阿里公开核心技术:如何摘下4项世界冠军,推理性能比第二名快5倍
文 | 阿里云异构计算团队
量子位 出品 | 公众号 QbitAI
近日,斯坦福大学DAWNBench ImageNet最新成绩公布,阿里超过Google、Facebook等,摘下四个榜单的世界第一。
128卡V100上,训练ResNet50,只需要158秒就能获得top5 93%的精度。
在10000张图片的验证集进行图片分类,top5精度不低于93%,推理性能比第二名快5倍以上。
可以说,不论是训练的性能和成本,还是推理的性能和成本,都体现出阿里在异构计算领域具有世界级AI软硬件一体化极致性能优化能力。
阿里是如何做到的?四项冠军得主——阿里云异构计算团队分享了背后的技术秘密。
这是一个什么样的成绩?
斯坦福的DAWNBench,是一个端到端的深度学习模型训练和推理性能的基准测试平台,由斯坦福大学在2017的NIPS会议上发布,之后得到业界广泛支持。
Google、Facebook和VMWARE等世界知名公司先后加入。DAWNBench已成为人工智能领域最具影响力、最权威的排行榜单之一。
对于AI计算而言,最重要的两个指标是性能和成本。最新的成绩公布后,显示了阿里云在训练和推理领域软硬件一体化世界级性能优化能力。
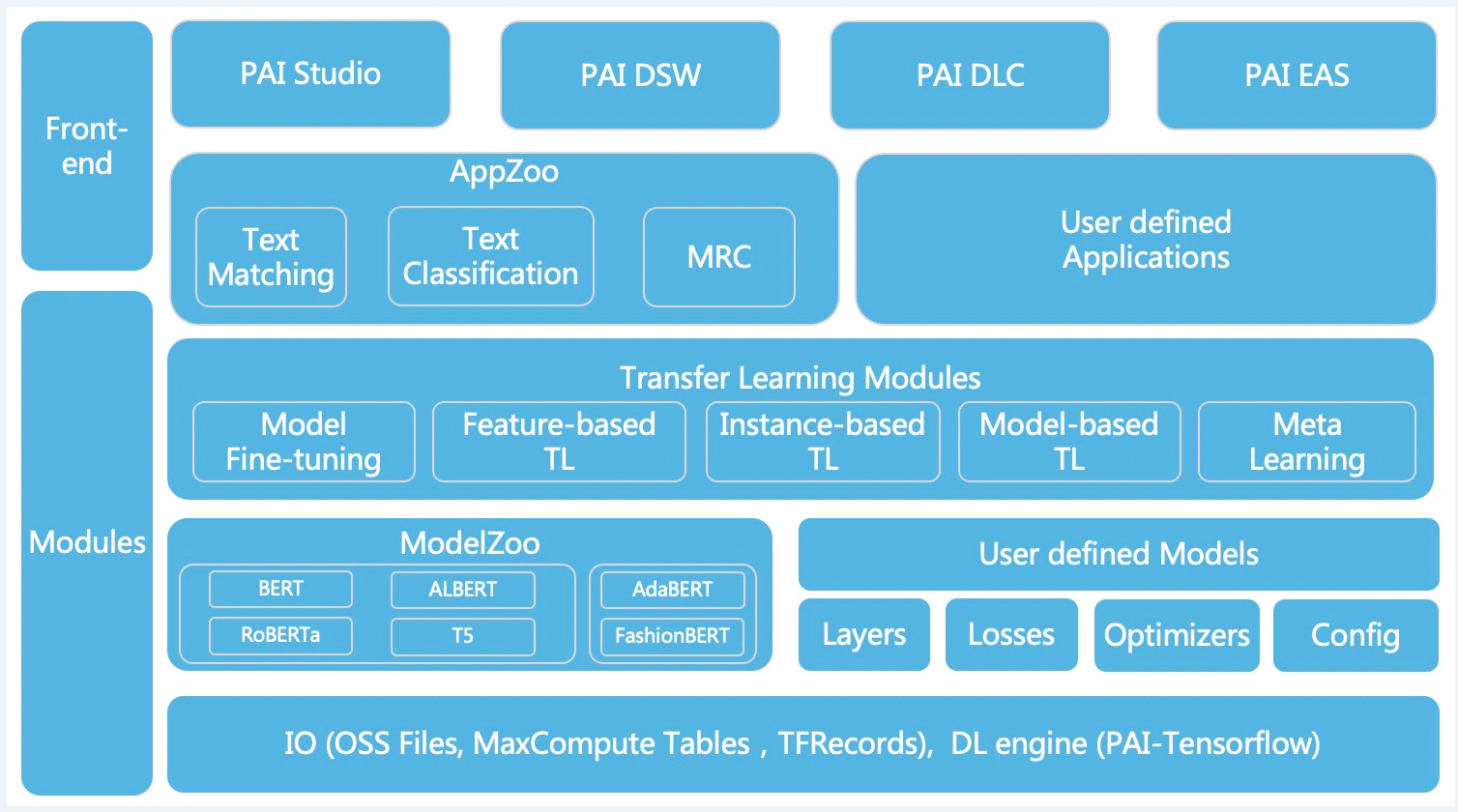
阿里云异构计算AI加速团队透露,最重要的武器是阿里云自研的飞天AI加速引擎AIACC、阿里云自研芯片含光800(简称AliNPU)以及阿里云异构计算云服务。
AIACC是阿里云自研的AI加速引擎,是业界首次统一加速Tensorflow、PyTorch、MxNet、Caffe、Kaldi等AI主流计算框架的加速引擎,其中包括训练加速引擎AIACC-Training和推理加速引擎AIACC-Inference。
训练加速引擎针对分布式的网络做了性能优化,能够充分发挥分布式网络的通信能力,推理加速引擎针对阿里云异构计算云服务(包括GPU云服务和NPU云服务)做了针对性深度的性能优化,能够发挥异构加速设备的计算能力。
以NVidia GPU为例,目前业界最快的推理引擎是TensorRT,而AIACC-Inference的计算性能比TensorRT还能获得1.5~2.5倍的性能加速比。
含光800是阿里巴巴第一颗自研AI芯片,也是全球性能最强的AI推理芯片,主要用于云端视觉处理场景,性能打破了现有AI芯片记录,性能及能效比全球第一。
在业界标准的ResNet-50测试中,含光800推理性能达到78563 IPS,比目前业界最好的AI芯片性能高4倍;能效比500 IPS/W,是第二名的3.3倍,而AIACC-Inference也能够充分挥发含光800超高的计算能力,这是阿里云软硬件一体化极致性能优化的典范。
阿里云异构计算云服务将GPU、FPGA、NPU等异构计算设备整合,通过云计算服务的方式对客户提供异构计算服务。
随着人工智能浪潮的兴起,越来越多的AI计算都采用异构计算来实现性能加速,而阿里云异构计算服务,构建于云上最丰富的加速实例基础之上,通过AIACC的算力提升,为AI计算提供普惠、弹性和触手可得的加速计算云服务。
刷新ImageNet上ResNet50的训练记录
在图像识别领域,最具代表性的场景是ResNet50在ImageNet上的训练。
最新公布的榜单上,AIACC-Training成为此场景下的性能与成本的世界双项第一,展示了在分布式训练领域AIACC处于国际领先水平,能够帮助用户提升训练性能的同时降低所需的计算成本。
训练性能榜单新的世界纪录,运行在128张V100(16台异构计算云服务实例ecs.gn6e-c12g1.24xlarge)的集群之上,网络通信为32G VPC,训练ResNet50 至top5精度达到93%时间为2分38秒。
