。

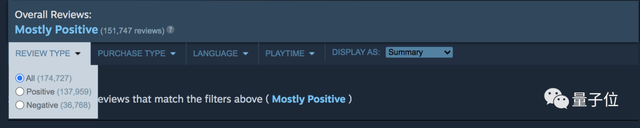
但是,《赛博朋克 2077》刚上线,按照Steam的评分规则,得到了「多半好评」。
好评率仅有73%,今天也只达到79%。
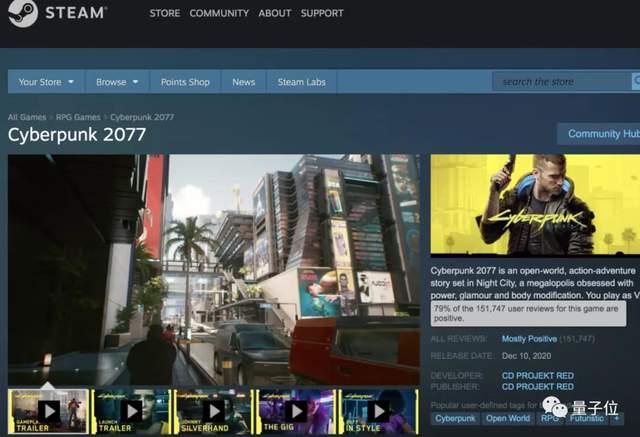
分数不低,但对于有《巫师》系列在前的CDPR来说,这个成绩还是有些意外。
谁在给《赛博朋克 2077》差评?大家在吐槽什么?
一位最硬核玩家Kamil Czarnogórski,用AI分析了Steam上的评价,看看大家在讨论《赛博朋克2077》的时候,都在说什么。
《赛博朋克 2077》,你还好吗?
Kamil使用Transformer,对抓取的Steam评论页有效信息进行向量化,并使用UAMP来对数据进行可视化,最后用k均值算法对关键词进行聚类分析,得出了下面的结果。
先看吐槽部分。《赛博朋克 2077》,对于玩家吐槽最多、给出差评最集中的两个点,一是配置要求高、二是游戏优化差、bug多。
在配置方面,出现频率最高的词汇是游戏硬件配置相关,比如RTX、1080P、DLSS等等。

一波高配置玩家,秀了一把流畅运行的配置清单:
RTX2060、i7 8700、16GB内存 ,感觉画面就像一部电影。
45-65帧,RTX 2080、i9-9900K与32GB的内存,光追效果全开,运行流畅。
2080ti和9700k没有问题,可以开最高画质,帧率稳定60帧。
3080 FE和5800X,可以达到到80-100帧率,分辨率1440p,其他设置都是最高。
可以看出,要想较为流畅地运行《赛博朋克2077》,一块2060或更好的N卡是必须的。
目前,2060国内电商售价在2500-3000左右,而2060只能算将将满足最高画质要求,要想玩的「从容」,还得更高配置。
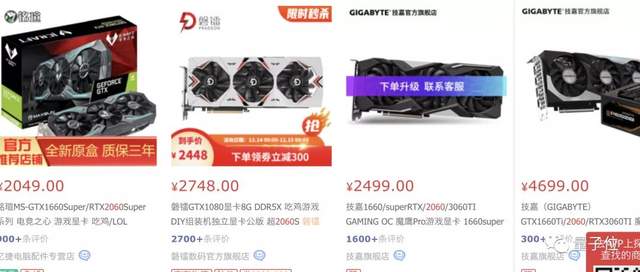
加上i7 8700处理器,要开最高画质玩《赛博朋克2077》,整套设备至少8000-10000元起步。

