华人小哥控诉机器学习「四大Boring」,CS博士:深有同感,正打算退学
Reddit热度500+
杨净 发自 凹非寺
量子位 报道 | 公众号 QbitAI
机器学习很无聊。
至少这位铁汁是这样认为得。
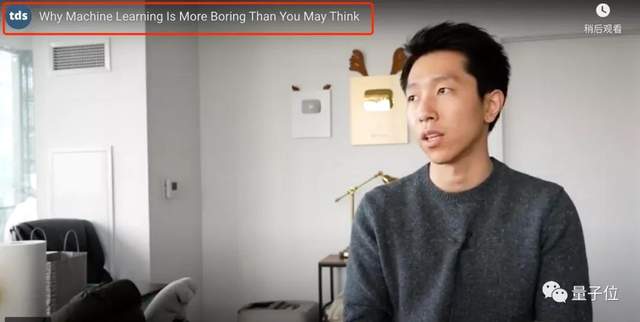
甚至还在Reddit上发了帖子,标题就直接这么明晃晃写道:
Why machine learning is more boring than you may think?
结果不到15个小时,便引起了500+热度的讨论。
对此,有网友认为,「因为它是工程技术,而不是基础研究,工程需要满足最低标准和最后期限的,技术上没有什么挑战性」。

而至于为何要如此强调「Boring」,这位数据科学家肖安讲了如下原因,也给出了自己的解决方式。
机器学习「四大Boring」
首先是设计 (Designing)的部分,占据5%-10%的时间。
这时候是群策群力、迸发新想法的时候,包括新的模型体系结构、数据功能和系统设计等。
预期的情况是,在每个项目中应用最新和最出色的算法,可以在知名顶会期刊发布的那种。
但实际情况是,由于「时间限制」和其他优先级事项,只能做到最简单、有效的算法。

这时候,为了满足作者的「成就感」,就会在附带项目中进行一些「疯狂」的想法,即使这些想法根本不起作用。
接着是编码 (Coding )的部分,根据项目的不同,20%到70%的时间占比。
代码通常分为五类:占代码总行数的百分比。
- 数据管道,50-70%;
- 系统和集成事物,10–20%;
- ML模型:5–10%;
- 支持调试和演示分析,5–10%;
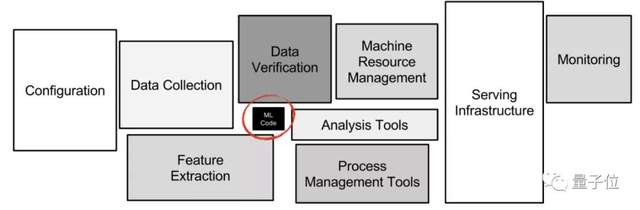
预期的场景是,花费大量的时间在编码ML组件。
但现在已经有很多现成的框架和编码语言,将很多复杂的东西抽象化,这样工作流已经十分标准化了,根本不需要去开发和完善ML组件。
既然如此,工程师则将更多的时间花在其他低级的优化上,比如系统、数据管道等。
然后是质量检查、调试、修复 (Debug),至少要花65%的时间。(感受到了作者的怨念)
一般主要有两种错误,不良结果和传统软件问题。
不良结果,就是模型效果不好、评分较低(比如准确性)。
传统软件问题,就包括系统损坏、系统配置问题。
理想的状态,是只需要处理「不良结果」,然后去构建更好的模型。
嗯,展现才能的时间到了!

然而现实情况是,大概70%-90%都是「传统软件」问题。
而至于不良结果,通常在构建端到端模型训练和数据管道之后,就可以的很快获得很好的结果了。
最后一个部分,就是「灭火」(Fire-fighting),处理各种意外情况。
这大概是所有工程师都不愿意看到的点了吧。
在整个交付过程中,不管是外部、甲方爸爸的要求还是内部沟通不畅、能力不足等各种人为Bug,用作者的话来讲,「就是一场噩梦」。
这时候,除了保持微笑之外,建议将时间轴延长到2-3倍,在团队里积极交流。
害,说到这里,归根结底就是理想与现实之间的差距,别人以为的和你自己正在干的区别。
比如,就像这样。

最后,这位小哥还是注入了一些安慰剂。
就像从事任何职业一样,最终都会感到无聊和沮丧。
但是没关系,很正常。你应该开发一种应对机制,像玩游戏一样,在过程中获得一些小奖励,然后最终获得胜利。
网友怎么看?
对于这件事,网友们倒是意见各异。
有学CS学了6年的博士生自述了所遇到的迷茫,并表示打算放弃现在的博士学位。
我期望它是酷炫的、知识性、算法性的东西,但一直没有等到可大展拳脚的工程/调试类项目。
因为这个原因,我打算退学。虽然现在还不清楚该申请什么样的工作。
但有人觉得,作者所说的几个Boring,恰好是喜欢当ML工程师的原因。
还给出建议:如果你想花费100%的时间用来构建和调试ML模型,那你应该去看看研究岗,而不是工程岗。
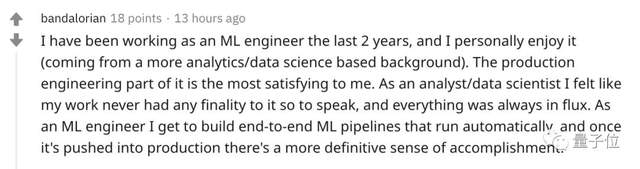
还有网友表示,自己很喜欢ML工程师的工作,从构建自运行的端到端模型,到正式投入生产,会有很强烈的成就感。
也有人形象地比喻了理想与现实:

那么,对于这件事你怎么看?如果你的身边也有类似的经历,欢迎与我们分享~
参考链接:
https://towardsdatascience.com/data-science-is-boring-1d43473e353e
https://www.reddit.com/r/MachineLearning/comments/jvq4jw/d_why_machine_learning_is_more_boring_than_you/
- 人人可用的超级智能体!100+MCP工具随便选,爬虫小红书效果惊艳2025-04-29
- 当购物用上大模型!阿里妈妈首发世界知识大模型,破解推荐难题2025-05-01
- OceanBase全员信:全面拥抱AI,打造AI时代的数据底座2025-04-27
- 网易有道张艺:AI教育的规模化落地,以C端应用反推大模型发展2025-04-27