此前的世界纪录所采用的集群规模也是128张V100,网络通信则为100G InfiniBand网络,是本次打破世界纪录的32G VPC的3倍的带宽。异构计算云服务的典型网络配置为32Gbps带宽的VPC网络,为了更贴近最终用户的场景,阿里选择的是VPC网络。
32G VPC网络与前世界纪录的网络物理带宽上的巨大差距是团队面临的重大挑战,我们从两个大的方向作了深入的优化:
第一个方向是从模型本身的优化上,进行超参的调整以及optimizer的改进,减少达到93%精度情况下所需要进行的迭代数,同时也要尽力提升单机的性能。
第二个方向是分布式性能优化,我们采用团队自研的飞天AI加速引擎AIACC-Training(原Ali-Perseus-Training)作为分布式的通信库,充分挖掘32G VPC的所有潜力。
最终两个方向的极致优化相叠加,超越了一个看似不可能达到的性能屏障,以较低的网络带宽,创造了新的世界纪录。
同时,因为分布式训练部署本身的复杂性,为了提高效率,也为了方便外部用户重现结果,阿里团队使用了之前开发的即刻构建的工具FastGPU,将集群的创建和分布式训练的调度全部以脚本的方式完成,可以一键启动,大大加快了优化工作的效率。
未来,我们会开源基于AIACC的benchmark代码,方便外部用户一键复现结果。
分布式训练领域近年来发展迅猛,有多种可供选择的解决方案,对于Tensorflow 而言,框架本身支持PS模式以及Ring allreduce风格的分布式通信,第三方的支持有Horovod。
对于ResNet50的分布式训练,开源方案中Horovod依然是相对最优的解决方案,因此,阿里以Horovod作为对比的baseline。
分布式训练的逻辑框图如下图所示:
最小计算节点为单张GPU卡,每个计算节点都会从总的数据集中划分一份数据作为本节点的训练数据,然后开始前向和后向的计算,在后向计算结束后会得到当前batch所产生的梯度。
然后在更新参数之前,需要在整个集群上进行梯度通信。Horovod API就是在梯度更新之前,在optimizer这个环节插入了一段多节点间的通信的流程。
AIACC-Training
AIACC-Training是阿里云自研的深度学习分布式训练通信引擎,统一支持Tensorflow、PyTorch、MxNet和Caffe,从IaaS层面提供可被集成且兼容开源的加速库。
现在已经有多家AI和互联网客户在生产环境中大量部署使用,显著提升异构计算产品的性价比,从软件层面为客户提供差异化的计算服务,架构如下图所示。
AIACC-Training 作为此次Dawnbench 记录的分布式后端,发挥了至关重要的作用。以下是我们对AIACC-Training背后的分布式优化作详细的解析。
去中心化梯度协商
分布式性能的关键就是如何优化这个通信环节的效率,对于ResNet50而言,我们需要通信的梯度数据大约是170个,而通信的总量大约是50MB。
这些梯度的产生时机依赖于它们各自在计算图中的位置,计算图中存在依赖关系的部分梯度决定了这一部分梯度被计算出来的时间先后顺序。
而在计算图中处于相互之间完全无依赖的算子的,它们在每次计算发生的时机具有一定的随机性。在多节点间通信要解决的第一个问题就是需要协商梯度的同步顺序。
Horovod中所采用的的方法是以0号节点为中心,与所有其它节点进行点对点的通信确定当前所有节点上都已经就绪的梯度,然后再0号节点上确定这些就绪梯度上如何去通信,最后将通信策略点对点的发送到每一个其它节点,之后根据通信策略开始进行多机通信。