原来第一时间阻止我们玩《赛博朋克2077》的不是工作\学业,而是钱。

有了真金白银,攒起了高配置电脑,但游戏的bug和崩溃情况还是令人头疼。
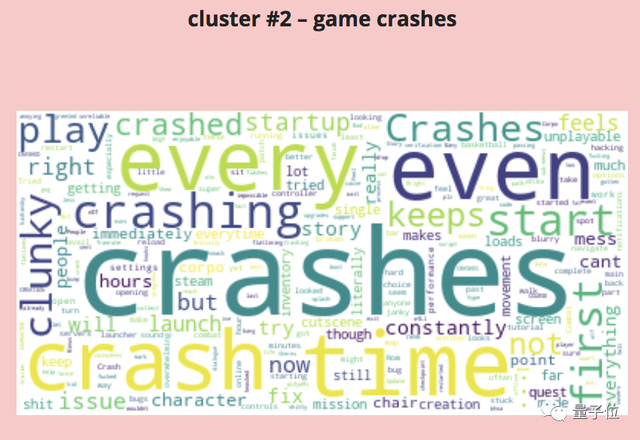
吐槽出现频率最多的词是崩溃(crashes),且玩家反映,崩溃情况多数出现在启动时、角色创建,以及镜头转场,比如过场动画和玩家视角的衔接。
其它小bug也频频出现。一位名叫staigerd89的玩家分享说,他的角色一直被一个特定NPC不明原因尾随:
崩溃和各种小bug,是目前这款游戏被吐槽最多的情况。
此外,有大量玩家反映,主机平台优化太差,远不如PC。

甚至有真爱粉先买了主机版,发现效果不好后,又花钱买了PC版。
在游戏性方面,玩家也提到打击和射击感比较生涩和迟滞,子弹打在物体上力量不突出,像是打海绵一样。
不可避免的,负面评价中另一个高频词是退款。
尽管被大量吐槽,但游戏本身精良的画面,和用心的制作细节还是让大家对它充满了期待。
给出差评的玩家,大部分认为目前的问题不影响整体质量,未来随着版本更新、bug修复,优化会越来越好。
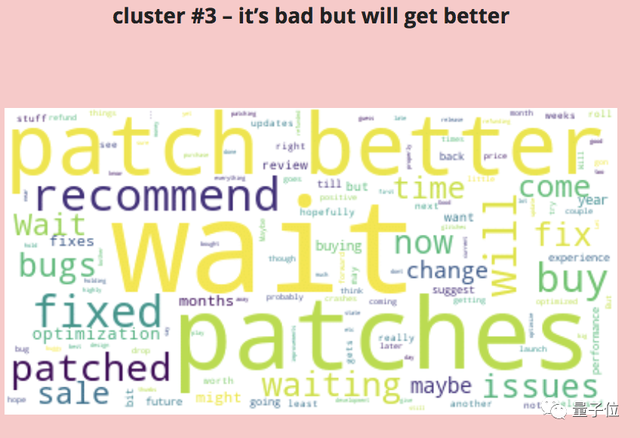
这一类评价中,出现最多的词是wait、patch、better。
「波兰蠢驴」向来不在意盗版传播,也不给游戏加密,因为总有真爱粉支持正版。大家对CDPR的耐心和期待,也远超其它游戏厂商。
而且,游戏上线一天后,英伟达方面也立刻更新460.79版驱动,针对《赛博朋克 2077》做了全方位的支持和优化,几天下来,好评率从73%上升到79%。
好评最多:撸猫
「配置要求高」、「前期bug多」、「感谢Steam给我退款」……《赛博朋克 2077》,你还好吗?
其实,仍然有多数玩家给出了好评。
好评中出现最多词汇,竟然是撸猫(petting the cats)。
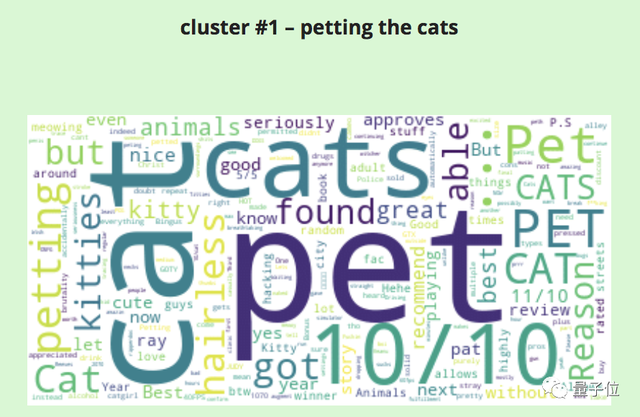
大家纷纷表示,这是年度最佳撸猫游戏。

