
嬴彻科技拿下SemanticKITTI榜单两项第一
SemanticKITTI是激光雷达语义分割的重要基准之一
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
在感知算法领域,嬴彻科技近期凭借「精准语义分割3D感知技术」,在SemanticKITTI 的「语义分割」和「全景语义分割」两项任务中夺得第一,领先于来自MIT、芝加哥大学、阿里、华为等全球各地的100多支队伍。
语义分割是自动驾驶感知算法的关键技术,能识别出各种场景物体,告诉汽车“身边有什么危险”,从而保障出行安全。
KITTI是目前发布最早、影响力最大的自动驾驶算法评测数据集。
SemanticKITTI是KITTI在语义分割方向的子数据集,是激光雷达语义分割的重要基准之一。为了推动激光雷达的语义分割研究,SemanticKITTI举办了3D语义分割比赛,包括「语义分割」和「全景语义分割」等任务。
任务一 「语义分割」,要求能准确识别出场景中的物体类型(如汽车、行人);任务二 「全景语义分割」,要求对场景中的所有物体都进行精确个体级辨识,即类型基础上,为每个物体赋予1个ID(如1号车、2号车……)。
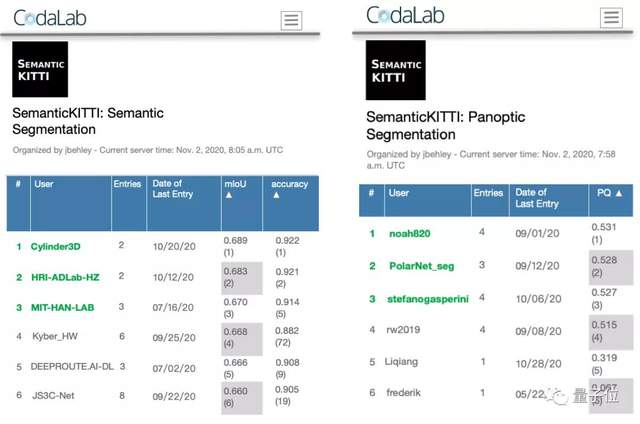
△ 榜首的Cylinder3D & noah820为来自嬴彻科技的两支参赛团队
相较于传统的激光雷达语义分割算法,嬴彻这次做出了哪些突破?来自嬴彻Inceptio X-Lab的李伟博士,与量子位详细分享了其中的技术原理。
1、从“划井字”到“切蛋糕”, 使点云分割更均衡
在点云分割上,算法实现了「圆柱坐标系下的体素划分」。
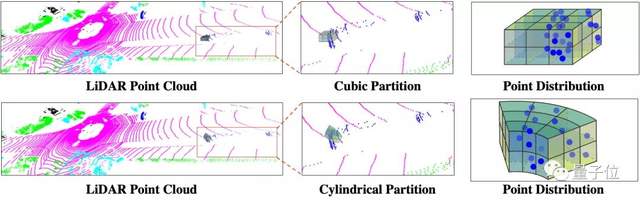
李伟博士用“划井字”和“切蛋糕”,对这一突破进行了类比。传统激光雷达点云的分割方法,就像是正正经经划“井”字一样,将空间划成多个方块,但是单个体素块内的点云就会出现近多远少、分布不均衡的问题;
那么,“圆柱坐标系下的体素划分”,就是从激光雷达扇形扫描的特性出发,即更加符合点云数据的分布特点,以“切蛋糕”的方式进行分区。近处密集的点,单元划分空间也小;远处稀疏的点,单元划分空间就更大,体素块内点云更均匀。
2、“核骨架增强”,揭开半遮半掩的面纱
做目标检测的小伙伴们都有过这样的经历:一个完整的物体,AI通常都能检测出来。
然而如果这个物体“遮遮掩掩”,检测效果就大打折扣。
通过识别这个物体的核骨架(skeleton of the kernel),就能够拨开面纱检测出物体。

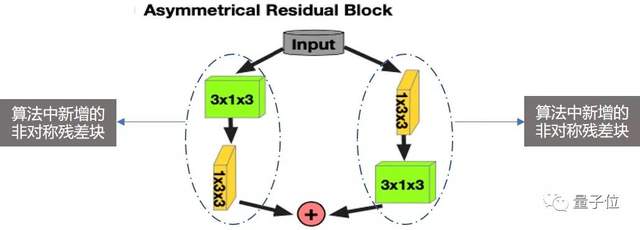
为达到这个目的,在数据处理的部分,算法中新增了「非对称3维神经网络模块」。
这一模块,在水平和垂直两个方向分别增强卷积核,能更好地匹配驾驶场景下的物体形状分布,从多角度更全面地看到每个点云的状态,即使在遮挡或是稀疏点云输入的情况下,也能准确地辨别物体。
3、从单一划区到块点结合,精细区分小物体
区块检测是目前常用的方法,缺点是不同类别的点云有可能被划分到一个体素块内,物体分割的细节容易丢失,准确性降低。
嬴彻在划区的基础上,再进行「单个三维点云级别的分割」,获得精细细节。如下图所示,嬴彻的方法有效在一个小区域中继续精确分割出更小的物体。
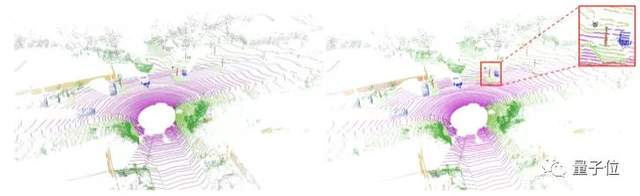
块点结合检测的效果,不仅辨识精度更高,且更易于小物体的识别,极大地提升了高速行车的安全性。
嬴彻此次发布的「精准语义分割3D感知技术」,基于激光雷达的感知算法,与纯摄像头方案形成双重冗余,满足在多场景下、尤其是夜晚的感知需求。
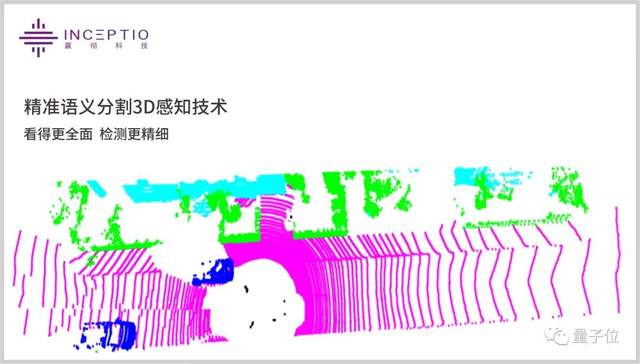
此外,这一算法还能更鲁棒、更及时的感知高速公路上突发遇到的小物体,如突然蹿出的小动物,从而更及时做出路径规划,确保高速行车安全。
比赛链接:
https://competitions.codalab.org/competitions/24025#results
https://competitions.codalab.org/competitions/20331#results
http://www.semantic-kitti.org/
paper链接:
https://arxiv.org/abs/2011.10033
https://arxiv.org/abs/2011.11964
code链接:
https://github.com/xinge008/Cylinder3D
- 首个GPT-4驱动的人形机器人!无需编程+零样本学习,还可根据口头反馈调整行为2023-12-13
- IDC霍锦洁:AI PC将颠覆性变革PC产业2023-12-08
- AI视觉字谜爆火!梦露转180°秒变爱因斯坦,英伟达高级AI科学家:近期最酷的扩散模型2023-12-03
- 苹果大模型最大动作:开源M芯专用ML框架,能跑70亿大模型2023-12-07