这一点对点的协商策略,在128节点下,对0号节点,造成了一个局部的热点,需要通信256次。AIACC-Training 放弃了这种中心节点的协商模式,转而采用了去中心化的方式在128个节点间进行协商,因为128个节点实际分布在16台实例中,我们的优化可以轻易的识别这种拓扑结构,不再会在任何单个GPU卡上产生256次通信热点。
考虑到大部分时候ready的不止一个梯度,这种优化还能够同时对多个梯度进行协商,因此实际降低协商的通信量大约一个数量级。
细粒度梯度融合
梯度协商之后,所有节点都知道了当前这个时刻可以进行通信的梯度,接下来面临的一个优化问题是,我们是要在收集到任意数量的梯度之后立刻对所有的梯度进行通信,还是选择某个更优化的组合方式来通信。
这里一个确定性结论是,对单个梯度进行单次通信,通信效率总是非常低下的,我们需要进行多个梯度的融合,然后再对融合后的更大的粒度上进行通信。
AIACC-Training 引入了细粒度的融合策略,我们会在通信环节去动态分析当前的通信状况进而选择一种更平衡的融合策略,避免出现过大的差异。
这样会使得每次通信的粒度尽量均匀,减小出现大幅波动的可能。因为这种融合策略对不同的网络模型而言存在不同的最优值,因此们实现了自动优化的功能,会动态的调整此参数,寻找最优的融合粒度。
异步多流通信
底层的通信库还是采用NCCL来进行GPU间的数据通信,NCCL的编程模型仅支持单一的通信流进行通信,而单一的通信流的效率很低,单流的转发能力往往只能达到10G bps左右。
AIACC-Training从更高的通信引擎层面支持了多流,会分配不止一个通信流来进行梯度通信,每个流服务于切分出来的某个融合梯度,而后续切分的融合粒度并不依赖于当前切分的融合梯度。
因此即使多流之间的通信是完全异步运行,即使多流之间的速度不均衡,也不会严重影响整体的效率,在规模扩大的时候,能更好的维持最佳的网络带宽利用率。
和融合粒度一样,切分的流数,也会和训练模型,以及当前的实际网络带宽有很强的相关性,因此无法离线的给出一个最优设定。
我们设计了自动tuning机制,将通信流数目加入了自动tuning环节,融合粒度以及切分的流数,会联合自动tuning出最佳的参数组合。
模型优化
算法层面的优化主要可以分为数据、模型、超参和优化器四个方面。
数据上,我们采用了多分辨率图像渐进训练。这种方式不仅可以在前期利用小分辨率图像大大提升前后向计算速度、又可以弱化训练和推理时采用不同尺寸带来的准确率损失。
模型上,我们吸收了近期一些网络变体的优势,也根据最新的一些研究对BatchNorm做了微弱的调整。
超参方面我们做了很多探索,如在学习率衰减的方式上,我们没有用很流行的step decay或是cosine decay,而是采用了更直接的linear decay,另外我们也发现warmup的步数非常重要。
优化器上,我们重新设计了优化器方案,同时吸收了SGD的泛化性优势和自适应优化器快速收敛,使得改进后的优化器训练速度更快且准确率更高。
基于上述优化工作,我们在28个epoch 共1159次迭代下完成训练并达到top5 93%的精度要求,而原来训练则需要90个epoch才能达到相同的精度。
性能结果
结合以上所有性能优化,我们在128卡V100上,达到了158秒就能获得top5 93%的精度,创造了新的世界纪录。
刷新推理性能记录:比第二名快5倍以上
在推理项目中,DawnBench竞赛要求推理框架针对ImageNet的10000张图片的验证集进行图片分类,分类模型的top5精度不低于93%。
在batch size=1的配置下,计算推理每一张图片的平均时间和平均成本。在上一个性能纪录中,平均推理时间只有不到1ms,已经远远超过了人类视觉的反应速度。