此外,玩家赞誉的点集中在画面效果好、游戏世界细节到位、夜城沉浸感强。

所以总的来说,《赛博朋克 2077》细节还不完善,前期bug较多,会出现崩溃。
但总体制作精良,未来更新令人期待。
3步走,用AI解析Steam评论
那么,从「优化」、「退款」到「撸猫」,这些精准的关键词分析结果,Kamil是怎么得出的呢?
数据处理
首先,获取上面这些(吐槽、撸猫等)评论的文本数据。
Steam有一套游戏的配置工具包Steamworks,其中一项功能是获取Steam游戏的评测,可以筛选时间、语言、正负面评价等,每次获取20条。

只需要写个Python脚本,就能迭代获取《赛博朋克2077》的所有英文评论。
这些评论是一组组句子,接下来要将它们切分成token(字,包括单词和标点符号),用NLP的Python工具包NLTK,通过sent_tokenlize对所有句子进行字词分割。

在那之后,再对输入进行向量化 (embedding),这里用到的框架是Sentence Transformers(BERT和XLNet结合的多语言句子向量框架)。
分析数据的目的,是为了寻找句子的语义相似度,因此采用了框架中的预训练模型roberta-large-nli-stsb-mean-tokens。
这里的语义相似度,就是将相似的句子聚集在一起的关键,例如这些吸猫评论:

用这种模型对数据进行处理后,就能将输入的评论转换为高维向量(便于聚类分析)。
数据可视化
接下来,是将这些向量可视化,更好地看清评论的分布。
但经过Transformer获得的高维向量,还不能直接可视化。
因此,需要将这些1024维向量(转换出来的高维向量,是将语义编码成1024个数字的序列),先降维成二维向量。
这里会用到一种名为UMAP (统一流形逼近和投影)的技术,能将高维向量转变成二维向量。
在二维向量的可视化图中,彼此接近的点表示具有相似含义的句子,如果发生簇分离,则代表评价的内容并不相同。
如下图,经过处理后的可视化评论中,绿色代表正面评价,红色代表负面评价,颜色越深,表示负面评价的占比越大。(例如上面那些有关退款的评价,就可以组成一个退款群了)
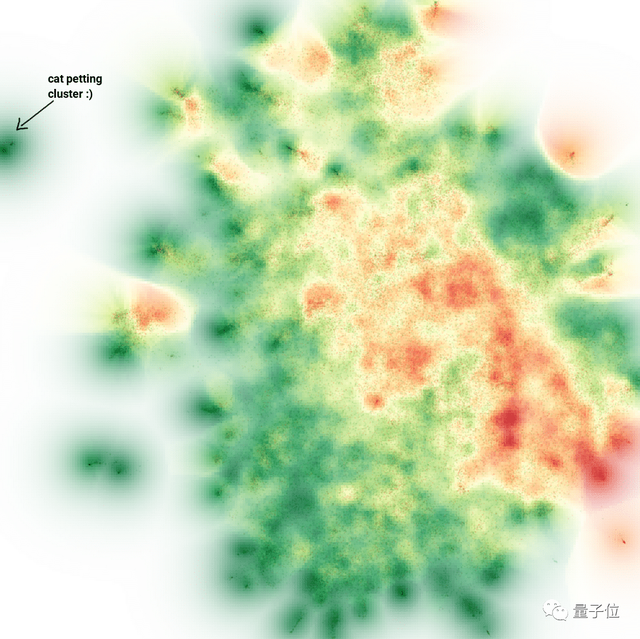
而在离集群很远的左上角,有一小撮人在“自说自话”,这群人给出的140条评价,全都是好评。
没错,这就是刚刚那群沉迷吸猫的玩家……(毕竟,连水下也能吸猫)

