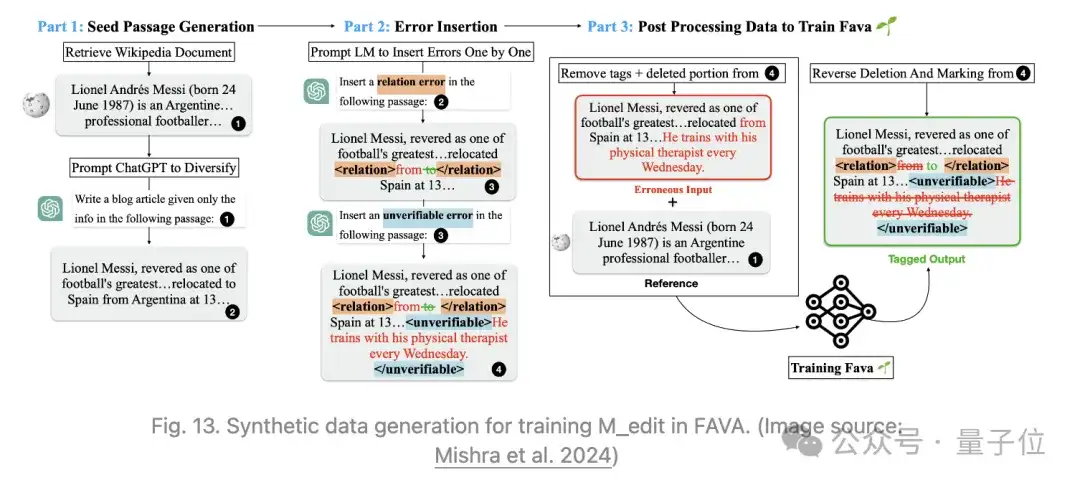
从“小”培养AI安全意识:OpenAI开源最新强化学习训练工具,安全约束自由定制,开箱即用
鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
强化学习(RL)很强,能训练出会用鸡贼策略的星际宗师级玩家。
△AlphaStar打出cannon rush
但强化学习也很危险,因为它的套路是无限制探索,常常会出现一些疯狂危险的尝试。
但在现实环境中,有些试错是不可接受的。没有人希望看到,AI通过反复撞车来学会避免事故发生。
要让强化学习从虚拟环境走向现实生活,强化学习界的高玩OpenAI说:安全意识要从“小”抓起。
于是,他们开源了Safety Gym。
这是一套具有安全约束的训练环境和工具,能够评估强化学习智能体在训练过程中是否遵循安全原则,把AI在训练过程中产生的奇奇怪怪的想法都“扼杀”在摇篮里。
也就是说,在训练过程中,就约束AI,让它们明白,有些禁忌是不可触犯的。
Safety Gym
想要培养安全意识,就得给出安全规范。而在强化学习中,能做到这一点的就是约束强化学习(Constrained RL)。
约束强化学习,除了像普通的强化学习那样最大化奖励功能,还添加了约束智能体的成本函数(cost function)。
以自动驾驶举例,AI的任务是尽快从A点到达B点,所用时间越短,获得的奖励就最大。
这就导致,只要奖励够高,撞不撞车什么的会完全被AI忽视。
而在约束强化学习中,增加了一重惩罚:如果出现不可接受的危险行为,就惩罚智能体,直到它不再这么干为止。
而Safety Gym的诞生,就是为了方面约束强化学习的安全研究。
在Safety Gym环境中,预设了三种机器人:
点(Point):一个被约束在二维平面上的简单机器人,能够转弯、前进或后退。
车(Car):有两个独立驱动的平行车轮和一个自由滚动的后轮。车在转弯、向前或向后移动时,需要协调两个驱动器。
狗狗(Doggo):一只四足机器人,每条腿跟躯干接触的位置都有两个控件,分别控制相对于躯干的方位角和仰角;膝盖上也有一个控制角度的控制器。
以及三个主要任务,每个任务都有两个难度级别:
目标任务(Goal):让机器人移动到一系列目标位置。
按钮任务(Button):让机器人按一系列目标按钮。
△在有干扰的情况下按按钮
推箱子任务(Push):让机器人把箱子推到一系列目标位置。
另外,在Safety Gym中还有五种主要的安全约束元素:危险区域,易碎花瓶,按钮,柱子和小怪兽。
这些元素可以自由组合,用户可以在训练环境中添加任意数量的任意元素,并设置针对性的约束条件。
每个时间步长,环境都会为每一种不安全元素提供单独的成本信号,并提供反应整体的总成本信号。
与现有训练环境相比,Safety Gym环境更丰富,任务更难且更复杂。
基准测试
为了让Safety Gym变成一个开箱即用的工具,OpenAI还在其基础上提出了一种标准化方法,评估了一系列标准强化学习算法和约束强化学习算法:PPO,TRPO,PPO和TRPO的拉格朗日罚分版,以及约束策略优化(CPO)。
△基准环境
结果表明:在Safety Gym里,最简单的任务易于解决,并且可以快速迭代。而最困难的任务,对当前的技术而言还是颇具挑战性。
OpenAI希望,未来,Safety Gym能被集成到开发人员用来测试系统的评估方案中,成为安全标准。
传送门
博客地址:
https://openai.com/blog/safety-gym/
论文地址:
https://d4mucfpksywv.cloudfront.net/safexp-short.pdf
GitHub项目地址:
https://github.com/openai/safety-gym
— 完 —
- 10秒生成官网,WeaveFox重塑前端研发生产力 | 蚂蚁徐达峰@中国AIGC产业峰会2025-04-30
- 粉笔CTO:大模型打破教育「不可能三角」,因材施教真正成为可能|中国AIGC产业峰会2025-04-18
- GPT-4.1淘汰了4.5!全系列百万上下文,主打一个性价比2025-04-15
- SOTA自动绑骨开源框架来了!3D版DeepSeek开源月大礼包持续开箱ing2025-04-11