在最新公布的榜单上,我们基于异构计算AliNPU云服务实例(ecs.ebman1.26xlarge)夺得了推理性能项目的第一名,比第二名快5倍以上。
同时,之前提交的推理成本第一的成绩(基于异构计算GPU云服务实例ecs.gn6i-c8g1.2xlarge)目前还没有人超越,因此在性能和成本两个项目上均排名第一。
AIACC-Inference
在服务客户和不断冲击DawnBench第一的过程中, 我们也在不断打磨异构计算服务场景下的推理优化技术, 并根据客户的实际需求研发了AIACC-Inference模型加速引擎,帮助客户解决主流AI框架TensorFlow、PyTorch、MXNet、Kaldi等框架下的模型优化问题。
优化方法包括对模型的计算图进行分析,将其中计算节点进行融合,减少模型中计算节点的个数,提升计算图的执行效率。
同时提供了FP32和FP16及Int8精度的模型优化选项,可以生成多种精度下的优化模型,其中FP16和Int8精度模型可以利用NVIDIA Volta和Turing架构下的Tensor core硬件支持,进一步提升模型推理在V100, T4 GPU卡上的性能。
目前 AIACC-Inference 既支持常用的图像分类和目标检测模型,也支持Bert,StyleGAN这样的NLP模型和GAN网络模型。
此外,我们还深度优化了1×1、3×3、7×7卷积kernel,在AIACC-Inference中增加了新op的融合机制,比目前业界最快的TensorRT还能获得1.5-2.5倍的性能加速比。
模型与框架优化
在上一次提交的版本中,我们将base模型换为更为精简的ResNet26d,引领了一波风潮。
这一次为了进一步提高模型的精度并精简模型,我们对超参数进行了调整,引入了更多的数据增强方式。通过使用了AugMix和JSD loss叠加RandAugment的组合方式,将ResNet26d模型的精度提升至93.3%,收获0.13+%的精度收益。
基于含光800(AliNPU)的优化
我们针对AliNPU的架构特点,对推理引擎进行了相应的优化。由于AliNPU使用uint8作为存储格式用于上传和下载数据。
因此需要在进入engine前后插入量化和反量化操作用于恢复数据,但是Quant和Dequant这些操作在CPU上,无法使用AliNPU加速,占据了一大部分的推理时间,通过在预处理和后处理中执行这些操作将推理延迟降低至0.117ms的水平。
考虑到我们使用的推理模型较小,依照GPU的经验带宽4GB/s,输入一张图片需要将147KB的数据上传至AliNPU中需要花费0.03ms。因此我们在框架中引入了preload机制,将数据预取入AliNPU中,将平均推理延迟进一步降低至0.0739ms。
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
- 马斯克把超声波雷达也扔掉了!特斯拉再度减配:8摄像头终极传感器方案面世2022-10-05
- iPhone在6人死亡车祸中自动求救,网友:功能很好,但千万别用上2022-10-04
- 渐进派破壁:西有特斯拉,东有毫末智行!用数据智能推动自动驾驶历史进城2022-09-21
- 独家 | 吉利控股集团拟收购图森控股亚太地区业务全部股份,价格暂未公布2022-08-19

相关阅读



600多所高校、13000支队伍参赛,首届全球人工智能技术创新大赛风靡全球
为了推动 AI 技术的应用创新,促进人工智能领域的学术交流、人才培养,打造人工智能的人才交流平台与产业生态圈,中国人工智能学会联合杭州市余杭区人民政府联合发起了首届全球人工智能技术创新大赛,并得到了阿里云、OPPO等头部科技企业的积极参与和支持。阿里云天池平台作为本次大赛的官方竞赛平台,为大赛提供平台和算力支撑。