当然,快乐吸猫只是游戏中的一个细节。
为了更全面地搜集有关游戏的整体评价,还需要对这些数据进行聚类分析。
聚类分析
聚类分析,是对评价进行整体分类的方法,也就是对这些处理后的二维向量进行分组。
例如被分到「游戏会更好」的评价组里,就会看到大量的wait、patch、better,这些词共同组成了这个评价。
这里的聚类分析,采用的是k均值算法 (k-means)。
k均值算法唯一需要的参数是簇数(将这些二维向量分成多少组),这里盲猜75。
簇数越大,分类就越细,反之则越普遍。运用k均值算法后的75个分类如下:
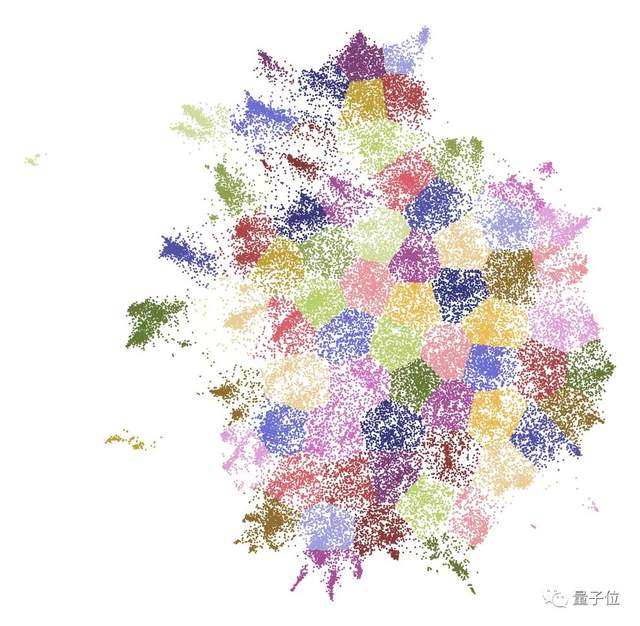
其中,每一簇都会有一个质心 (centroid),是一句最能代表集群的“虚构”的话。
为了做出像上面评价那样的可视化关键词,会在簇中选取与质心最接近的句子,并分析句子作者的游玩时间:
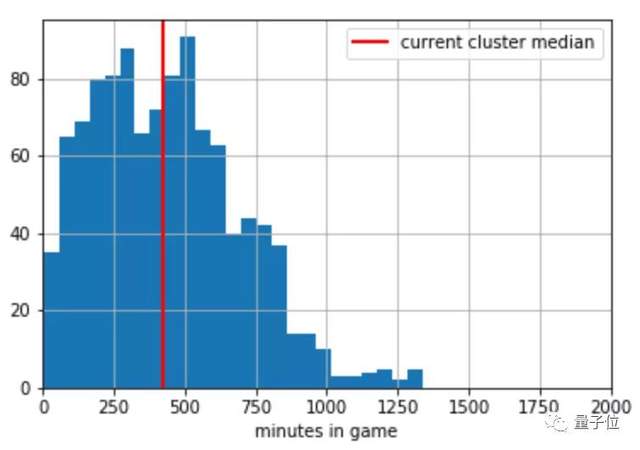
在那之后,会将分析后的字词进行可视化:

至此,就完成了对《赛博朋克2077》Steam上评论的分析。
这次筛选出来的的评论,主要是作者精选的15类评论,包括5个讨论最多的话题、5个评价最高的话题和5个评价最低的话题。
如果你还有更好的分类方法的话,可以自己上手操作起来了~
作者介绍

Kamil Czarnogórski,毕业于格但斯克大学(University of Gdańsk)计算机科学系,这是一个位于波兰的大学。
《赛博朋克2077》的开发商CDPR也来自波兰。
Kamil Czarnogórski表示,这次做的评论分析,只针对发行后的24小时内的游戏评价。
在他进行分析的这段时间里,Steam上对于《2077》的评价已经上涨到了80%,截至12月14日,有关《2077》的评价已经达到了81%。

当然,游戏具体如何,还得亲自一试。
目前这位小哥已经上手了这款游戏,打算给出自己的见解。
你已经玩了《赛博朋克2077》吗?
「波兰蠢驴」的新作品满足你的期待吗?
欢迎留言告诉我们~
参考链接:
https://github.com/UKPLab/sentence-transformers
https://partner.steamgames.com/doc/store/getreviews
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07
相关阅读